数值计算:线性方程组求解及应用
文章目录
- 一. 实验目的
- 二. 实验内容、过程及结果
- 实验一:使用直接法求解线性方程组
- ①高斯消去法:
- ②列主元法:
- 实验二:使用迭代法求解线性方程组
- ①Jacobi 迭代法
- ②Gauss-Seidel 迭代法
- ③逐次超松弛迭代法
- ④共轭梯度法
- ⑤令n=10、50、100、200,分别绘制出算法的收敛曲线,横坐标为迭代步数,纵坐标为相对误差。
- ⑥接下来是六种算法的比较
- ⑦接下就是SOR算法的改变w的选择问题了
- 实验三:
- ①PageRank算法:
- ②对网络节点的受信度进行评分:
- ③在实验报告中,请给出伪代码。
- 三. 实验收获:
一. 实验目的
- 熟悉线性方程组求解方法,即直接法以及迭代法
- 比较不同算法之间的差异性以及收敛速度或条件比较不同算法之间的差异性以及收敛速度或条件
二. 实验内容、过程及结果
实验一:使用直接法求解线性方程组
①高斯消去法:
主要的过程即是左变换变成上三角矩阵以及高斯回代,其中主要的繁杂步骤是变成上三角矩阵的步骤。
-
假设一个矩阵有n×n个元素,其中aij 表示第i行第j列的元素,进行转化为上三角矩阵的过程是
-
Ⅰ将第一行元素的元素乘以-aj1/a11(其中j表示从2-n行)然后加上2-n行的元素,这样的话就将第一列元素转变为只剩第一个元素不为0的一列了。
-
Ⅱ依据此步骤,在第i行即是将第i行元素乘以-aji/aii然后再加到后面的i+1到n行元素上,直到将矩阵转化为上三角矩阵。

-
这个步骤可以用两个for循环(现实是三个循环,因为其中那个一行的元素的相加需要多使用一个for循环)来完成。代码如下:

-
这个过程中的计算公式如下:
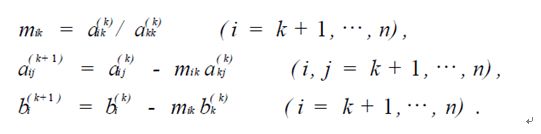
总共大约需要n3/3次乘法操作。 -
Ⅲ第三个步骤则是利用第n行只有一个未知数的方程组依次求未知数后回代到上一行方程中进行回代求解,主要的代码体现如下:
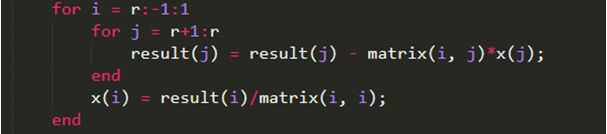
-
该步骤的计算公式是:
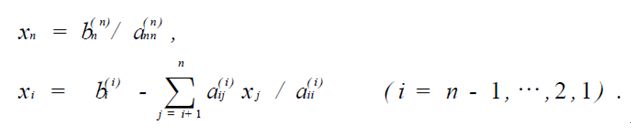
其中求和需要一个for循环以及求n个未知数需要另一个for循环。由此可得,高斯消元法的复杂度是O(n3/3)
重要:
- 高斯消元法从头到尾都是在指利用aii作为分母进行乘法运算,而作为分母的一个很重要的条件就是要要求不能为0。所以这里就需要一个约化的主元素aii(i)不为0的一个充要条件:矩阵A的顺序主子式Di≠0(i=1,2,…,k)
- 其次是高斯消元法会有一些弊端,即是算法的稳定性存在问题,因为aii作为分母,如果很小的话,则会导致其他元素的数量级的严重增长和舍入误差的扩散(因为计算机是离散的),使得结果误差大。其次是高斯消元法会有一些弊端,即是算法的稳定性存在问题,因为aii作为分母,如果很小的话,则会导致其他元素的数量级的严重增长和舍入误差的扩散(因为计算机是离散的),使得结果误差大。
- 利用高斯消元法进行运算的实例:

②列主元法:
主要目的:尽可能的调整主元素的大小使其不会出现上面的因为分母过小而导致的误差变大的现象,所以列主元法其实就是在高斯消元法的基础上添加了一开始的选主元行的步骤,而选主元行主要是对该列的元素进行遍历直到找到绝对值最大的元素。所以增加的步骤如下:

