PIX2PIX

图1图像处理、图形和视觉中的许多问题涉及将输入图像转换为相应的输出图像。这些问题通常由特定算法处理,即使设置总是相同的:将像素映射到像素。条件对抗网是一种通用的解决方案,在各种各样的问题上似乎都能很好地解决。在这里,我们展示了几种方法的结果。在每种情况下,我们都使用相同的体系结构和目标,并且只对不同的数据进行训练。
Abstract
我们研究条件对抗网络作为图像到图像转换问题的通用解决方案。这些网络不仅学习从输入图像到输出图像的映射,还学习了用于训练该映射的损失函数。这使得可以对传统上需要非常不同的损失函数的问题应用相同的通用方法。我们证明了这种方法可以有效地合成标签贴图中的照片,从边缘贴图重建对象,以及着色图像等。事实上,自从发布与此文章相关的pix2pix软件以来,大量互联网用户(其中许多是艺术家)已经在我们的系统中发布了自己的实验,进一步证明了其广泛的适用性和易于采用,而无需参数调整。作为一个社区,我们不再手工设计我们的绘图功能,这项工作表明我们可以在不手工设计损失函数的情况下获得合理的结果。
Introduction
图像处理,计算机图形和计算机视觉中的许多问题可以表现为将输入图像“转换”成相应的输出图像。正如概念可以用英语或法语表达一样,场景可以呈现为RGB图像,渐变场,边缘图,语义标签图等。与自动语言翻译类似,我们定义自动图像 - 在给定足够的训练数据的情况下,将图像转换作为将场景的一种可能表示转换为另一种的任务(参见图1)。传统上,这些任务中的每一项都使用单独的专用机器(例如[15,24,19,8,10,52,32,38,17,57,61])进行处理,尽管设置总是一样的:从像素预测像素。我们在本文中的目标是为所有这些问题开发一个通用框架。
社区已经朝着这个方向迈出了重要的一步,卷积神经网络(CNNs)成为各种图像预测问题背后的共同主力。(CNN)学会将损失函数降至最低,这是一个对结果质量进行评分的目标,虽然学习过程是自动的,但仍需要大量的手工工作来设计有效的损失。换句话说,我们仍然必须告诉CNN我们希望它最小化。但是,就像迈达斯国王一样,我们必须小心我们的期望!如果我们采取一种天真的方法,并要求CNN最小化预测像素和地面真实像素之间的欧几里德距离,它将倾向于产生模糊的结果[42,61]。这是因为通过平均所有合理的输出来最小化欧几里德距离,这会导致模糊。提出损失功能迫使CNN做我们真正想要的事情 - 例如,输出清晰,逼真的图像 - 是一个开放的问题,通常需要专业知识。
如果我们只能指定一个高级别目标,例如“使输出与现实无法区分”,然后自动学习适合于满足此目标的损失函数,那将是非常可取的。幸运的是,这正是最近提出的生成性对抗网络(GAN)所做的[23,12,43,51,62]。如果输出图像是真实的或假的,GAN会学习一种损失,试图对其进行分类,同时训练生成模型以最小化这种损失。模糊的图像是不容忍的,因为它们看起来很明显是伪造的。因为GAN学习了适应数据的损失,所以它们可以应用于传统上需要非常不同类型的损失函数的大量任务。
在本文中,我们在条件设置中探索GAN。正如GAN学习数据的生成模型一样,有条件的GAN(cGAN)学习条件生成模型[23]。这使得cGAN适用于图像到图像的转换任务,我们在输入图像上调节并生成相应的输出图像。
