BP神经网络波士顿房价预测
数据集存在表格中
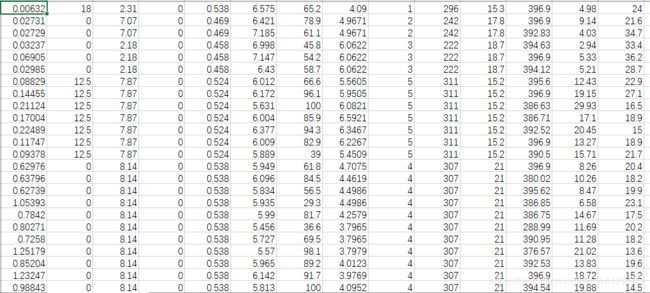
导入数据库
import numpy as np
import tensorflow as tf
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
数据集预处理
data_X = []
data_Y = []
with open('boston_house_prices.csv') as f:
for line in f.readlines():
line = line.split(',')
data_X.append(line[:-1])
data_Y.append(line[-1:])
转换为nparray(浮点型)
data_X = np.array(data_X, dtype='float32')
data_Y = np.array(data_Y, dtype='float32')
检查形状
print('data shape', data_X.shape, data_Y.shape)
print('data_x shape[0]', data_X.shape[1])
归一化
for i in range(data_X.shape[1]):
_min = np.min(data_X[:, i]) #每一列的最小值
_max = np.max(data_X[:, i]) #每一列的最大值
data_X[:, i] = (data_X[:, i] - _min) / (_max - _min) #归一化到0-1之间
分割训练集、测试集
X_train, X_test, y_train, y_test = train_test_split(data_X, # 被划分的样本特征集
data_Y, # 被划分的样本标签
test_size=0.5, # 测试集占比
random_state=0) # 随机数种子,在需要重复试验的时候,保证得到一组一样的随机数,等于0时随机取数据,通过序号
查看训练集、测试集形状
print(X_train.shape)
print(X_test.shape)
定义每个批次大小
batch_size = 1
计算总批次的次数,以便迭代
n_batch = X_train.shape[0] // batch_size
训练次数
max_step =10000
max_step =10000
文件路径
DIR = "D:/PycharmProjects/BostonHousePrices/projector"
参数概要
def variable_summaries(var):
with tf.name_scope("summaries"):
mean = tf.reduce_mean(var)
tf.summary.scalar("mean", mean) # 均值
with tf.name_scope("stddev"):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var-mean)))
tf.summary.scalar("stddev", stddev) # 标准差
tf.summary.scalar("max", tf.reduce_max(var)) # 最大值
tf.summary.scalar("min", tf.reduce_min(var)) # 最小值
tf.summary.histogram("histogram", var) # 直方图
定义一个命名空间
with tf.name_scope("input"):
# 定义两个占位变量
x = tf.placeholder(tf.float32, [None, 13], name="x-input")
y = tf.placeholder(tf.float32, [None, 1], name="y-input")
设置参数设置DROPOUT参数
arg_dropout = tf.placeholder(tf.float32)
定义神经网络
with tf.name_scope("layer"):
# 第一层网络
with tf.name_scope('weight_1'):
weight_1 = tf.Variable(tf.truncated_normal([13, 50], stddev=0.1), name='weight_1')
variable_summaries(weight_1)
with tf.name_scope('bias_1'):
bias_1 = tf.Variable(tf.zeros([50])+0.1, name='bias_1')
variable_summaries(bias_1)
with tf.name_scope('L_1_dropout'):
L_1 = tf.nn.tanh(tf.matmul(x, weight_1)+bias_1)
L_1_dropout = tf.nn.dropout(L_1, arg_dropout)
#第二层网络
with tf.name_scope('weight_2'):
weight_2 = tf.Variable(tf.truncated_normal([50, 300], stddev=0.1), name='weight_2')
variable_summaries(weight_2)
with tf.name_scope('bias_2'):
bias_2 = tf.Variable(tf.zeros([300]) + 0.1, name='bias_2')
variable_summaries(bias_2)
with tf.name_scope('L_2_dropout'):
L_2 = tf.nn.tanh(tf.matmul(L_1_dropout, weight_2) + bias_2)
L_2_dropout = tf.nn.dropout(L_2, arg_dropout)
#第三层网络
with tf.name_scope('weight_3'):
