PRML读书笔记 第十章 近似推断(1)
PRML读书笔记 第十章 近似推断(1)
- 近似推断方法概述
- 一元高斯问题的传统做法和变分推断方法
- 心得体会
从今天起开始更新关于PRML书籍当中的一些学习笔记和感悟心得。目前先从最近所学的部分开始更新,会在未来一段时间当中补更之前的章节所学内容。
这篇文章主要简述一下变分估计方法的作用和基本概念,并详细对比变分近似法下解决线性回归问题和之前的统计方法解决线性问题的异同。
近似推断方法概述
-
近似推断方法的作用
之前我们学习过利用极大似然估计等统计学方法对于各种模型(线性回归模型,混合高斯模型等等)进行处理。利用近似推断的方法其实与之前所使用的方法能够得到类似的结果,然而利用传统方法可能会出现比较难以处理的概率分布,或者参数过多计算复杂度过大的情况。这种时候我们就需要引入近似算法来计算相应的结果。 -
变分法
我理解的变分法的主要思想是把我们所需求的后验概率 p ( Z ∣ X ) \ p\left(Z |X\right) p(Z∣X) 近似为我们变分选择的一个量 q ( Z ) \ q\left(Z \right) q(Z) ,再通过对于 q ( Z ) \ q\left(Z \right) q(Z) 进行一种类似于递归迭代的方法来进行求解。
其在对边缘概率 ln p ( X ) \ln p\left(X \right) lnp(X)进行分解 ln p ( X ) = ζ ( q ) + K L ( q ∣ ∣ p ) \ln p\left(X \right)=\zeta(q)+KL\left(q ||p\right) lnp(X)=ζ(q)+KL(q∣∣p) 的时候使用了KL散度:
K L ( q ∣ ∣ p ) = − ∫ q ( Z ) ln { p ( X , Z ) q ( Z ) } d Z \ KL\left(q ||p\right)=-\int\,q\left(Z \right)\ln\lbrace\frac{p\left(X,Z\right)}{q\left(Z \right)}\rbrace dZ KL(q∣∣p)=−∫q(Z)ln{q(Z)p(X,Z)}dZ
这其中KL散度曾经在VAE模型当中使用过,在VAE模型当中它所起到的作用也是作为我们所需概率分布的重要近似。
分解概率分布的方法是一种比较常用的利用变分法进行计算的方法,也是后续所对比的几种方法中比较常用的。其步骤与EM算法类似,核心是限制
q ( Z ) q\left(\boldsymbol{Z} \right) q(Z)的分布,将Z元素分解成若干个互不相交的组,即 q ( Z ) = ∏ i = 1 M q i ( Z ) q\left(\boldsymbol{Z} \right)=\prod_{i=1}^M q_i\left(\boldsymbol{Z} \right) q(Z)=∏i=1Mqi(Z)
那么对于 ζ ( q ) \zeta(q) ζ(q)有下述变换:
ζ ( q ) = ∫ ∏ i = 1 q i { ln p ( X , Z ) − ∑ k = 1 ln q i } d Z = ∫ q j { ∫ ln p ( X , Z ) ∏ i ≠ j q i d Z j } − ∫ q j ln q j d Z j + 常 数 = ∫ q j ln p ~ ( X , Z ) d Z j − ∫ q j ln q j d Z j + 常 数 \zeta(q)=\int\,\prod_{i=1}q_i\lbrace\ln p(\boldsymbol{X,Z})-\sum_{k=1}\ln q_i\rbrace d\boldsymbol{Z}\\ =\int\,q_j\lbrace\int\,\ln p(\boldsymbol{X,Z})\prod_{i \neq j}q_id\boldsymbol{Z_j}\rbrace-\int\,q_j\ln q_jd\boldsymbol{Z_j}+常数\\ =\int\,q_j\ln \tilde{p}(\boldsymbol{X,Z})d\boldsymbol{Z_j}-\int\,q_j\ln q_jd\boldsymbol{Z_j}+常数 ζ(q)=∫i=1∏qi{lnp(X,Z)−k=1∑lnqi}dZ=∫qj{∫lnp(X,Z)i=j∏qidZj}−∫qjlnqjdZj+常数=∫qjlnp~(X,Z)dZj−∫qjlnqjdZj+常数
这其中我们定义了 ln p ~ ( X , Z ) = E i ≠ j [ ln p ( X , Z ) ] + 常 数 \ln \tilde{p}(\boldsymbol{X,Z})=E_{i\neq j}[\ln p(\boldsymbol{X,Z})]+常数 lnp~(X,Z)=Ei=j[lnp(X,Z)]+常数
而 E i ≠ j [ ln p ( X , Z ) ] = ∫ ln p ( X , Z ) ∏ i ≠ j q i d Z j E_{i\neq j}[\ln p(\boldsymbol{X,Z})]=\int\,\ln p(\boldsymbol{X,Z})\prod_{i \neq j}q_id\boldsymbol{Z_j} Ei=j[lnp(X,Z)]=∫lnp(X,Z)∏i=jqidZj
其中 ln q j ∗ ( Z j ) = E i ≠ j [ ln p ( X , Z ) ] + 常 数 \ln q_j^*(Z_j)=E_{i\neq j}[\ln p(\boldsymbol{X,Z})]+常数 lnqj∗(Zj)=Ei=j[lnp(X,Z)]+常数(此式是日后解决问题的重要公式)
利用上述方法我们可以计算出每一个 q ( Z j ) q(\boldsymbol{Z_j}) q(Zj),从而得到近似 p ( Z ∣ X ) \ p\left(Z |X\right) p(Z∣X) 的结果。
可能上述的方法有一些复杂,理论性比较强,今天我们主要通过讲述一个例子,即一元高斯分布的操作方法,来温习一下之前我们用极大似然估计法的做法,同时也对比一下利用变分估计方法的新的做法。
一元高斯问题的传统做法和变分推断方法
-
所求问题
我们所面对的问题是给定 x \boldsymbol{x} x的观测值 D = { x 1 , x 2 . . . x n } D=\lbrace x_1,x_2...x_n\rbrace D={x1,x2...xn},并且知道其分布满足正态分布的情况下其后验概率所满足的概率分布。(注意:这里所求的是后验概率所满足的概率分布,与数理统计当中简单地利用矩估计或者极大似然估计方法不同,那样只能做点估计或者对置信区间进行估计,而这里要对其概率分布进行估计。) -
统计方法
回顾一下之前利用贝叶斯统计方法,可以利用共轭先验分布来对其进行求解。共轭先验分布的原理是找到有关于参数 θ \theta θ的一个先验分布 π ( θ ) \pi(\theta) π(θ),若有 π ( θ ∣ x ) ∝ p ( x ∣ θ ) π ( θ ) \pi(\theta|x)\propto p(x|\theta)\pi(\theta) π(θ∣x)∝p(x∣θ)π(θ),则称 π ( θ ) \pi(\theta) π(θ)为一个共轭先验分布。利用共轭先验分布的性质我们可以用类似于配方法的办法求得其后验概率分布。
对于方差已知的正态分布,其均值的后验概率分布依然服从正态分布。
