文章目录
- 一原生查询偏移量
- 二 Druid数据库连接池
- 三 在mysql中创建对应的偏移量表
- 四 获取mysql中的偏移量
- 五维护偏移量至mysql
- 六 获取kafka Dstream
- 七 测试代码
- 八查看mysql中的结果数据
一原生查询偏移量
val driver = "com.mysql.jdbc.Driver"
val url = "jdbc:mysql://aliyun01:3306/kafka"
val userName = "root"
val passWd = "root"
def getOffsetFromMysql(groupId:String,topicName:String): util.Map[TopicPartition, java.lang.Long] = {
Class.forName(driver)
val conn: Connection = DriverManager.getConnection(url, userName, passWd)
val sql="select `groupid`,`topic`,`partition`,`untiloffset` from offset_manager where groupid=? and topic=?"
val pre = conn.prepareStatement(sql)
pre.setString(1,s"${groupId}")
pre.setString(2,s"${topicName}")
val resultSet: ResultSet = pre.executeQuery()
val resMap: util.Map[TopicPartition, java.lang.Long] = new util.HashMap[TopicPartition,java.lang.Long]()
while(resultSet.next()){
val topicPartition: TopicPartition = new TopicPartition(resultSet.getString("topic"),resultSet.getInt("partition"))
resMap .put(topicPartition,resultSet.getString("untiloffset").toLong)
}
resMap
}
二 Druid数据库连接池
object SqlDataSource extends Serializable {
val pro: Properties = new Properties();
pro.setProperty("url","jdbc:mysql://aliyun01:3306/kafka")
pro.setProperty("username", "root" )
pro.setProperty("password", "root" )
pro.setProperty("filters", "stat" )
pro.setProperty("maxActive", "20" )
pro.setProperty("initialSize" ,"1" )
pro.setProperty("maxWait", "60000" )
pro.setProperty("minIdle" ,"1" )
pro.setProperty("timeBetweenEvictionRunsMillis", "60000" )
pro.setProperty("minEvictableIdleTimeMillis", "300000" )
pro.setProperty("testWhileIdle", "true" )
pro.setProperty("testOnBorrow" ,"false" )
pro.setProperty("testOnReturn" ,"false" )
pro.setProperty("poolPreparedStatements", "true" )
pro.setProperty("maxOpenPreparedStatements", "20" )
pro.setProperty("asyncInit" ,"true" )
pro.setProperty("driverClassName", "com.mysql.jdbc.Driver");
import com.alibaba.druid.pool.DruidDataSourceFactory
private val dataSource: DataSource = DruidDataSourceFactory.createDataSource(pro)
def getConnection() ={
dataSource.getConnection
}
def SqlDataSource(resultSet: ResultSet, preparedStatement: PreparedStatement, connection: Connection) {
closeResultSet(resultSet)
closePrepareStatement(preparedStatement)
closeConnection(connection)
}
import java.sql.PreparedStatement
import java.sql.ResultSet
import java.sql.SQLException
def closeConnection(connection: Connection): Unit = {
if (connection != null) try
connection.close
catch {
case e: SQLException =>
e.printStackTrace()
}
}
def closePrepareStatement(preparedStatement: PreparedStatement): Unit = {
if (preparedStatement != null) try
preparedStatement.close()
catch {
case e: SQLException =>
e.printStackTrace()
}
}
def closeResultSet(resultSet: ResultSet): Unit = {
if (resultSet != null) try
resultSet.close()
catch {
case e: SQLException =>
e.printStackTrace()
}
}
}
三 在mysql中创建对应的偏移量表
CREATE TABLE `offset_manager` (
`groupid` varchar(50) DEFAULT NULL,
`topic` varchar(50) DEFAULT NULL,
`partition` int(11) DEFAULT NULL,
`untiloffset` mediumtext,
UNIQUE KEY `offset_unique` (`groupid`,`topic`,`partition`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
四 获取mysql中的偏移量
def getOffsetFromMysql(groupId:String,topicName:String): util.Map[TopicPartition, java.lang.Long] = {
val conn = SqlDataSource.getConnection()
val sql="select `groupid`,`topic`,`partition`,`untiloffset` from offset_manager where groupid=? and topic=?"
