论文笔记
AlexNet原理及trick
一、网络结构:
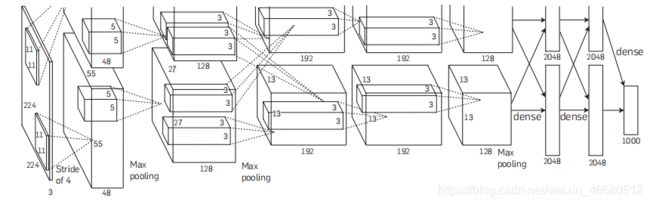
整个网络一共有8个需要训练的层——5层卷积层和3层全连接层
下面来讨论下这些层
conv_1
- 输入层大小为224×224×3的图像
- 使用两个大小为11 × 11 × 3 × 48的卷积核,步长s = 4,如果按照无padding的方式,按照公式应该是 ⌈ 224 − 11 + 1 4 ⌉ = 54 \lceil\frac{224-11+1}{4}\rceil=54 ⌈4224−11+1⌉=54输出的尺寸应该是54×54
而论文里的输出是55*55,我认为这里有两种解释:
(1)输入图片的尺寸给错了,应该是227×227, ⌈ 227 − 11 + 1 4 ⌉ = 55 \lceil\frac{227-11+1}{4}\rceil=55 ⌈4227−11+1⌉=55
(2)这里用的padding=SAME的方式,零填充p=3, 224 + 2 ∗ 3 − 11 + 1 4 = 55 \frac{224+2*3-11+1}{4}=55 4224+2∗3−11+1=55
\quad 96个卷积核,故得到两个大小为55 × 55 × 48的feature map
- 卷积层后跟ReLU,同时后面跟LRN层,尺寸不变
- 然后跟着Max pooling层,使用大小为3×3,stride=2的最大汇聚操作,得到 两 个 \color{red}{两个} 两个大小为27×27×48的feature map, ⌈ 55 − 3 + 1 2 ⌉ = 27 \lceil\frac{55-3+1}{2}\rceil=27 ⌈255−3+1⌉=27
conv_2
- 输入的为27×27×96,使用两个大小为5×5×48×128的 卷积核,stride=1 ,依旧是padding=SAME的方式,零填充p=2, 27 + 2 ∗ 2 − 5 + 1 1 = 27 \frac{27+2*2-5+1}{1}=27 127+2∗2−5+1=27,得到 两 个 \color{red}{两个} 两个大小为27×27×128的feature map
- 同样紧跟ReLU,和LRN层.尺寸不变,
然后跟着Max pooling层,使用大小为3×3,stride=2的最大汇聚操作,得到 两 个 \color{red}{两个} 两个大小为13×13×128的feature map, ⌈ 27 − 3 + 1 2 = 13 ⌉ \lceil\frac{27-3+1}{2}=13\rceil ⌈227−3+1=13⌉
conv_3
第三个卷积层为两个路径的融合
- 输入的是13×13×256,使用一个大小为 3 × 3 × 256 × 384的卷积核,stride=1,零填充p=1, 13 + 2 ∗ 1 − 3 + 1 1 = 13 \frac{13+2*1-3+1}{1}=13 113+2∗1−3+1=13,得到 两 个 \color{red}{两个} 两个大小为13 × 13 × 192的feature map
- 同样加上ReLU,尺寸不变
- 无Max Pooling层
conv_4
- 输入的是13×13×384
使用两个大小为 3 × 3 × 192 × 192的卷积核,stride = 1,零填充p = 1,得到两个大小为13 × 13 × 192的feature map - 同样加上ReLU,尺寸不变
- 无Max Pooling层
conv_5
- 输入的是13 × 13 × 384,使用两个大小为3 × 3 × 192 × 128的卷积核,stride = 1,零填充p = 1,得到两个大小为13 × 13 × 128的feature map
- 同样加上ReLU,尺寸不变
- 然后跟着Max Pooling层,使用大小为 3 × 3 ,stride= 2的最大汇聚操作,得到两个大小为6 × 6 × 128的feature map
在讲全连接层之前,先好好了解一下什么是全连接层 \textbf{在讲全连接层之前,先好好了解一下什么是全连接层} 在讲全连接层之前,先好好了解一下什么是全连接层
下面这个我觉得讲的挺好的,清晰易懂!
第一个是知乎大佬讲的,特别明白!