- 每次找到主元行之后就要进行行的交换,这会导致时间上的增加以及空间消耗的增加。
利用列主元法的实例如下:

- 另外是两种算法的对比实验:
利用的矩阵是服从正态分布的矩阵:
其中因为200的差异并不是很明显,所以就添加使用了500.
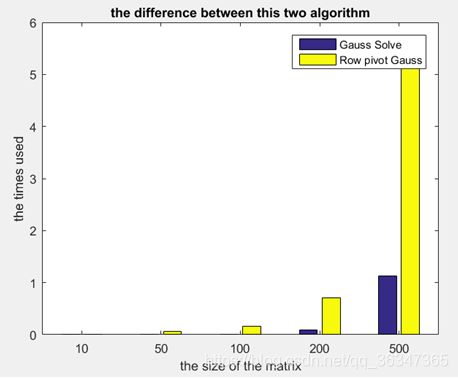
从上图不能难看出列主元法因为寻找每一列的最大元素所以导致了时间消耗的增加,而且会随着矩阵的增大而导致时间成指数倍的增加。
实验二:使用迭代法求解线性方程组
①Jacobi 迭代法
雅可比迭代利用的是主要是并行算法,将一个矩阵分为三个部分,对角线元素,上三角矩阵以及下三角矩阵。A= D – L – U;
其中D可以直接利用diag(diag(A))获得。而L可以利用D - tril(A)获得,剩下的U就不用说了。雅可比迭代的计算公式如下:

主要的运算步骤如下:

其中norm是为了求x1-x0的无穷范数,即是x1-x0中最大的绝对值小于误差就终止迭代。
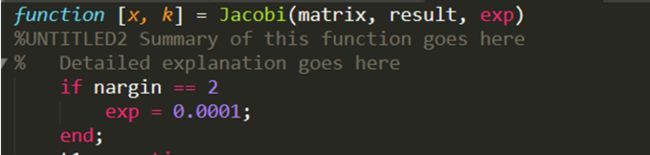
这一部分主要是为了在不需要设定exp的时候默认exp的值为0.0001,其中nargin是用于判断输入的参数的个数的。
利用Jacobi的示例如下:
 其中p为迭代次数,而x为运行时间。
其中p为迭代次数,而x为运行时间。
重点(雅可比迭代的收敛条件)
- 设Ax = b, 其中A= D – L – U为非奇异矩阵,且对角矩阵D也是非奇异的,则
- 充要条件是p(J)< 1, 其中 J = D-1(L+U)充要条件是p(J)< 1, 其中 J = D-1(L+U)
- 当A为对称矩阵以及对角线元素大于0时当A为对称矩阵以及对角线元素大于0时
- 充要条件是A及2D-A均为正定矩阵,其中D为A的对角阵。充要条件是A及2D-A均为正定矩阵,其中D为A的对角阵。
②Gauss-Seidel 迭代法
高斯赛德尔迭代与雅可比迭代的主要差别是雅可比每一次迭代过程中前后是没有关系的,而高斯赛德尔迭代则是每一次计算都是利用最新的结果。所以这一个过程就得到了加速。
高斯赛德尔迭代的计算公式如下:

复杂度是(2n2)
高斯赛德尔迭代的示例:

其中p为迭代次数,而x为运行时间。
重点(高斯赛德尔迭代的收敛条件)
- 设Ax = b, 其中A= D – L – U为非奇异矩阵,且对角矩阵D也是非奇异的,则
- 充要条件是p(G)< 1, 其中 G=(D – L)-1U
- 当A为对称矩阵以及对角线元素大于0时
- 充要条件是A是正定矩阵。
③逐次超松弛迭代法
逐次超松弛迭代法又称为SOR算法,其主要的加入了一个松弛引子w,考虑到的矩阵主要是密度比较小的矩阵的求解,可以看成是高斯赛德尔迭代的一种修正,而且当w = 1的时候,SOR就是高斯赛德尔迭代了。该算法的公式如下:

SOR算法每次迭代的主要运算量是计算一次矩阵与向量的乘法。
SOR迭代的示例如下:

