java—进阶知识复习---部分
进阶知识
- 1.1-final关键字
- 1.2-抽象和接口
- 1.3-访问修饰符
- 1.4-hashCoDEequals()方法
- finalize方法
- 深克隆和浅克隆
- 1.5-内部类
- 匿名内部类
- 1.6-数组
- 基本概念
- 一维数组的静态初始化和动态初始化
- 数组的扩容机制
- 常见的几种算法
- 冒泡排序
- 二分法查找(折半查找)
- 使用API排序和查找
- 1.7-常用类
- String类
- StringBuffer/StringBuilder类
- 1.8-基本类和包装类
- 自动装箱和自动拆箱
- 1.10-对日期的处理
- 日期类
- 数字类
1.1-final关键字
1、final修饰的类无法继承。
2、final修饰的方法无法覆盖。
3、final修饰的变量只能赋一次值。
4、final修饰的引用一旦指向某个对象,则不能再重新指向其它对象,但该引用指向的对象内部的数据是可以修改的。
5、final修饰的实例变量必须手动初始化,不能采用系统默认值。
6、final修饰的实例变量一般和static联合使用,称为常量。
public static final double PI = 3.1415926;
1.2-抽象和接口
抽象类(既然是类就应该是继承不是实现)
第一:抽象类怎么定义?在class前添加abstract关键字就行了。
第二:抽象类是无法实例化的,无法创建对象的,所以抽象类是用来被子类继承的。
第三:final 和 abstract 不能联合使用,这两个关键字是对立的。
第四:抽象类的子类可以是抽象类。也可以是非抽象类。
第五:抽象类虽然无法实例化,但是抽象类有构造方法,这个构造方法是供子类使用的。
第六:抽象类中不一定有抽象方法,可以有普通方法,抽象方法必须出现在抽象类中。
第七:抽象方法怎么定义?
public abstract void doSome();
1.3-访问修饰符
| 访问控制修饰符 | 本类 | 同包 | 子类 | 任意位置 |
|---|---|---|---|---|
| public | 可以 | 可以 | 可以 | 可以 |
| protected | 可以 | 可以 | 可以 | 不可以 |
| 默认 | 可以 | 可以 | 不可以 | 不可以 |
| private | 可以 | 不可以 | 不可以 | 不可以 |
1.4-hashCoDEequals()方法
以后所有类的equals方法也需要重写,因为Object中的equals方法比较
的是两个对象的内存地址,我们应该比较内容,所以需要重写。
重写规则:自己定,主要看是什么和什么相等时表示两个对象相等。
基本数据类型比较实用:==
对象和对象比较:调用equals方法
String类是SUN编写的,所以String类的equals方法重写了。以后判断两个字符串是否相等,最好不要使用==,要调用字符串对象的equals方法。
注意:重写equals方法的时候要彻底。 如何彻底:成员变量中 存在我们自己创建的类,那么这个类的equals也要重写。
public native int hashCode()
native 修饰符 底层调用了C++程序
hashCode返回的一个哈希值:通过一个实例对象的内存地址、经过哈希算法得到一个值,所以这个值等同于一个的内存地址
finalize方法
1.在object类中的源代码:
protected void finalize ()throws Throwable { }
GC:负责调用finalize()方法。|
2、finalize()方法只有一一个方法体,里面没有代码,而且这个方法是protected修饰的。
3、这个方法不需要程序员手动调用,JVM的垃圾回收器负责调用这个方法。
不像equals tostring, equals和toString ()方法是需要你写代码调用的。
finalize()只需要重写,重写完将来自动会有程序来调用。
4、finalize ()方法的执行时机:
当一个java对象即将被垃圾回收器回收的时候,垃圾回收器负责调用
finalize()方法。
5- finalize ()方法实际上是sUN公司为java程序员准备的一一个时机,垃圾销毁时机。
如果希望在对象销毁时机执行一段代码的话,这段代码要写到finalize()方法当中。
6、静态代码块的作用是什么?
static {
静态代码块在类加载时刻执行,并且只执行一- 次. .
这是一一个sUN准备的类加载时机.
finalize()方法同样也是SUN为程序员准备的一-个时机。
这个时机是垃圾回收时机.
