DeepWalk阅读笔记
DeepWalk是一种学习网络中节点的表示的新的方法,是把language modeling的方法用在了social network里面,从而可以用deep learning的方法,不仅能表示节点,还能表示出节点之间的拓扑关系,也就是表现出社会网络的社会关系。如下图所示:
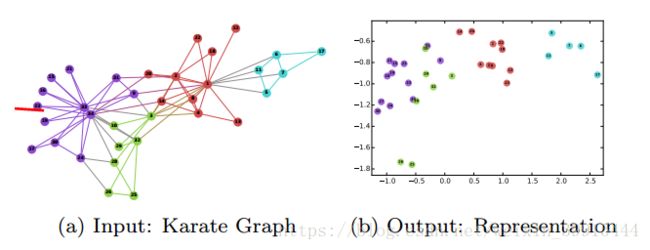
上图中在input中联系较为紧密的结点,映射到output中在空间上距离较近。
DeepWalk使用random walk的方法,random走过一串结点,产生一串结点组成的序列,等同于language modeling中的一个sentence,结点就等同于language modeling中的word。
为了证明DeepWalk用random walk可以借鉴language modeling的方法,做了一组对比,如下:

分布是大体相同的,所以可以用random walk来实现language modeling方法的迁移使用。
关于random walk:
产生的这个序列就可以当成language modeling里面的sentences,从而进行接下来的train,可以通过word2vec, 得到一个vector。
paper的详细内容:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Abstract:提出DeepWalk,一种学习结点的表示的新的方法, 它从random walk得到的信息中学习结点表示,通过把这些walk当成sentences,并且通过一些社会网络(Blog-Catalog,Flicker and YouTube)的一些multi-label network classification的任务来证明它的效果。
结果表明:DeepWalk相比于其他方法有更好的效果,特别是在信息缺失,labeled data稀疏,以及training data较少的时候。
DeepWalk是可扩展的(scalable),它是一个online的学习算法,仅需要local的信息,可以在后续有添加的新的信息的时候,无需从头学习,只需要学习新的结点的信息就可以了(因为使用了random walk)。它也是可并行的,也因为使用random walk,它可以同时从不同的结点处开始random walk从而开始学习的过程。
1. Introduction
contribution:
介绍了deep learning的方法来分析graph。
通过几个社交网络的multi-label classification的tasks验证DeepWalk的performance,在label稀疏以及train data少的时候,得到更好的performance
可扩展/可并行
2. Problem Definition
consider the problem of classifying members of a social network into one or more categories.
3. Learning Social Representations
关于language modeling和social network的联系,因为它们都是pow-law distribution, 所以可以进行迁移使用。
The goal of language modeling is estimate the likelihood of a specific sequence of words appearing in a corpus. 语言模型的目的是估计一串特定的单词出现在语料库的可能性。
These walks can be thought of short sentences and phrases in a special language. The direct analog is to estimate the likelihood of observing vertex vi given all the previous vertices visited so far in the random walk.(类比于语言模型,随机游走可以看成在一个特定语言里短的句子或者短语,我们要估计观察的结点的出现的可能性)
Our goal is to learn a latent representation, not only a probability distribution of node co-occurrences, and so we introduce a mapping function Φ. This mapping Φ represents the latent social representation associated with each vertex v in the graph. (我们的目标不仅是得到结点出现的概率分布,还要学习潜在的关系,所以我们用了一个映射函数,来表示潜在的社会关系表示)
但是,随着游走长度的增加,计算概率会变得困难,所以 采取以下方法:1:我们不用整个文本来predict一个缺失的word,而是用一个word来predict所有的文本,这也就是下面讲的SkipGram 2:文本要由给定单词的左边和右边的单词共同组成 3:去掉了顺序的约束
最后, 结合了随机游走和神经元语言模型,我们提出了一个可以满足我们的要求的方法。
这个方法生成低维度的社会网络的表示,在一个连续的向量空间里。
4. Method
在这一部分介绍了此算法的主要组成部分。
在所有语言模型的算法中,需要的输入是corpus和vocabulary,拓展到DeepWalk里,random walks是corpus,而给定的graph中的所有结点是vocabulary。
这个算法主要包括两个部分:一个是random walk generator 另一个是更新的过程。
For random walk part,我们生成像是language modeling中的句子中的一个序列,as input。
For update procedure,我们遍历所有的结点。
In the inner loop, we iterate over all the vertices of the graph. For each vertex vi we generate a random walk and then use it to update our representations. We use the SkipGram algorithm to update these representations in accordance with our objective function.
