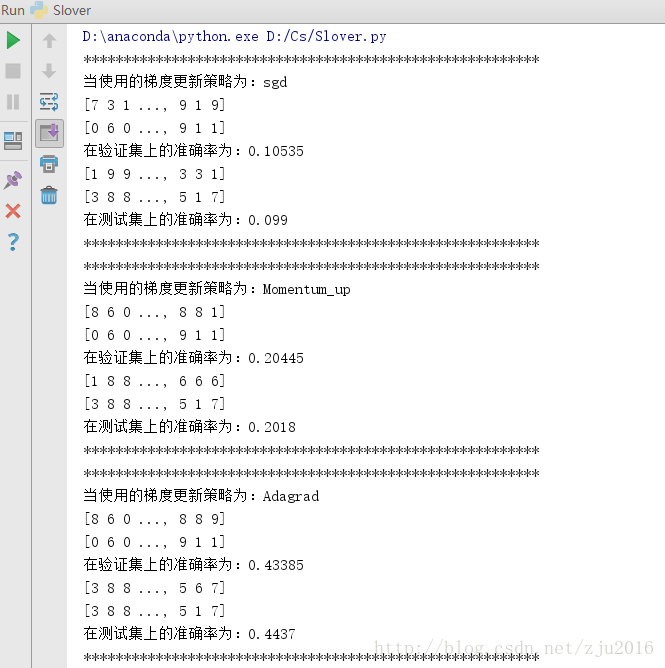
几种更新策略的比较
按照模块化编程,自己写了个全连接的神经网络,一共四个文件,具体介绍如下:
第一个文件是layers.py,具体实现的是简单的前向计算,relu函数的前向传播计算以及relu的反向传播计算:
import numpy as np
def simple_forward(x,w,b):
output=x.dot(w)+b
return output
def relu_func(x):
return np.maximum(x,0)
def relu_forward(x,w,b):
temp=simple_forward(x,w,b)
return relu_func(temp)
def relu_backward(dout,x,w,b):
dw=x.T.dot(dout)
db=np.sum(dout,axis=0)
dx=dout.dot(w.T)
return dx,dw,db第二个实现的文件是FullyConNet.py,主要完成的是对神经网络的初始化操作,以及前向计算、反向传播以及测试数据集的准确率函数:
import numpy as np
import Strategy as st
from layers import *
class FullyConNet:
lr_decay=0.95
iter_per_ann=400
parameter={}
layers=[]
weight_init=2e-2
update_rule=None
learning_rate=0
batch_size=0
epoch=0
reg=0
config={}
def __init__(self,input_layer,hidden_layer,output_layer,update_rule,learning_rate,batch_size,epoch,reg):
self.reg=reg
self.batch_size=batch_size
self.epoch=epoch
self.layers=[input_layer]+hidden_layer+[output_layer]
if(hasattr(st,update_rule)):
self.update_rule=getattr(st,update_rule)
length=len(hidden_layer)+1 #6
for i in range(0,length):#0,1,2,3,4,5
self.parameter['w'+str(i)]=self.weight_init*np.random.randn(self.layers[i],self.layers[i+1])
self.parameter['b'+str(i)]=np.zeros(self.layers[i+1])
for i in self.parameter:
self.config[i]={"learning_rate":learning_rate}
def forward_process(self,train_data,cache_output=None):
if(cache_output==None):
cache_output=[]
layers_len=len(self.layers)-1 #6
X=train_data
cache_output.append(X)
for i in range(0,layers_len-1):#0,1,2,3,4
temp_output=relu_forward(X,self.parameter['w'+str(i)],self.parameter['b'+str(i)])
cache_output.append(temp_output)
X=temp_output
ind=layers_len-1
X=simple_forward(X,self.parameter['w'+str(ind)],self.parameter['b'+str(ind)])
cache_output.append(X)
return X,cache_output
def backward_process(self,batch_size,train_label,cache_output):
temp_output=cache_output[-1] #取出最后一层的输出
temp_output = temp_output - np.max(temp_output, axis=1, keepdims=True)
temp_output = np.exp(temp_output)
total_output = np.sum(temp_output, axis=1, keepdims=True)
temp_output = temp_output / total_output
temp_output[range(batch_size),train_label]-=1
temp_output=temp_output/batch_size #平均化
dout=temp_output #求出微分
layer_num=len(self.layers)-1 #6
grads={}
for i in range(layer_num)[::-1]:#5, 4, 3,2,1, 0
input_data=cache_output[i]
dout,dw,db=relu_backward(dout,input_data,self.parameter['w'+str(i)],self.parameter['b'+str(i)])
dout[input_data<=0]=0
grads['w'+str(i)]=dw+self.reg*self.parameter['w'+str(i)]
grads['b'+str(i)]=db #记录梯度的变化,便于下一步的更新
for item in self.parameter:
new_item,new_config=self.update_rule(self.parameter[item],grads[item],self.config[item])
self.parameter[item]=new_item
self.config[item]=new_config
def Train(self,train_data,train_label):
total=train_data.shape[0]
iters_per_epoch=max(1,total/self.batch_size)
total_iters=int(iters_per_epoch*self.epoch)
for i in range(0,total_iters):
sample_ind=np.random.choice(total,self.batch_size,replace=True)
cur_train_data=train_data[sample_ind,:]
cur_train_label=train_label[sample_ind]
cache_output=[]
temp,cache_output=self.forward_process(cur_train_data,cache_output)
self.backward_process(self.batch_size,cur_train_label,cache_output)
if((i+1)%self.iter_per_ann==0):
for c in self.parameter:
self.config[c]['learning_rate']*=self.lr_decay
def Test(self,data,label):
cache_output=[]
res,cache_output=self.forward_process(data,cache_output)