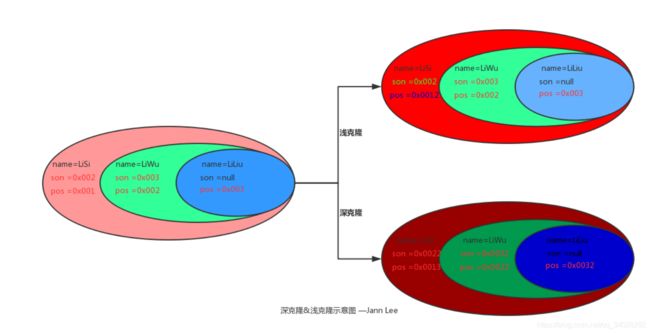
深克隆和浅克隆
这里的笔记取到的是百度一位博主的觉得描述得比较清晰就记录了下来、如有不当、可联系删除。
浅克隆:创建一个新对象,新对象的属性和原来对象完全相同,对于非基本类型属性,仍指向原有属性所指向的对象的内存地址。
深克隆:创建一个新对象,属性中引用的其他对象也会被克隆,不再指向原有对象地址。
总之深浅克隆都会在堆中新分配一块区域,区别在于对象属性引用的对象是否需要进行克隆(递归性的)。
图解如下
1.5-内部类
局部内部类:类似于局部变量
静态内部类:类似于静态变量
实例内部类:类似于成员变量
匿名内部类
匿名内部类是局部内部类中的一种,没有名称而叫匿名内部类。(缺点,复杂、不可重复使用)
接口写法

方法调用(add方法调用了接口中的方法、 main方法中使用add中传入 接口并实现)

1.6-数组
基本概念
数组 可以存放基本数据类型也可以存放 引用数据类型。
例如:
int[] array1 ={100,5,22,56,1,10};
Person[] array2 = new Person[2]
array2[0] = new Person();
array2[1] = new Person();
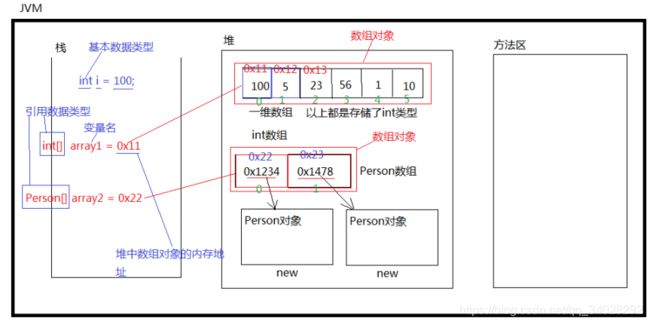
数组的优点和缺点和特点
特点:数组在存储空间上是一块连续的内存空间,并且首地址是已知的,而且每个元素占用的空间是大小是一样的。
优点:由于存储空间上是一块连续的内存地址、而且首地址已知,就可以通过首地址和目标地址的下标计算出所在下标的偏移量,从而得到目标的内存地址,所以在查找和修改效率非常高。
缺点 :因为数组规定是一块连续的内存空间,而在内存空间上无法找到一块连续并且很大的内存空间,所以数组无法储存大数据量,而且如果不是在最后一个元素进行删除和添加的话,会造成元素的向前移动和向后移动,效率低 。
一维数组的静态初始化和动态初始化
静态初始化:
int[] arr = {1,2,3,4};
Object[] objs = {new Object(), new Object(), new Object()};
动态初始化
int[] arr = new int[4]; // 4个长度,每个元素默认值0
Object[] objs = new Object[4]; // 4个长度,每个元素默认值null
数组的扩容机制
数组长度不够的时候,需要扩容,扩容的机制是:新建一个大数组,
将小数组中的数据拷贝到大数组,然后小数组对象被垃圾回收。
如果元素的个数,大于其容量,则把其容量扩展为原来容量的1.5倍。
//设置默认长度是10
int[] sources = {1,2,3,4,5,6,7,8,9,10};
//扩展到1.5倍
int[] newSources = new int[(sources.length/2)+sources.length];
//拷贝 源 下标 目标 下标
System.arraycopy(sources,0,newSources,0,sources.length);
//遍历
for (int i = 0; i < newSources.length; i ++){
System.out.println(newSources[i]);
}
数组的扩容效率比较低、因为涉及数据的拷贝。
常见的几种算法
选择排序法
选择排序比冒泡排序的效率高。
高在交换位置的次数上。
选择排序的交换位置是有意义的。
循环一次,然后找出参加比较的这堆数据中最小的,拿着这个最小的值和
最前面的数据“交换位置”。
参与比较的数据:3 1 6 2 5 (这一堆参加比较的数据中最左边的元素下标是0)
第1次循环之后的结果是:
1 3 6 2 5
参与比较的数据:3 6 2 5 (这一堆参加比较的数据中最左边的元素下标是1)
第2次循环之后的结果是:
2 6 3 5
参与比较的数据:6 3 5 (这一堆参加比较的数据中最左边的元素下标是2)
第3次循环之后的结果是:
3 6 5
参与比较的数据:6 5 (这一堆参加比较的数据中最左边的元素下标是3)
第4次循环之后的结果是:
5 6
注意:5条数据,循环4次。
实例代码如下
// 数组的初始值是从小到大 利用选择排序将数组变成从大到小
int[] sort = {1,2,3,4,5,6,7,8,9,10};
// 进行交换的次数最大是 sort.length = 10次
for (int i = 0; i< sort.length; i++){
// 猜测当前下标所在的元素是最大值
int max = i;
// 遍历查找最大值 每次变量从没有找到最大值的下标开始
// 比如这次数据的最大值是10 我已经找到并且把10放到第一位 那么我下一次就从第二次开始比较
for (int j = i+1; j<sort.length; j++){