其中用到的方法有: SkipGram / Hierarchical Softmax(to speed the training time)/ Optimization(SGD and BP)。
最后提出了一些变式:Streaming/Non-Random Walks
5. Experimental Design
Datasets:BlogCatalog/Flickr/YouTube
用来与DeepWalk作对比的method:SpectralClustering/Modularity/EdgeCluster/wvRN/Majority
6. Experiments
分析实验结果,通过一些multi-label classification tasks,并且通过一些parameter(dimensionality/sampling frequency)分析它的sensitivity。
7. Related Work
DeepWalk和以前的方法的主要不同:
1. 学习了潜在的关系表示
2.
3. 大多数方法是需要global information,offline的,而我们的方法是仅需要local information,online的可扩展的。
4. 把非监督的表示学习应用到graph中。
8. Conclusion
本文介绍了一种新的社会网络中结点的表示方法--DeepWalk。DeepWalk使用了语言模型中的方法,深度学习。使用随机游走的方法产生一个序列可以等同于语言模型中的句子,而序列中的每个节点就等同于语言模型中的每个单词,通过一组YouTube社会网络和维基百科文本的对比证明了两者具有同样的分布,从而证明了可类比性。
然后为了证明这个方法的优越性,进行了和其他方法的对比试验,试验数据是来自三个社交网络的数据,对比结果可以看出这个方法在三个社交网络上都能取得比其他方法更好的效果,特别是在label较少的时候。
同时强调了DeepWalk是一个online的算法,具有可扩展性和可并行的特点。
这个算法在社会网络的结点表示中使用了Deep learning的方法,是一个重要的突破。
一些问题:
1. 了解Language Modeling
统计语言模型: 统计语言模型把语言(词的序列)看作一个随机事件,并赋予相应的概率来描述其属于某种语言集合的可能性。给定一个词汇集合 V,对于一个由 V 中的词构成的序列S = 〈w1, · · · , wT 〉 ∈ Vn,统计语言模型赋予这个序列一个概率P(S),来衡量S 符合自然语言的语法和语义规则的置信度。
简单来说,语言模型就是计算一个句子的概率大小的模型。
2. 为什么DeepWalk在数据缺失以及label较少的时候就能取得比较好的效果?
When labeled data is scarce, low dimensional models generalize better, and speed up
convergence and inference. 因为用的是distributed,映射到较低维,这个维度是预先设好的。
5. 关于 One-hot 和Distributed
NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representation,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。
例如:“话筒”表示为:[0,0,0,0,0,0,0,1,0,0,0,0.....]
“麦克”表示为:[0,0,1,0,0,0,0,0,0....]
任意两个词之间都是孤立的。光从这两个向量中看不出两个词是否有关系,哪怕是话筒和麦克这样的同义词也不能幸免于难。
one-hot具有维度过大的缺点,每个词语的维度就是语料库字典的长度。
Deep Learning 中一般用到的词向量(word embedding), 并不是刚才提到的用 One-hot Representation 表示的那种很长很长的词向量,而是用 Distributed Representation表示的一种低维实数向量。这种向量一般长成这个样子:[0.792, −0.177, −0.107, 0.109, −0.542, …]。维度以 50 维和 100 维比较常见。Distributed representation 最大的贡献就是让相关或者相似的词,在距离上更接近了。向量的距离可以用最传统的欧氏距离来衡量,也可以用 cos 夹角来衡量。
Distributed representation 用来表示词,通常被称为“Word Representation”或“Word Embedding”,中文俗称“词向量".