GAN在过去两年中得到了大力研究,我们在本文中探索的许多技术都是先前提出的。尽管如此,早期的论文主要关注具体的应用,目前尚不清楚图像条件GAN如何作为图像到图像转换的通用解决方案。我们的主要贡献是证明在有各种各样的问题上,有条件的GAN产生了合理的结果。我们的第二个贡献是提出一个足以取得良好结果的简单框架,并分析一些重要建筑选择的影响。代码可在https://github.com/phillipi/pix2pix上找到。
Related work
图像建模的结构性损失。图像到图像的转换问题通常被表述为每像素分类或回归(例如,[38,57,27,34,61])。这些公式将输出空间视为“非结构化”,即在给定输入图像的情况下,每个输出像素被视为在条件上独立于所有其他像素。有条件的GAN改为学习结构性损失。结构性损失会对输出的联合配置造成不利影响。大量文献考虑了这种损失,方法包括条件随机场[9],SSIM度量[55],特征匹配[14],非参数损失[36],卷积伪先验[56],和基于匹配协方差统计的损失[29]。条件GAN的不同之处在于学习了损失,并且理论上可以惩罚输出和目标之间不同的任何可能的结构。

图2:训练条件GAN以映射边缘→照片。该
鉴别器D学习在假(由生成器合成)和真实{边缘,照片}元组之间进行分类。 发电机G学会愚弄鉴别器。 与无条件GAN不同,生成器和鉴别器都观察输入边缘映射。
有条件的GAN。我们不是第一个在条件设置中应用GAN的人。先前和并发的工作已经在离散标签[40,22,12],文本[45]以及实际上图像上调整了GAN。图像条件模型已经处理了来自法线贴图[54],未来帧预测[39],产品照片生成[58]以及稀疏注释[30,47]的图像生成的图像预测(针对自回归的参考[46])处理同样的问题)。其他几篇论文也使用GAN进行图像到图像的映射,但只是无条件地应用GAN,依赖于其他术语(如L2回归)来强制输出以输入为条件。这些论文在修复[42],未来状态预测[63],用户约束引导的图像处理[64],样式转移[37]和超分辨率[35]方面取得了令人瞩目的成果。每种方法都是针对特定应用而定制的。我们的框架不同之处在于没有任何特定于应用程序这使我们的设置比大多数其他设置简单得多。
我们的方法也与先前的工作不同,在发电机和鉴别器的几种架构选择中。与过去的工作不同,对于我们的发生器G,我们使用基于“U-Net”的架构[49],对于我们的鉴别器,我们使用卷积“PatchGAN”分类器,它只对图像块的尺度上的结构进行处罚。之前在[37]中提出了类似的PatchGAN架构,用于捕获本地样式统计数据。在这里,我们表明这种方法对更广泛的问题有效,我们研究了改变补丁大小的效果。
3.Method
GAN是生成模型,用于学习从随机噪声向量z到输出图像y的映射,G:z→y [23]。相反,条件GAN学习从观察图像x和随机噪声矢量z到y,tt:{x,z}→y的映射。训练发生器tt以产生不能通过对侧训练的鉴别器D与“真实”图像区分的输出,该鉴别器被训练成尽可能地检测发生器的“假”。该培训程序如图2所示。
3.1.Objective
条件GAN的目标可以表示为
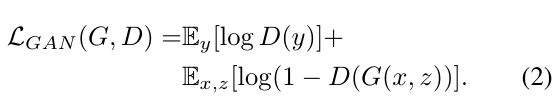
其中G试图最小化这个目标对抗试图最大化它的对抗D,即tt * = arg minG maxD LcGAN(tt,D)。