从上面不难看出SOR算法的收敛性很快,而收敛性的快慢也取决于w的取值。
重点(SOR迭代的收敛条件)
- 必要条件:设解线性方程组Ax = b的SOR迭代法收敛,则0 < w < 2.
- 当A为对称正定矩阵,同时0 < w < 2的时候SOR算法迭代收敛。
④共轭梯度法
共轭梯度法又称为CG方法。是一种求解大型稀疏对称正定方程组的一种十分有效的方法。
主要步骤如下:
- Ⅰ任取x(0)∈Rn, 计算r(0)= b – Ax(0), 取p(0) = r(0).
- Ⅱ对k = 0, 1, … 计算
αk = (r(k), r(k))/(p(k), Ap(k))
x(k+1) = x(k) + αkp(k)
r(k+1) = r(k) – αk Ap(k), βk = (r(k+1), r(k+1))/ (r(k), r(k))
p(k+1) = r(k+1) + βk p(k) - Ⅲ若r(k)= 0,或者(p(k), Ap(k)) = 0, 则计算停止,则x(k) = x*,由于A正定,故当(p(k), Ap(k)) = 0时,p(k)=0,而(r(k), r(k)) = (r(k), p(k)) = 0,也即r(k) = 0
所以对应的代码如下:

CG迭代实例如下:

⑤令n=10、50、100、200,分别绘制出算法的收敛曲线,横坐标为迭代步数,纵坐标为相对误差。
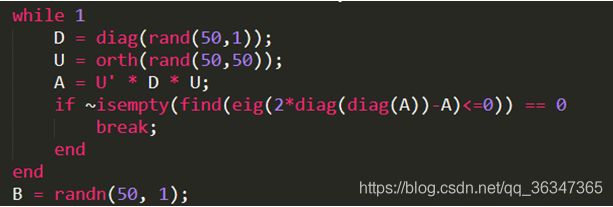
其中SOR的w默认为1.3,同时为了满足雅可比的苛刻收敛条件以及SOR算法收敛的条件的综合,使用的测试矩阵是A为对称正定矩阵以及2D-A也为正定矩阵的矩阵。如下为生成矩阵的方法:对称正定矩阵是用二次型构造的,而终止条件则是2D-A的特征值均大于0.而相对误差则设置为
![]()
(注:~isempty(find(a<0)) 如果有负数则为真,如果没有则为假)
- 这是n = 10的时候的收敛曲线:
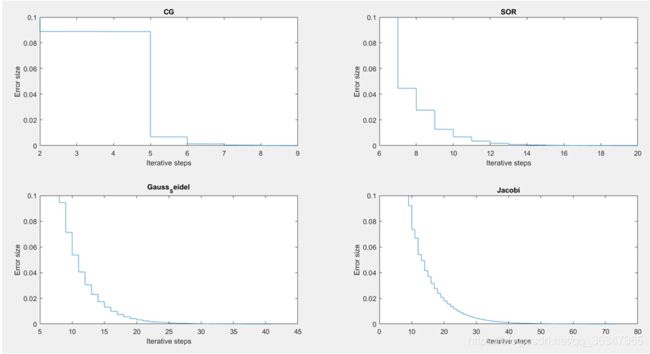
- 这是n = 50的时候的收敛曲线:
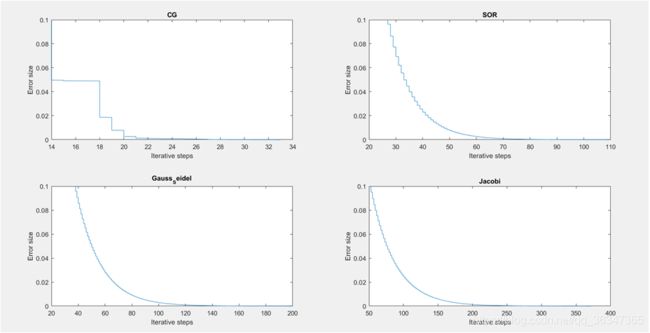
- 这是n = 100的时候的收敛曲线:
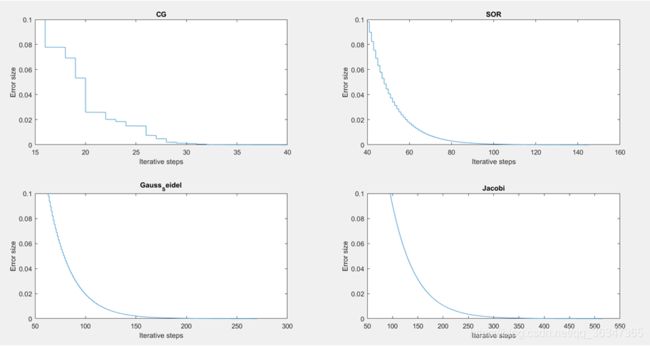
- 这是n = 200的时候的收敛曲线:

- 从这四幅图中我们可以看出这四种算法均是收敛的,因为生成的矩阵是满足收敛条件的,而对于相同误差我们不难发现迭代次数的大小排行是:CG < SOR < GausssSeidel < Jaccibi,而这是由这四种算法的特性所决定的,比如Jaccibi是一种适合于并行计算的方法,在一回迭代中它每一次利用的是上一次迭代的结果,而高斯赛德尔迭代则是利用最新的结果,可想而知高斯赛德尔迭代的速度会更快,而SOR则是在高斯赛德尔迭代的基础上的加速版本,CG算法主要的长处是求解大型稀疏对称正定方程组,在上面的图中不难看到当n = 10的时候,CG算法的优势并不是很明显,而在n = 200的时候就能看到CG算法的显著优越性了。
⑥接下来是六种算法的比较
利用的是统计图进行运算时间的统计,同时使用的是cputime来获取运行时间的。
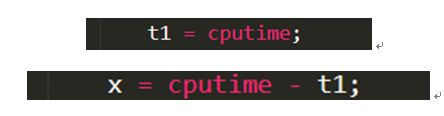
统计图如下:因为每一次运行的时间可能具有偶然性,所以就测试100次运算的时间平均值,得到以下的统计图

根据统计图我们可以大概看到:
- 当n的大小不是很大的时候,迭代法不占有很大的优势,甚至有可能还比直接法更慢,这是因为直接法的计算复杂性是O(n3/3),而迭代法的计算复杂性是由k即迭代次数所决定的约O(kn2),在前面的图中我们可以看见在n=10时,几乎所有的迭代法要达到10这个量级,所以即使每次迭代的时间短,但是k却会比较大,所以前期的时间复杂度会略高于直接法,而后期,因为直接法是n的三次方量级,增长速度必然会很快,所以到了200以及500的时候迭代法的优势就十分显著了。
- 跟我们前面的分析的是一致的,就是雅可比 < 高斯塞德尔 < SOR。
- 有一个很让人惊奇的现象:CG算法的时间并没有比直接法快多少,但是在前面的收敛图中我们看到的是CG算法的迭代次数是最少的,这让我感到十分的吃惊,所以就让我们分析一下CG(共轭梯度算法)吧。
CG算法的核心运算步骤如下:

从上面我们会突然意识到CG算法的迭代次数虽然比较少,但是主要的时间消耗都花在了矩阵与数组、向量之间的计算中了,所以时间开销就十分巨大。
⑦接下就是SOR算法的改变w的选择问题了
显示着运行了几次,只截了下面两张图,不难看到对于两个不同的矩阵,最好的w值是不一样的,此时的阶数是50。一开始当松弛因子逐渐增大的时候,会导致迭代次数降低,而当松弛因子达到最佳松弛因子的时候,则迭代次数会降到最低,而超过了这一个数值之后,迭代次数会反弹增加。

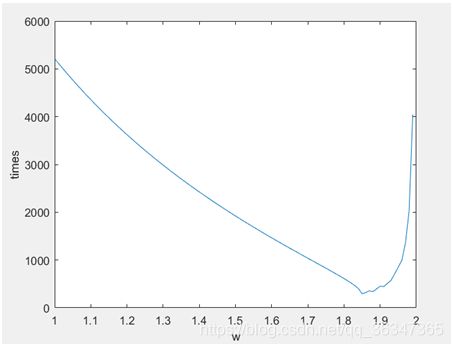
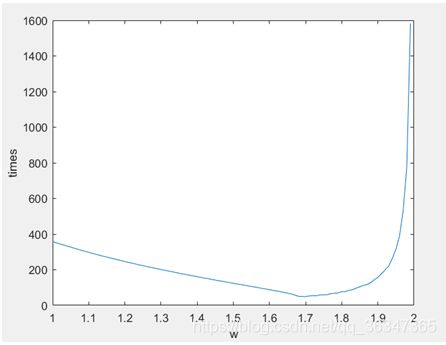