假设 π ( θ ) \pi(\theta) π(θ)服从一个 N ( μ , τ 2 ) N(\mu,\tau^2) N(μ,τ2)的正态分布。那么其样本和均值的联合概率分布为: h ( x , θ ) = k 1 e x p { − 1 2 [ n θ 2 − 2 n θ x ˉ + ∑ i = 1 n x i 2 σ 2 + θ 2 − 2 μ θ + μ 2 τ 2 ] } h(x,\theta)=k_1exp\lbrace-\frac{1}{2}[\frac{n\theta^2-2n\theta\bar{x}+\sum_{i=1}^nx_i^2}{\sigma^2}+\frac{\theta^2-2\mu\theta+\mu^2}{\tau^2}]\rbrace h(x,θ)=k1exp{−21[σ2nθ2−2nθxˉ+∑i=1nxi2+τ2θ2−2μθ+μ2]}
我们令 σ 0 2 = σ 2 π \sigma^2_0=\frac{\sigma^2}{\pi} σ02=πσ2, A = 1 σ 0 2 + 1 τ 2 A=\frac{1}{\sigma_0^2}+\frac{1}{\tau^2} A=σ021+τ21, B = x σ 0 2 + μ τ 2 B=\frac{x}{\sigma_0^2}+\frac{\mu}{\tau^2} B=σ02x+τ2μ, C = 1 σ 2 ∑ i = 1 n x i 2 + μ 2 τ 2 C=\frac{1}{\sigma^2}\sum_{i=1}^nx_i^2+\frac{\mu^2}{\tau^2} C=σ21∑i=1nxi2+τ2μ2
由联合概率函数积分可得边缘概率分布: m ( x ) = ∫ − ∞ + ∞ h ( x , θ ) d θ = k 2 ( 2 π A ) 1 2 m(x)=\int_{-\infty}^{+\infty}h(x,\theta)d\theta=k_2(\frac{2\pi}{A})^\frac{1}{2} m(x)=∫−∞+∞h(x,θ)dθ=k2(A2π)21
将上述两式相除即可得到后验概率分布:
π ( θ ∣ x ) = ( 2 π A ) − 1 2 e x p { − ( θ − B / A ) 2 / A } \pi(\theta|x)=(\frac{2\pi}{A})^{-\frac{1}{2}}exp\lbrace-\frac{(\theta-B/A)}{2/A}\rbrace π(θ∣x)=(A2π)−21exp{−2/A(θ−B/A)}
即可得到相关的后验概率分布。
对于已知均值求解方差的情况与此计算过程相同,但更加繁琐了一些 ,其满足一个倒伽马分布。即其先验概率分布 π ( σ 2 ) = λ α Γ ( α ) ( 1 σ 2 ) α + 1 e − λ / σ 2 \pi(\sigma^2)=\frac{\lambda^\alpha}{\Gamma(\alpha)}(\frac{1}{\sigma^2})^{\alpha+1}e^{-\lambda/\sigma^2} π(σ2)=Γ(α)λα(σ21)α+1e−λ/σ2
后验概率 π ( σ 2 ∣ x ) ∝ p ( x ∣ σ 2 ) π ( σ 2 ) \pi(\sigma^2|x)\propto p(x|\sigma^2)\pi(\sigma^2) π(σ2∣x)∝p(x∣σ2)π(σ2)
从上述可以看出,通过统计学方法,得以很轻易的解决这个问题。
- 变分方法
首先按照之前的推导方法,要选择一种概率分布的分解方式,这里最简单的分解方式就是 q ( μ , τ ) = q μ ( μ ) q τ ( τ ) q(\mu,\tau)=q_\mu(\mu)q_\tau(\tau) q(μ,τ)=qμ(μ)qτ(τ)