为了测试调节鉴别器的重要性,
我们还比较了一个无条件变量,其中鉴别器没有观察到x: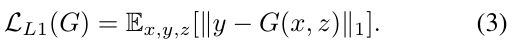
以前的方法发现将GAN目标与更传统的损失混合是有益的,例如L2距离[42]。鉴别器的工作保持不变,但是发生器的任务不仅是欺骗鉴别器,而且还要接近L2意义上的地面实况输出。我们也探索这个选项,使用L1距离而不是L2,因为L1鼓励减少模糊:
LL1(tt)= Ex,y,z [“y - tt(x,z)”1]。 (3)
我们的最终目标是

如果没有z,网络仍然可以学习从x到y的映射,但会产生确定性输出,因此无法匹配除delta函数之外的任何分布。 过去的条件GAN已经承认了这一点并且除了x之外还提供了高斯噪声z作为发生器的输入(例如,[54])。 在最初的实验中,我们没有发现这种策略有效 - 发生器只是学会忽略噪声 - 这与Mathieu等人一致。[39]。 相反,对于我们的最终模型,我们仅以dropout的形式提供噪声,在训练和测试时间应用于我们的发电机的多个层。 尽管存在dropout噪声,但我们观察到网络输出中只有轻微的随机性。 设计产生高随机输出的条件GAN,从而捕获它们建模的条件分布的完整熵,是当前工作留下的一个重要问题。
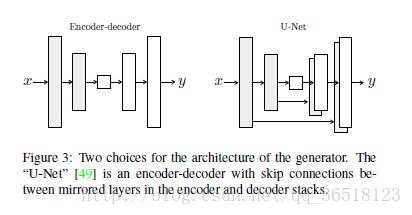
图3:发电机架构的两种选择。 “U-Net”[49]是编码器 - 解码器,在编码器和解码器堆栈中的镜像层之间具有跳过连接。
3.2。网络架构
我们使用[43]中的发生器和鉴别器结构进行调整。生成器和鉴别器都使用卷积形式的模块 - BatchNorm-ReLu [28]。在线补充材料中提供了该架构的详细信息,其中包含下面讨论的主要功能。
3.2.1具有跳过的生成器
图像到图像转换问题的一个定义特征是它们将高分辨率输入网格映射到高分辨率输出网格。另外,对于我们考虑的问题,输入和输出的表面外观不同,但两者都是相同底层结构的渲染。因此,输入中的结构与输出中的结构大致对齐。我们围绕这些考虑设计了发电机架构。
许多以前针对该领域问题的解决方案[42,54,29,63,58]使用了编码器 - 解码器网络[25]。在这样的网络中,输入通过一系列逐渐下采样的层,直到瓶颈层,此时该过程被反转。这样的网络要求所有信息流都通过所有层,包括瓶颈。对于许多图像转换问题,在输入和输出之间共享大量低级信息,并且希望直接在网络上传送该信息。例如,在图像colorizaton的情况下,输入和输出共享突出边缘的位置。
为了给发生器提供一种绕过这样的信息瓶颈的方法,我们按照“U-Net”[49]的一般形状添加跳过连接。具体来说,我们在每个层i和层n-i之间添加跳过连接,其中n是层的总数。每个跳过连接简单地将第i层的所有通道与第n-i层的通道连接起来。
3.2.2马尔可夫鉴别器(PatchGAN)
众所周知,L2损耗 - 和L1,见图4 - 在图像生成问题上产生模糊结果[33]。尽管这些损失不能鼓励高频清晰度,但在许多情况下它们仍能准确地捕获低频。对于出现这种情况的问题,我们不需要一个全新的框架来强制低频率的正确性。 L1已经做好了。

图4 不同的损失导致不同质量的结果。每列显示在不同损失下训练的结果。(L1加GAN?)