if (sort[j]>sort[i]){
max = j;
}
}
// 如果最大值和我们猜测的一样就不用比较 反正就交换位置
if (i!=max){
int temp = sort[i];
sort[i] = sort[max];
sort[max] = temp;
}
}
for (int i = 0; i< sort.length; i++){
System.out.println(sort[i]);
}
输出结果 10 9 8 7 6 5 4 3 2 1
冒泡排序
// n 条数据比 n-1 次
for(int i = length-1; i > 0; i–){
for(int j = 0; j < length-1-i; j++){
比较条件代码块
}
}
如果是从小到大就是找到最大的数据放在最右边
如果是从大到小就是找到最小的数据放在最右边
二分法查找(折半查找)
第一:二分法查找建立在排序的基础之上。(有序的数组之上)
第二:二分法查找效率要高于“一个挨着一个”的这种查找方式。
第三:二分法查找原理?
10(0下标) 23 56 89 100 111 222 235 500 600(下标9) arr数组
目标:找出600的下标
(0 + 9) / 2 --> 4(中间元素的下标)
arr[4]这个元素就是中间元素:arr[4]是 100
100 < 600
说明被查找的元素在100的右边。
那么此时开始下标变成:4 + 1
(5 + 9) / 2 --> 7(中间元素的下标)
arr[7] 对应的是:235
235 < 600
说明被查找的元素在235的右边。
开始下标又进行了转变:7 + 1
(8 + 9) / 2 --> 8
arr[8] --> 500
500 < 600
开始元素的下标又发生了变化:8 + 1
(9 + 9) / 2 --> 9
arr[9]是600,正好和600相等,此时找到了。二分法查找(折半查找):
代码实现如下
int[] sortB = {1,2,3,4,5,6,7,8,9,10};
//查找的次数
int sumB = 0;
//要查找的元素
int fundB = 8;
for (int i = 0; i< sort.length; i++){
//中间元素下标
int k = (sortA.length-1)/2;
//如果这个区间中间元素是就找到不是就缩小区间
if (sort[i] == fund){
System.out.println("找到了");
break;
}
if (sortA[i]<fund){
k = k+1 + (sortA.length-1);
}else {
k = k/2-1;
}
//记录查找的次数
sum++;
}
// 输出 sum = 2
System.out.println("一个查找了"+sum+"次");
使用API排序和查找
//整形数组 sortA进行从小到大的排序
Arrays.sort(sortA);
//返回下标 如果没有就是 -11
int i = Arrays.binarySearch(sortA, 5);
System.out.println(i);
1.7-常用类
String类
对String在内存存储方面的理解:
第一:字符串一旦创建不可变。
第二:双引号括起来的字符串存储在字符串常量池中。
第三:字符串的比较必须使用equals方法。
第四:String已经重写了toString()和equals()方法。
//实际上这里在方法区的常量池里面有三个常量 abc def abcdef
String s1 = “abdefc”;
String s2 = “abdefc” +“xy”;
//而 String s3 = new String(“xy”)

//关于user对象中的成员变量中存在String 类型的
String name
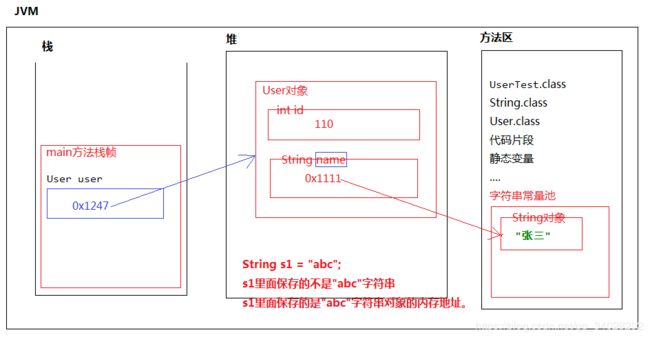
// i变量中保存的是100这个值。
int i = 100;
// s变量中保存的是字符串对象的内存地址。
// s引用中保存的不是"abc" ,是0x1111
//而0x1111 是"abc”字符串对象在“字符串常量池当中的内存地址。
String s = “abc”;
StringBuffer/StringBuilder类
在String类中使用 + 大量拼接字符串会导致方法区里的常量池有大量的常量,
浪费内存空间所以引入了StringBuffer,StringBuffer的底层是byte数组(字符串缓冲对象),
初始化容量是16,并且内部有自动扩容位 2倍+2
源码如下
/**
* This implements the expansion semantics of ensureCapacity with no
* size check or synchronization.