weight_3 = tf.Variable(tf.truncated_normal([300, 50], stddev=0.1), name='weight_3')
variable_summaries(weight_3)
with tf.name_scope('bias_3'):
bias_3 = tf.Variable(tf.zeros([50]) + 0.1, name='bias_3')
variable_summaries(bias_3)
with tf.name_scope('L_3_dropout'):
L_3 = tf.nn.tanh(tf.matmul(L_2_dropout, weight_3) + bias_3)
L_3_dropout = tf.nn.dropout(L_3, arg_dropout)
with tf.name_scope("output"):
# 创建最后一层神经网络
with tf.name_scope('weight'):
weight = tf.Variable(tf.truncated_normal([50, 1], stddev=0.1), name='weight')
variable_summaries(weight)
with tf.name_scope('bias'):
bias = tf.Variable(tf.zeros([1])+0.1, name='bias')
variable_summaries(bias)
with tf.name_scope('prediction'):
prediction = tf.matmul(L_3_dropout, weight) + bias
with tf.name_scope("loss"):
# 方法一:二次代价函数
loss = tf.reduce_mean(tf.square(prediction - y))
# 方法二:交叉墒
# loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
tf.summary.scalar("loss", loss)
adam梯度下降方式最小化代价函数
train = tf.train.AdamOptimizer(1e-4).minimize(loss)
合并所有的summary标量
merged = tf.summary.merge_all()
训练、测试
#如何从数据集拿取数据
def get_Batch(image, label, batch_size, now_batch, total_batch):
if now_batch < total_batch:
x_batch = image[now_batch*batch_size:(now_batch+1)*batch_size]
y_batch = label[now_batch*batch_size:(now_batch+1)*batch_size]
else:
x_batch = image[now_batch*batch_size:]
y_batch = label[now_batch*batch_size:]
return x_batch, y_batch
#创建会话
with tf.Session() as sess:
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
write = tf.summary.FileWriter("logs/", sess.graph)
for epoch in range(max_step):
train_loss_list = []
for batch in range(n_batch):
batch_xs, batch_ys = get_Batch(X_train, y_train, 1, batch, n_batch)
summary, _ , train_loss = sess.run([merged, train, loss], feed_dict={x: batch_xs, y: batch_ys, arg_dropout: 0.5})
train_loss_list.append(train_loss)
write.add_summary(summary, epoch)
if epoch % 100 == 0:
print('epoch ' + str(epoch) + ' train_loss ' + str(np.mean(train_loss_list)))
#test
test_loss_list = []
pre = []
true = []
for batch1 in range(n_batch):
batch_xss, batch_yss = get_Batch(X_test, y_test, 1, batch1, n_batch)
test_pre, test_loss = sess.run([prediction, loss], feed_dict={x: batch_xss, y: batch_yss, arg_dropout: 1.0})
test_loss_list.append(test_loss)
true.append(batch_yss[0][0])
pre.append(test_pre[0][0])
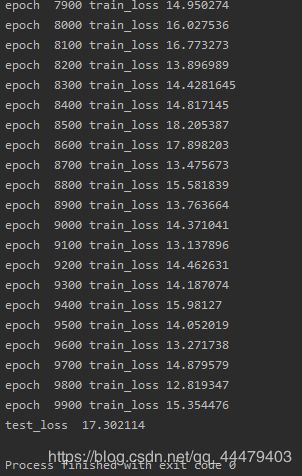
print('test_loss ' + str(np.mean(test_loss_list)))
#画图
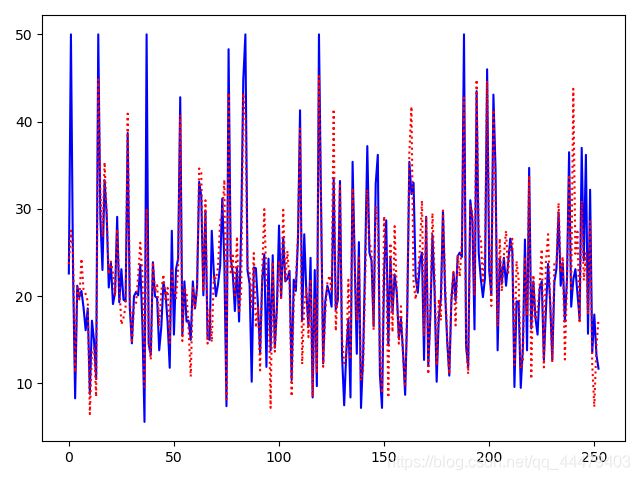
plt.plot(range(n_batch), true, 'b-')
plt.plot(range(n_batch), pre, 'r:')
plt.savefig('./test2.jpg')
plt.show()
saver.save(sess, DIR+"/projector/a_model_ckpt", global_step=max_step)
write.close()
部分输出结果:
真实值与预测值对比:
项目源代码获取请点击这里