图4:不同的损失会导致不同的结果质量。 每列显示在不同损失下训练的结果。 请参阅
https://phillipi.github.io/pix2pix/了解更多示例。
这促使限制GAN鉴别器仅模拟高频结构,依赖于L1项来强制低频正确性(方程4)。为了模拟高频,将我们的注意力限制在局部图像块中的结构就足够了。因此,我们设计了一个鉴别器体系结构 - 我们称之为PatchGAN-仅在补丁规模上惩罚结构。该鉴别器试图分类图像中的每个N×N贴片是真实的还是假的。我们在整个图像中对这个鉴别器进行卷积运算,平均所有响应以提供D的最终输出。
在4.4节中,我们证明了N可以比图像的完整尺寸小得多,并且仍然可以产生高质量的结果。这是有利的,因为较小的PatchGAN具有较少的参数,运行得更快,并且可以应用于任意大的图像。
这种鉴别器有效地将图像建模为马尔可夫随机场,假设像素之间的独立性超过了贴片直径。这种联系之前曾在[37]中探讨过,也是纹理[16,20]和风格[15,24,21,36]模型中的常见假设。因此,我们的PatchGAN可以理解为纹理/风格损失的一种形式。
3.3。优化和推理
为了优化我们的网络,我们遵循[23]的标准方法:(?)我们在D上的一个梯度下降步骤之间交替,然后在tt上一步。正如原始GAN论文所建议的那样,我们不是训练tt来最小化log(1 - D(x,tt(x,z)),而是训练最大化log D(x,tt(x,z))[另外,我们将目标除以2,同时优化D,这减慢了D学习相对于tt的速率。我们使用minibatch SGD并应用Adam求解器[31],学习率为0.0002,并且动量参数β1= 0.5,β2= 0.999。
在推理时,我们以与训练阶段完全相同的方式运行发电机网。这与通常的协议不同之处在于我们在测试时应用了丢失,并且我们使用测试批次的统计数据来应用批量标准化[28],而不是训练批次的汇总统计数据。当批量大小设置为1时,这种批量标准化方法被称为“实例标准化”,并且已被证明在图像生成任务中有效[53]。在我们的实验中,我们根据实验使用1到10之间的批量大小。
4.Experiments
为了探索条件GAN的一般性,我们在各种任务和数据集上测试该方法,包括图形任务,如照片生成和视觉任务,如语义分割:
•语义标签照片,在Cityscapes数据集[11]上训练。
•建筑标签→照片,在CMP外墙上进行培训[44]。
•Map↔aerial照片,对从Google地图中删除的数据进行过培训。
•BW→彩色照片,在[50]上训练。
•边缘→照片,训练有关[64]和[59]的数据;使用HED边缘检测器生成的二次边[57]
再加上后处理。
•草图→照片:在[18]的人体素描草图上测试边缘→照片模型。
•白天→夜晚,在[32]训练。
•热量→彩色照片,训练有关[26]的数据。
•带有缺失像素的照片→经过修复的照片,在[13]的Paris StreetView上进行了培训。
在线补充材料中提供了有关每个数据集的培训详情。在所有情况下,输入和输出只是1-3通道图像。定性结果显示在图8,9,11,10,12,13,14,15,16,17,18,19中。图20中突出显示了几个故障情况。更全面的结果可在
https://phillipi.github.io/pix2pix/。
数据要求和速度。我们注意到,即使在小型数据集上也可以获得不错的结果。我们的视频训练集仅包含400个图像(参见图13中的结果),而日夜训练集仅包含91个独特的网络摄像头(参见图14中的结果)。在这个大小的数据集上,训练可以非常快:例如,图13中显示的结果在单个Pascal Titan X GPU上花了不到两个小时的训练。在测试时,所有型号在此GPU上运行不到一秒钟。
4.1。评估指标
评估合成图像的质量是一个开放和困难的问题[51]。诸如每像素均方误差的传统度量不评估结果的联合统计,因此不测量结构化损失旨在捕获的结构。
为了更全面地评估我们结果的视觉质量,我们采用了两种策略。首先,我们对亚马逊机械土耳其人(AMT)进行“真实与虚假”的感知研究。对于色彩化和照片生成等图形问题,人类观察者的合理性通常是最终目标。因此,我们使用这种方法测试我们的地图生成,航空照片生成和图像着色。