- 题外话:从上面我们会发现可能对于相同的阶数的矩阵的对应的比较好的w值是不一样的,但是我们会发现,似乎50阶的松弛因子似乎落在同一个区间内,就是大概是在一个范围内,这样的话,我们可以通过统计求平均来大概获得每个阶数的最佳松弛因子。
因为量比较大,所以我只是计算了10 20 30 40 50的100个测试样本的平均值,得到的结果如下,可以看到
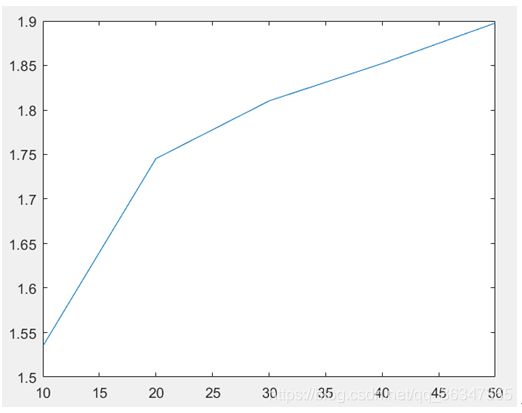
当n增大的时候,最佳松弛因子也会不断地增大并趋近于2,而当n比较小的时候,则松弛因子趋近于1.这可能是一个寻找最佳松弛因子的一个比较好的开始,因为对应每一个矩阵的最佳松弛因子是不一样的,但是只要找到比较好的松弛因子,计算结果依旧会是比较好的。
实验三:
在Epinions 社交数据集中,每个网络节点可以选择信任其它节点。借鉴Pagerank 的思想编写程序,对网络节点的受信任程度进行评分。
①PageRank算法:
PageRank主要引入的指标是链接指标,即是很多其他网页如果存在对这个网页的指向,那么这个被指向的网页的排名必然会就比较高,当然其他网页的排名也会影响这个网页的排名。如果一个网页存在指向另一个网页的链接,则记为1,不管有几个指向链接。在一定的网页数量构成的网络中,这就构成了一个矩阵,所以PageRank的思想是由这一个矩阵计算每一个网页的排名。而因为每一个网页之间会互相影响,所以就需要进行迭代计算知道算出最稳定的数值。每一个网页的PG计算如下:
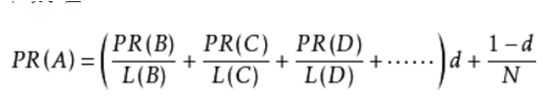
后面那一个值的原因是:所有这些被换算为一个百分比再乘上一个系数。由于“没有向外链接的页面”传递出去的PageRank会是0,所以,Google通过数学系统给了每个页面一个最小值。
②对网络节点的受信度进行评分:
因为下下来之后发现那个数据贼恐怖,有几万个节点,所以就选择0、4、5、7、8、9、10、11、12、13 这10个,根据这10个所组成的小的信任圈所计算出来的结果显示出来
根据这几个的关系我们可以得到矩阵如下(第一行代表的是0为起始点的,第二行代表的是4为起始点的,以此类推):
[0, 1, 1, 1, 1, 1, 1, 1, 1, 1;
1, 0, 0, 0, 0, 0, 1, 0, 1, 0;
1, 1, 0, 0, 1, 0, 0, 0, 1, 0;
0, 0, 0, 0, 1, 0, 0, 0, 0, 0;
1, 0, 1, 0, 0, 0, 0, 0, 0, 0;
1, 0, 0, 0, 0, 0, 1, 0, 0, 0;
0, 0, 0, 1, 0, 1, 0, 1, 1, 0;
1, 1, 1, 0, 0, 0, 1, 0, 1, 0;
1, 0, 1, 1, 0, 0, 1, 1, 0, 0;
0, 0, 0, 0, 0, 0, 0, 0, 0, 0];
而利用写好的PageRank算法进行受信度评分,
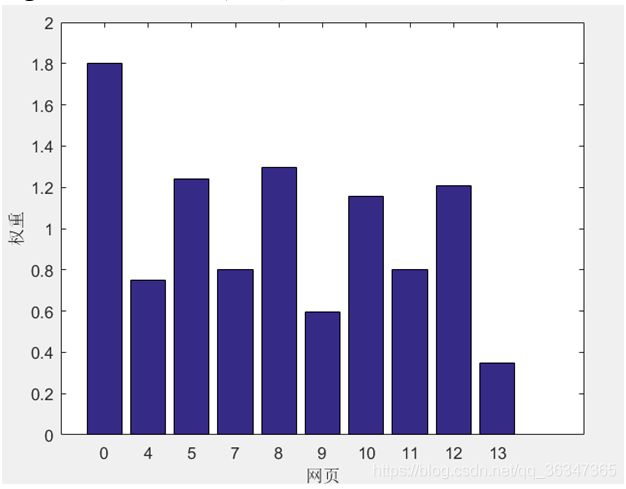