val pre = conn.prepareStatement(sql)
pre.setString(1,s"${groupId}")
pre.setString(2,s"${topicName}")
val resultSet: ResultSet = pre.executeQuery()
val resMap: util.Map[TopicPartition, java.lang.Long] = new util.HashMap[TopicPartition,java.lang.Long]()
while(resultSet.next()){
val topicPartition: TopicPartition = new TopicPartition(resultSet.getString("topic"),resultSet.getInt("partition"))
resMap .put(topicPartition,resultSet.getString("untiloffset").toLong)
}
SqlDataSource.closeResultSet(resultSet)
SqlDataSource.closePrepareStatement(pre)
SqlDataSource.closeConnection(conn)
resMap
}
}
五维护偏移量至mysql
def updateOffset(kafkaDataDstream:InputDStream[ConsumerRecord[String, String]],groupId:String)={
kafkaDataDstream.foreachRDD(rdd=>{
val conn = SqlDataSource.getConnection()
val sql: String ="replace into `offset_manager` (groupid,topic,`partition`,untilOffset) values(?,?,?,?)"
val pre: PreparedStatement = conn.prepareStatement(sql)
conn.setAutoCommit(false)
val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
for(offset <-offsetRanges){
val partition = offset.partition
val topic = offset.topic
val endOffset = offset.untilOffset
pre.setString(1,groupId);
pre.setString(2,topic);
pre.setInt(3,partition);
pre.setString(4,endOffset.toString)
pre.addBatch()
}
pre.executeBatch()
conn.commit()
SqlDataSource.closePrepareStatement(pre)
SqlDataSource.closeConnection(conn);
})
}
六 获取kafka Dstream
def getKafkaDstream(ssc: StreamingContext,topic:String,groupId:String,boker_list:String,isAutoCommit:Boolean): InputDStream[ConsumerRecord[String, String]] ={
import scala.collection.JavaConversions._
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> s"${boker_list}",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> s"${groupId}",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> s"${isAutoCommit}"
)
var fromOffsets: util.Map[TopicPartition, java.lang.Long] =new util.HashMap[TopicPartition, java.lang.Long]();
val topics = Seq(s"${topic}")
if(!isAutoCommit){
fromOffsets = getOffsetFromMysql(s"${groupId}", s"${topic}")
}
if(fromOffsets==null || fromOffsets.isEmpty ){
KafkaUtils.createDirectStream[String,String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String,String](topics, kafkaParams)
)
}else{
KafkaUtils.createDirectStream[String,String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies Subscribe[String, String](topics, kafkaParams, fromOffsets)
)
}
}
七 测试代码
package com.gc.zt
import org.apache.kafka.clients.consumer.ConsumerRecord
import com.gc.util.{KafkaUtil}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object ZTCountApp {
def main(args: Array[String]): Unit = {
val groupId ="gc1111";
val conf = new SparkConf().setMaster("local[*]").setAppName("RegisterUserApp")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.set("spark.streaming.kafka.maxRatePerPartition","100")
val ssc: StreamingContext = new StreamingContext(conf,Seconds(3))
val kafkaDataDstream: InputDStream[ConsumerRecord[String, String]] = KafkaUtil.getKafkaDstream(ssc,"qz_log",s"${groupId}","aliyun01:9092,aliyun02:9092,aliyun03:9092",false);
val sd: DStream[String] = kafkaDataDstream.mapPartitions(
it => {
it.map(data => data.value())
}
)
sd.cache()
val changeDS: DStream[((String, String, String), (String, String, String))] = sd.map(line => {
val dataArray = line.split("\t")
((dataArray(0), dataArray(1), dataArray(2)), (dataArray(3), dataArray(4), dataArray(5)))
})
changeDS.cache()
changeDS.mapPartitions(it=>{
val map: mutable.Map[((String, String, String), (String, String, String)), Null] = new mutable.HashMap[((String, String, String), (String, String, String)),Null]()
it.foreach(data=>{
map += data->null
})
map.map(_._1).toList.iterator
})
.mapPartitions(
it=>{
it.map(data=>{(data._1,1)})
}
).reduceByKey(_+_).print(100)
KafkaUtil.updateOffset(kafkaDataDstream,s"${groupId}")
ssc.start()
ssc.awaitTermination()
}
}
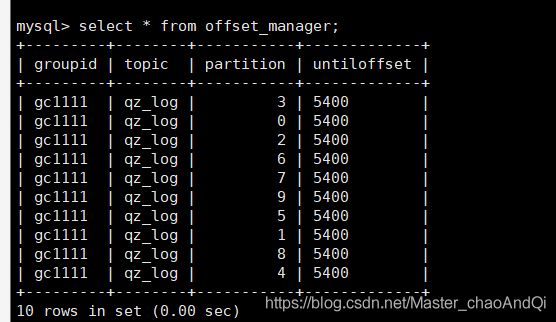
八查看mysql中的结果数据