8. 降维是降到多少维?
自己设的
10. SkipGram 和 Hierarchical Softmax
Skip-Gram Model是根据某个词,然后分别计算它前后出现某几个词的各个概率。
Hierarchical Softmax用Huffman编码构造二叉树,其实借助了分类问题中,使用一连串二分类近似多分类的思想。
11. word2vec
生成 Distributed representation 形式的词向量,用的是word2vec的方法。
这里需要注意的就是V通常是一个很大的数比如几百万,计算起来相当费时间,除了“爱”那个位置的元素肯定要算在loss里面,word2vec就用基于huffman编码的Hierarchical softmax筛选掉了一部分不可能的词,然后又用nagetive samping再去掉了一些负样本的词
12. Word Embedding
将word映射到一个新的空间中,并以多维的连续实数向量进行表示叫做“Word Represention” 或 “Word Embedding”。自从21世纪以来,人们逐渐从原始的词向量稀疏表示法过渡到现在的低维空间中的密集表示。用稀疏表示法在解决实际问题时经常会遇到维数灾难,并且语义信息无法表示,无法揭示word之间的潜在联系。而采用低维空间表示法,不但解决了维数灾难问题,并且挖掘了word之间的关联属性,从而提高了向量语义上的准确度。
基于神经网络的分布表示一般称为词向量、词嵌入( word embedding)或分布式表示( distributed representation)。
如果要一句话概括词向量的用处,就是提供了一种数学化的方法,把自然语言这种符号信息转化为向量形式的数字信息。这样就把自然语言理解的问题要转化为机器学习的问题。
神经网络词向量表示技术通过神经网络技术对上下文,以及上下文与目标词之间的关系进行建模。由于神经网络较为灵活,这类方法的最大优势在于可以表示复杂的上下文。
Word embedding的训练方法大致可以分为两类:一类是无监督或弱监督的预训练;一类是端对端(end to end)的有监督训练。无监督或弱监督的预训练以word2vec和auto-encoder为代表。这一类模型的特点是,不需要大量的人工标记样本就可以得到质量还不错的embedding向量。不过因为缺少了任务导向,可能和我们要解决的问题还有一定的距离。因此,我们往往会在得到预训练的embedding向量后,用少量人工标注的样本去fine-tune整个模型。
词向量既能够降低维度,又能够capture到当前词在本句子中上下文的信息(表现为前后距离关系)
总结一下
Deep learning + NLP = DeepNLP
DeepNLP的核心就是语言表示,词的表示分为 one-hot representation 和 distributed representation
,而 distributed representation 又分为基于矩阵的、基于聚类的和基于神经网络的,基于神经网络的分布式表示就是 word embedding。所以 word embedding 是 distributed representation!
Word Embedding 分为无监督或弱监督的和有监督的,无监督或弱监督的预训练以word2vec和auto-encoder为代表
word2vec是个很棒的工具,目前有两种训练模型(CBOW和Skip-gram),两种加速算法(Negative Sample与Hierarchical Softmax)。
Conclusion:DeepWalk is a novel approach for learning latent representations of vertices in a network. Combined the random walk and language modeling, treat the sequences from random walks equal to the sentences in language modeling, the vertices are the same as words in language modeling. To prove the feasibility, compare the frequency in YouTube and Wikipedia. Then DeepWalk use the word2vec in language modeling, use skipgram to update the presentation and use the hierarchical softmax to speed up the process, to demonstrate the performance, do experiments on multi-lable classification tasks, the datasets from Youtube.. and compared with other methods, the results prove that deepwalk can achieve better performance.