https://zhuanlan.zhihu.com/p/33841176
第二个就截个图过来吧,这种理解也很助于消化
fc_1
- 由于上一层得到的输出是6×6×256,所以要获得4096×1的vector的话,需要用一个6x6x256x4096的卷积核去卷积激活函数的输出,而这个实现全连接运算过程的操作是全局卷积
好的卷积完之后就能得到一个有4096个元素的vector了 - 依旧ReLU,尺寸不变
fc_2
这一层的输出也是具有4096个元素的vector,在加上ReLU后,尺寸不变
fc_3
这一层的输出是具有1000个元素的vector,也就是那1000个分类的概率啦,
最后应用softmax就可以得出分类结果啦
二、Alexnet中的trick
AlexNet将CNN用到了更深更宽的网络中,其效果分类的精度更高相比于以前的LeNet
1.ReLU的选用
在选用激活函数时,Alexnet选用的ReLU(非饱和非线性函数)来代替传统激活函数(sigmoid及tanh,这两种是饱和线性函数),使模型能够更快收敛,也就代表着更快的训练,同时解决sigmoid在训练较深的网络中出现的梯度消失,或者说梯度弥散的问题。
饱和神经元和非饱和神经元解释: \textbf{饱和神经元和非饱和神经元解释:} 饱和神经元和非饱和神经元解释:
直观理解:激活函数是否会压缩输入值,饱和激活函数会压缩输入值
定义:
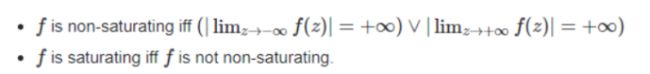
举例:
(1)RELU激活函数f(x)=max(0,x),当x→+∞时,f(x)→+∞,故该函数为非饱和
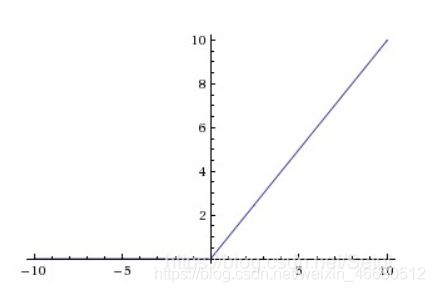
(2)sigmoid函数的范围是[0,1],所以是饱和的
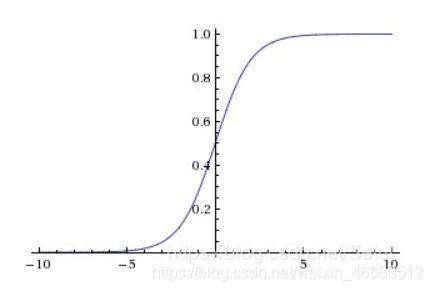
(3)tanh函数的范围是[-1,1],故也是饱和的

问题:为什么要用ReLU这样的能生成non-saturing neurons的non-linear activations,而不用能生成saturing neurons的sigmoid和tanh?
答:避免梯度消失和梯度爆炸带来的gradient值过大过小,导致训练效率低下
梯度消失和爆炸详情参考:https://www.jianshu.com/p/3f35e555d5ba
2.多GPU训练
在论文中可以看出,两个网络时并行的,但这并不意味着Alexnet是并行结构的,只是每个GPU上并行地、分别地运行AlexNet的一部分,两块GPU只在特定的层上有交互,至于为什么要这样是因为当时的GTX580只有3GB的显存,不足以容纳该网络最大的模型,而且这样也能加速神经网络的训练。
3.重叠的最大池化层
在以前的CNN中普遍使用平均池化层,AlexNet全部使用最大池化层,避免了平均池化层的模糊化的效果,并且步长比池化的核的尺寸小,这样池化层的输出之间有重叠,提升了特征的丰富性。
4.减轻过拟合
在论文中有两种减轻过拟合的方式
(1)数据增强的两种方式:
\quad 1)从256×256的图像中随机截取224×224的部分出来
\quad 训练时,取出所有的patch以及它们的水平对称结果,这种操作将整个数据集放大了2048倍,为什么是2048倍呢?因为在vertical和horizontal两个方向上,各有32个位置可以进行crop,也就是32×32个patches。还有它们的horizontal reflection(水平对称),也就是再翻一番,所以,一张图片就可以获得2048个patches。
测试时,取四个角以及中心共五处的patch,加以对这些patch进行水平对称得到的patch来测试网络(一共是10个patches),也就是在预测时将10个patches逐一计算出softmax后的结果,再对所有的预测结果取平均,得到真正的分类。
这里附一张各种翻转方式的直观图

\quad 2)改变RGB通道的强度:
也就是,对每个RGB图片的像素 ![]()
变为:![]() 这里的p和λ是RGB值3x3协方差矩阵的特征向量和特征值。α是均值为1标准差为0.1的高斯随机变量。
这里的p和λ是RGB值3x3协方差矩阵的特征向量和特征值。α是均值为1标准差为0.1的高斯随机变量。
这么做的原因是利用了自然图片的一条重要性质:物体的鉴别特征并不会因为图片强度和颜色的变化而变化,也就是说,一定程度上改变图片的对比度、亮度、物体的颜色,并不会影响我们对物体的识别。在ImageNet上使用这个方法,降低了1%的top-1 error。
论文中运用的是PCA的方式来做的
(2)Dropout
附上两个我觉得讲的很好的
https://blog.csdn.net/program_developer/article/details/80737724
https://www.bilibili.com/video/BV1Fb4112722?from=search&seid=12765948756407009020
自己的总结:
结合不同预测模型是减少测试error rate的有效方法,但是对于一个已经花费了数天时间训练的大型网络而言成本太高了,于是就有了dropout这样的方法来进行数据增强,变换原有的数据生成新的数据来扩充训练集。
在每次训练时,给网络提供了输入后,在整个深度神经网络中随机drop掉一些神经元,也就是说每次参与训练的是整个网络中的一个子网络,这样就使得训练具有不同的子网络结构,但是这些结构都共享权重。这种技术减少了神经元的复杂适应性,减小节点的相互作用,因为神经元无法依赖于其他特定的神经元而存在。因此,它被迫学习更强大更鲁棒的功能,使得这些神经元可以与其他神经元的许多不同的随机子集结合使用。
在测试时,就没法随机drop神经元了,如果随机drop掉,就会带来结果的不稳定性,一会输出a,一会输出b的,模型预测就不准,那么可以采取一种补偿的措施,使得每个神经元的权重都乘上概率p,这样就在总体上使得训练数据与测试数据大体一样了。
参考:
https://zhuanlan.zhihu.com/p/31006686?utm_source=wechat_session
https://blog.csdn.net/qq_28123095/article/details/79767108
神经网络与深度学习 邱锡鹏
统计学习方法 第2版 李航 第16章(讲PCA的)