其次,我们测量我们的综合城市景观是否足够现实,现成的识别系统可以识别其中的物体。该度量类似于[51]中的“初始得分”,[54]中的对象检测评估,以及[61]和[41]中的“语义可解释性”度量。
AMT感知研究对于我们的AMT实验,我们遵循[61]的协议:为Turkers提供了一系列试验,这些试验将“真实”图像与我们的算法生成的“假”图像进行对比。在每次试验中,每个图像出现1秒钟,之后图像消失,并且Turkers被给予无限时间来回答哪个是伪造的。每个阶段的前10个图像都是练习,并且Turkers得到了反馈。没有提供关于主要实验的40个试验的反馈。每个会话一次仅测试一个算法,并且不允许Turkers完成多个会话。 ~50个Turkers评估了每个算法。与[61]不同,我们没有包括警惕性试验。对于我们的着色实验,真实和伪造图像是从相同的灰度输入生成的。对于map↔aerial照片,真实和虚假图像不是从相同的输入生成的,以使任务更加困难并避免楼层结果。对于map↔aerial照片,我们训练了256×256分辨率的图像,但利用完全卷积翻译(如上所述)来测试512×512图像,然后对其进行下采样并以256×256分辨率呈现给Turkers。对于着色,我们在256×256分辨率图像上进行了训练和测试,并以相同的分辨率将结果呈现给Turkers。
“FCN得分”虽然已知生成模型的定量评估具有挑战性,但最近的工作[51,54,61,41]已尝试使用预先训练的语义分类器来测量所生成的刺激的可辨别性作为伪度量。直觉是如果生成的图像是真实的,则在真实图像上训练的分类器也能够正确地对合成图像进行分类。为此,我们采用流行的FCN-8 [38]架构进行语义分割,并在城市景观数据集上进行训练。然后,我们根据分类精度对这些照片合成的标签进行合成照片评分。
4.2。目标函数分析
Eqn中目标的哪些组成部分。 4重要吗?我们进行消融研究以隔离L1项,GAN项的影响,并使用以输入为条件的鉴别器(cGAN,Eqn.1)与使用无条件鉴别器(GAN,Eqn.2)进行比较。

图5:向编码器 - 解码器添加跳过连接以创建“U-Net”可以获得更高质量的结果。
| L1 |
0.42 |
0.15 |
0.11 |
| GAN |
0.22 |
0.05 |
0.01 |
| cGAN |
0.57 |
0.22 |
0.16 |
| L1+GAN L1+cGAN |
0.64 0.66 |
0.20 0.23 |
0.15 0.17 |
| Ground truth |
0.80 |
0.26 |
0.21 |
表1:不同损失的FCN分数,在Cityscapeslabels↔photos上评估。
| Encoder-decoder (L1) |
0.35 |
0.12 |
0.08 |
| Encoder-decoder (L1+cGAN) |
0.29 |
0.09 |
0.05 |
| U-net (L1) |
0.48 |
0.18 |
0.13 |
| U-net (L1+cGAN) |
0.55 |
0.20 |
0.14 |
表2:不同发电机架构(和目标)的FCN分数,在Cityscapeslabels↔photos上评估。 (U-net(L1-cGAN)得分与其他表中报告的得分不同,因为本试验的批量大小为10,其他表的批量大小为1,训练运行之间的随机变化。
| 1×1 |
0.39 |
0.15 |
0.10 |
| 16×16 |
0.65 |
0.21 |
0.17 |
| 70×70 |
0.66 |
0.23 |
0.17 |
| 286×286 |
0.42 |
0.16 |
0.11 |
表3:在城市景观标签→照片上评估的辨别者的不同感受野大小的FCN分数。 请注意,输入图像为256×256像素,较大的感受域用零填充。
图4显示了这些变化对两个标签→照片问题的定性影响。单独的L1会导致合理但模糊的结果。单独的cGAN(在方程4中设置λ= 0)给出了更清晰的结果,但在某些应用中引入了视觉伪像。将两个项一起添加(λ= 100)可以减少这些伪影。