根据上面的评分图我们可以看到0的可信度最高,而13的可信度最低,因为在这个信任圈中13并没有任何指向的元素。而评分的话可以根据上面的权重大小进行划分。
③在实验报告中,请给出伪代码。
%L = input('The matrix \n');
%输入矩阵L
%迭代终止参数变量
sigma = 0.0001;
%获取图的总结点数
N= size(L,1);
% 用来检查L矩阵上是否存在大于1的链接,如果有置为1;
for k= 1:N
for j = 1:N
if( L(k, j) ~= 0)
L(k, j) = 1;
end
end
end
q= 0.85; % 默认阻尼系数
% 构造D
d= sum(L,2);
D= diag(d);
% 构造M= L'*D^(-1)
M= L'*inv(D);
e= ones(N,1);
a= (d==0); % a为用于描述“悬挂网页”的行向量
% 构造S
S= M + e*a'/N;
% 构造最终的概率转移矩阵
G= q*S + (1-q)*e*e'/N;
H0= zeros(N,1); % 初始化H0
H1= ones(N,1); % 默认初始权重向量均为1
count= 0; % 初始化迭代次数
% 终止条件是小于允许的误差
while norm(H1-H0) >= sigma
H0= H1;
H1= G*H0;
count= count+1;
end
% 输出结果
三. 实验收获:
- 从这一次作业中可以更加直观的了解各个算法的优缺点以及收敛条件。同时也意外地发现了通常情况下的收敛因子的取值方法,即是一定阶数的矩阵的最佳收敛因子是位于一个区间内的,所以可以通过采样统计得出大概的平均值。这对于其他的矩阵的运算时取值是有帮助的。
- 迭代法中比较让人吃惊的是CG算法,因为在迭代次数中CG算法是最好的,即是迭代次数是最少的,但是在时间收敛性上,CG花费的时间却十分大(100次样本测试的平均值)主要体现在500的时候(虽然老师没有要求500)。
- 矩阵生成的方法:
要求是A为正定对称矩阵,这个可以用二次型来实现A的生成
而为了满足雅可比的苛刻要求,即是(2*D-A)也要是正定矩阵,所以就只能进行判断,如果不成立就再次生成。
代码如下:
while 1
D = diag(rand(size_(i),1));
U = orth(rand(size_(i),size_(i)));
A = U' * D * U;
if ~isempty(find(eig(2*diag(diag(A))-A)<=0)) == 0
break;
end
end
- 求解矩阵的迭代法中:
迭代次数:CG < SOR < GausssSeidel < Jaccibi
而所有求解方程组的方法(在矩阵阶数比较大的时候):
时间消耗: SOR < GausssSeidel < Jaccibi < CG < Gauss_Solve < Row_pivot。 - 实际上这一次的作业很多是要进行统计分析的,所以大多数便进行了100次测试,但是觉得还有一些不足之处,比如松弛因子的常解,有时间在进行统计好了。希望跟自己预计的是一样的。加油。