按照所推导结果 ln q μ ∗ ( μ ) = E τ [ ln p ( D ∣ μ , τ ) + ln p ( μ ∣ τ ) ] + 常 数 = − E [ τ ] 2 { λ 0 ( μ − μ 0 ) 2 + ∑ n = 1 N ( x n − μ ) 2 } + 常 数 \ln q_\mu^*(\mu)=E_\tau[\ln p(D|\mu,\tau)+\ln p(\mu|\tau)]+常数\\ =-\frac{E[\tau]}{2}\lbrace\lambda_0(\mu-\mu_0)^2+\sum_{n=1}^N(x_n-\mu)^2\rbrace+常数 lnqμ∗(μ)=Eτ[lnp(D∣μ,τ)+lnp(μ∣τ)]+常数=−2E[τ]{λ0(μ−μ0)2+n=1∑N(xn−μ)2}+常数
由此我们可以看出 q μ ( μ ) q_\mu(\mu) qμ(μ)也是一个服从均值为 λ 0 μ 0 + N x ˉ λ 0 + N \frac{\lambda_0\mu_0+N\bar{x}}{\lambda_0+N} λ0+Nλ0μ0+Nxˉ,方差为 ( λ 0 + N ) E [ τ ] (\lambda_0+N)E[\tau] (λ0+N)E[τ]
同样对于 q τ ∗ ( τ ) q_\tau^*(\tau) qτ∗(τ)的估计,利用
ln q τ ∗ ( τ ) = E μ [ ln p ( D ∣ μ , τ ) + ln p ( μ ∣ τ ) ] + ln p ( τ ) + 常 数 = ( a 0 − 1 ) ln τ − b 0 τ + N + 1 2 ln τ − τ 2 E μ [ ∑ n = 1 N ( x n − μ ) 2 + λ 0 ( μ − μ 0 ) 2 ] \ln q_\tau^*(\tau)=E_\mu[\ln p(D|\mu,\tau)+\ln p(\mu|\tau)]+\ln p(\tau)+常数\\ =(a_0-1)\ln \tau-b_0\tau+\frac{N+1}{2}\ln\tau-\frac{\tau}{2}E_\mu[\sum_{n=1}^N(x_n-\mu)^2+\lambda_0(\mu-\mu_0)^2] lnqτ∗(τ)=Eμ[lnp(D∣μ,τ)+lnp(μ∣τ)]+lnp(τ)+常数=(a0−1)lnτ−b0τ+2N+1lnτ−2τEμ[n=1∑N(xn−μ)2+λ0(μ−μ0)2]
看出其与统计学推出结果服从相同的分布(我们在上文中统计学方法使用的 σ 2 \sigma^2 σ2是方差,而此处用的 τ \tau τ是精度,其具有倒数的对应关系。故形式相同)
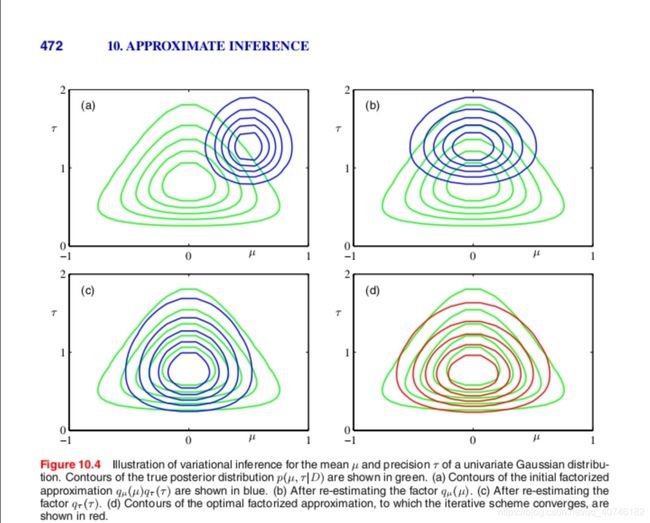
变分方法的后续过程需要对于初始迭代的 E [ μ ] E[\mu] E[μ]或者 E [ τ ] E[\tau] E[τ]先进行一次估计,再利用此初值进行迭代,从PRML的教材的图中可以看到其具有较好的效果。
心得体会
通过简单的例子,对比之前的EM方法等初识了变分法的作用。感觉在计算机数值解数值分析类问题当中,使用迭代的方法似乎一直是要优于直接求解的方法的。
下一篇将会更新EM方法和贝叶斯回归方法与变分法的对比,实际上大部分之前所学的算法都可以利用变分法来找到他的近似解。
顺便也复习了一下之前共轭先验分布当中的部分知识,进一步理解了KL散度在各种应用当中的作用。在撰写这个博客的时候也熟悉了Latex公式编辑~
如果有理解有误希望能够及时指出,也希望能够有同时学这本书的大佬一起讨论指点。