我们使用城市景观标签上的FCN分数→照片任务(表1)量化这些观察结果:基于GAN的目标获得更高的分数,表明合成图像包含更多可识别的结构。我们还测试了从鉴别器中去除条件的效果(标记为GAN)。在这种情况下,损失不会影响输入和输出之间的不匹配;它只关心输出看起来真实。这种变体导致非常差的性能;检查结果表明,无论输入照片如何,发生器都会折叠成几乎完全相同的输出。显然,在这种情况下,重要的是损失测量输入和输出之间匹配的质量,并且实际上cGAN比GAN执行得更好。但是请注意,添加L1项还会促使输出相对于输入,因为L1损失会对正确匹配输入的地面实况输出与合成大小的输出之间的距离进行惩罚,而这些输出可能不会。相应地,L1 + GAN在创建尊重输入标签图的逼真渲染方面也是有效的。结合所有术语,L1 + cGAN,表现同样出色。
色彩度条件GAN的显着效果是它们产生清晰的图像,即使输入标签图中不存在幻觉,也会产生幻觉的空间结构。可以想象,cGAN对光谱维度中的“锐化”具有类似的效果 - 即使图像更加有色。就像L1在不确定精确定位边缘的位置时会激励模糊一样,当不确定像素应该采用的几个合理颜色值中的哪一个时,它也会激励平均的浅灰色。特别地,通过选择条件概率密度函数相对于可能颜色的中值来最小化L1。另一方面,对抗性损失原则上可以意识到灰色输出是不现实的,并鼓励匹配真实的颜色分布[23]。在图7中,我们研究了我们的cGAN是否实际上对Cityscapes数据集实现了这种效果。该图显示了Lab颜色空间中输出颜色值的边缘分布。地面实况分布用虚线表示。很明显,L1导致了比实际情况更窄的分布,证实了L1鼓励平均灰色的假设。另一方面,使用cGAN将输出分布推向接近事实。
4.3。发电机结构分析
U-Net架构允许低级信息在网络上快捷方式。这会带来更好的结果吗?图5和表2比较了U-Net与城市景观生成的编码器 - 解码器。仅通过切断U-Net中的跳过连接来创建编码器 - 解码器。编码器 - 解码器无法学习在我们的实验中生成逼真的图像。 U-Net的优点似乎不是特定于条件GAN:当U-Net和编码器 - 解码器都训练有L1损失时,U-Net再次获得了优异的结果。

图6:补丁大小变化。 输出的不确定性表现出不同的损失函数。 在L1下,不确定区域变得模糊和不饱和。 1x1 PixelGAN鼓励更大的色彩多样性,但对空间统计没有影响。 16x16 PatchGAN可以创建局部清晰的结果,但也会导致拼接工件超出其可以观察到的范围。 70×70 PatchGAN在空间和光谱(色彩)维度上强制输出即使不正确也是如此。 完整的286×286 ImageGAN产生的结果在视觉上类似于70×70 PatchGAN,但根据我们的FCN得分指标(表3),质量略低。 有关其他示例,请参阅https://phillipi.github.io/pix2pix/。

图7:在Cityscapes上测试的cGAN的颜色分布匹配属性。 (参见原始GAN论文[23]的图1)。 注意,直方图交叉点得分由高概率区域中的差异支配,这些差异在图中是不可察觉的,其显示对数概率并因此强调低概率区域中的差异。
4.4。从PixelGAN到PatchGAN到ImageGAN
我们测试了改变我们的鉴别器感受区域的贴片大小N的效果,从1×1“PixelGAN”到完整的286×286“ImageGAN”1。图6显示了该分析的定性结果,表3使用FCN评分量化了效果。请注意,在本文的其他地方,除非另有说明,否则所有实验都使用70×70 PatchGAN,对于本节,所有实验都使用L1 + cGAN损失。
PixelGAN对空间清晰度没有影响,但确实增加了结果的色彩(在图7中量化)。例如,当网络以L1损耗训练时,图6中的总线被涂成灰色,但随着PixelGAN丢失而变为红色。颜色直方图匹配是图像处理中的常见问题[48],PixelGAN可能是一种很有前景的轻量级解决方案。
使用16×16 PatchGAN足以促进清晰的输出,并获得良好的FCN分数,但也会导致拼接伪像。 70×70 PatchGAN减轻了这些伪影,并获得了略微更好的相似分数。超出此范围,扩展到完整的286×286 ImageGAN,似乎不会改善结果的视觉质量,并且