*/
void expandCapacity(int minimumCapacity) {
int newCapacity = value.length * 2 + 2;
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
value = Arrays.copyOf(value, newCapacity);
}
如果去优化StringBuffer?
在创建StringBuffer的时候给定一个合适的初始化容量,减少扩容的次数。
如何的去拼接?
使用append(数据)
关于StringBuffer和StringBuilder的区别?
StringBuffer是线程安全的。StringBuilder是非线程安全的
也就是说StringBuffer的方法带有 synchronized
关键字修饰表示StringBuffer在多线程环境下运行是安全的。
1.8-基本类和包装类
1.包装类型可以为 null,而基本类型不可以
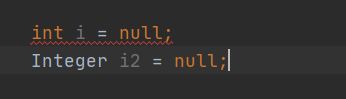
2.包装类型可用于泛型,而基本类型不可以
也就是说基本数据类型不可为null,而引用数据类型就可以
3.基本类型比包装类型更高效
基本类型在栈中直接存储的具体数值,而包装类型则存储的是堆中的引用
4、包装类比较其内容用equals而不是==、用==表示比较内存地址、而且用包装类就表示 new 了两个对象出来比较
在堆内存中有两个对象、必然内存地址不相同、用 equals 则是包装内重写了equals方法 例如Integer
源码如下
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}
实际上也就是基本类的 ==
示例代码
public static void main(String[] args) {
String s = new String("10");
String s2 = new String("10");
Integer integer = new Integer(10);
Integer integer2 = new Integer(10);
Double aDouble = new Double(10.00);
Double aDouble2 = new Double(10.00);
// false
System.out.println(s==s2);
// true
System.out.println(s.equals(s2));
// false
System.out.println(integer==integer2);
// true
System.out.println(integer.equals(integer2));
// false
System.out.println(aDouble2==aDouble);
// true
System.out.println(aDouble.equals(aDouble2));
}
自动装箱和自动拆箱
自动装箱
将基本数据类型转换位引用数据类型
Integer x = 1500;
自动拆箱
将引用数据类型转换位基本数据类型
int y = x;
1.10-对日期的处理
日期类
2.1、获取系统当前时间
Date d = new Date();
2.2、日期格式化:Date --> String
yyyy-MM-dd HH:mm:ss SSS
SimpleDateFormat sdf = new SimpleDate(“yyyy-MM-dd HH:mm:ss SSS”);
yyyy-MM-dd HH:mm:ss
SimpleDateFormat sdf2 = new SimpleDate("yyyy-MM-dd HH:mm:ss ");
String s = sdf.format(new Date());
String s = sdf2.format(new Date());
2.3、String --> Date
SimpleDateFormat sdf = new SimpleDate(“yyyy-MM-dd HH:mm:ss”);
Date d = sdf.parse(“2008-08-08 08:08:08”);
2.4、获取毫秒数
long begin = System.currentTimeMillis();
Date d = new Date(begin - 1000 * 60 * 60 * 24);
数字类
3.1、DecimalFormat数字格式化
###,###.## 表示加入千分位,保留两个小数。
###,###.0000 表示加入千分位,保留4个小数,不够补0
3.2、BigDecimal
财务软件中通常使用BigDecimal