事实上,FCN得分显着降低(表3)。这可能是因为ImageGAN具有比70×70 PatchGAN更多的参数和更大的深度,并且可能更难训练。
完全卷积翻译。 PatchGAN的一个优点是固定大小的补丁鉴别器可以应用于任意大的图像。我们也可以在比其训练的图像更大的图像上卷积地应用发生器。我们在map↔aerial照片任务上测试这个。在256×256图像上训练生成器后,我们在512×512图像上进行测试。图8中的结果证明了这种方法的有效性。
4.5。感知验证
我们验证了我们在地图照片和灰度→颜色任务上的结果的感知真实性。我们用于map↔photo的AMT实验的结果在表4中给出。通过我们的方法产生的航空照片使参与者在18.9%的试验上愚弄,显着高于L1基线,其产生模糊的结果并且几乎从未欺骗参与者。相比之下,在照片→地图方向上,我们的方法只会欺骗参与者6.1%的三个人,这与L1基线的性能(基于自举测试)没有显着差异。这可能是因为较小的结构误差在具有刚性几何形状的地图中比在更加混乱的航空照片中更明显。
我们在ImageNet上训练着色[50],并在[61,34]引入的测试分裂上进行测试。我们的方法,L1 + cGAN损失,使22.5%的试验成为参与者(表5)。我们还测试了[61]的结果和使用L2损失的方法的变体(详见[61])。有条件的GAN得分类似于[61]的L2变体(差异无效的自助测试),但没有达到[61]的完整方法,这使得参与者在我们的实验中愚弄了27.8%的试验。我们注意到他们的方法经过专门设计,可以很好地进行着色。
4.6。语义分割
有条件的GAN似乎对输出非常详细或摄影的问题有效,这在图像处理和图形任务中很常见。那么视觉问题,比如语义分割,输出是否比输入复杂?
为了开始测试,我们在城市景观照片→标签上训练cGAN(有/无L1损失)。图10显示了定性结果,并且表6中报告了定量分类准确度。有趣的是,在没有L1损失的情况下训练的cGAN能够以合理的准确度解决该问题。据我们所知,这是GAN成功生成“标签”的第一次演示,这些标签几乎是离散的,而不是“图像”,具有连续值变化2。虽然cGAN取得了一些成功,但它们远不是解决这个问题的最佳方法:使用L1回归得分比使用cGAN要好,如表6所示。我们认为对于视力问题,目标(即预测输出)接近地面的事实)可能不像图形任务那么模糊,像L1这样的重建损失基本上就足够了。
4.7。社区驱动的研究
自从论文和我们的pix2pix代码库首次发布以来,Twitter社区,包括计算机视觉和图形从业者以及视觉艺术家,已成功将我们的框架应用于各种新颖的图像到图像翻译任务,远远超出了范围原始论文图11显示了#pix2pix主题标签中的几个示例,包括背景删除,调色板生成,草图→纵向,草图→宠物小精灵,“我这样做”姿势转移,以及奇怪的流行#edges2cats和#fotogenerator。请注意,这些应用程序是创造性的项目,不是在受控的科学条件下获得的,并且可能依赖于我们发布的pix2pix代码的一些修改。尽管如此,他们证明了我们的方法作为图像到图像转换问题的通用商品工具的前景。
5.结论
本文的结果表明,条件式广告网络是许多图像到图像翻译任务的有前途的方法,特别是涉及高度结构化图形输出的任务。这些网络学习适应手头任务和数据的损失,这使得它们适用于各种各样的设置。
致谢:我们感谢Richard Zhang,Deepak Pathak和Shubham Tulsiani进行了有益的讨论,感谢Xie帮助HED边缘检测器,以及用于探索许多应用程序和建议改进的在线社区。感谢Christopher Hesse,Kaihu Chen,Jack Qiao,Mario Klingemann,Brannon Dorsey,Gerda Bosman,Ivy Tsai和Yann LeCun允许在图11中使用他们的作品。这项工作部分由NSF SMA-1514512,NGA支持NURI,IARPA通过空军研究实验室,英特尔公司,伯克利深驱动器,以及Nvidia的硬件捐赠。 J.Y.Z.由Facebook毕业生奖学金支持。免责声明:此处包含的观点和结论均为作者的观点和结论,不应被解释为必须代表IARPA,AFRL或美国政府的正式或默示的正式政策或背书。