ind_res=np.argmax(res,axis=1)
print(ind_res)
print(label)
return np.mean(ind_res==label)
第三个实现的就是各种的对权值不同的更新策略,通过运行各种不同的策略,可以看到他们在测试集上的表现:
import numpy as np
def adam(value,dvalue,config):
config.setdefault('eps',1e-8)
config.setdefault('beta1',0.9)
config.setdefault('beta2',0.999)
config.setdefault('learning_rate',9e-4)
t = config.get('t', 0)
v = config.get('v', np.zeros_like(value))
m = config.get('m', np.zeros_like(value))
beta1=config['beta1']
beta2=config['beta2']
eps=config['eps']
learning_rate=config['learning_rate']
t+=1
m=beta1*m+(1-beta1)*dvalue
mt=m/(1-beta1**t)
v=beta2*v+(1-beta2)*(dvalue**2)
vt=v/(1-beta2**t)
new_value=value-learning_rate*mt/(np.sqrt(vt)+eps)
config['t']=t
config['v']=v
config['m']=m
return new_value,config
def sgd(value,dvalue,config):
value=value-config['learning_rate']*dvalue
return value,config
def Momentum_up(value,dvalue,config):
learning_rate=config['learning_rate']
v=config.get('v',np.zeros_like(dvalue))
mu=config.get('mu',0.9)
v=mu*v-learning_rate*dvalue
value+=v
config['v']=v
config['mu']=mu
return value,config
def Adagrad(value,dvalue,config):
eps=config.get('eps',1e-6)
cache=config.get('cache',np.zeros_like(dvalue))
learning_rate=config['learning_rate']
cache+=dvalue**2
value=value-learning_rate*dvalue/(np.sqrt(cache)+eps)
config['eps']=eps
config['cache']=cache
return value,config
def RMSprop(value,dvalue,config):
decay_rate=config.get('decay_rate',0.99)
cache=config.get('cache',np.zeros_like(dvalue))
learning_rate=config['learning_rate']
eps=config.get('eps',1e-8)
cache=decay_rate*cache+(1-decay_rate)*(dvalue**2)
value=value-learning_rate*dvalue/(np.sqrt(cache)+eps)
config['cache']=cache
config['eps']=eps
config['decay_rate']=decay_rate
return value,config
最后实现的一个文件就是Solver.py文件,在该文件中实现对初始数据的读取,以及建立各种不同的模型,同时测试各种不同的模型在测试集合上的表现:
import numpy as np
import pickle as pic
from FullyConNet import *
class Solver:
input_layer=3072
hidden_layer=[100,100,100,100,100]
output_layer=10
train_data, train_label, validate_data, validate_label, test_data, test_label = [], [], [], [], [], []
def readData(self, file):
with open(file, 'rb') as fo:
dict = pic.load(fo, encoding='bytes')
return dict
def Init(self,path_train,path_test):
for i in range(1, 6):
cur_path = path_train + str(i)
read_temp = self.readData(cur_path)
if (i == 1):
self.train_data = read_temp[b'data']
self.train_label = read_temp[b'labels']
else:
self.train_data = np.append(self.train_data, read_temp[b'data'], axis=0)
self.train_label += read_temp[b'labels']
mean_image = np.mean(self.train_data, axis=0)
self.train_data = self.train_data - mean_image # 预处理
read_infor = self.readData(path_test)
self.train_label = np.array(self.train_label)
self.test_data = read_infor[b'data'] # 测试数据集
self.test_label = np.array(read_infor[b'labels']) # 测试标签
self.test_data = self.test_data - mean_image # 预处理
amount_train = self.train_data.shape[0]
amount_validate = 20000
amount_train -= amount_validate
self.validate_data = self.train_data[amount_train:, :] # 验证数据集
self.validate_label = self.train_label[amount_train:] # 验证标签
self.train_data = self.train_data[:amount_train, :] # 训练数据集
self.train_label = self.train_label[:amount_train] # 训练标签
def Train(self):
strategy=['sgd','Momentum_up','Adagrad','RMSprop','adam']
for s in strategy:
neuralNet=FullyConNet(self.input_layer,self.hidden_layer,self.output_layer,s,9e-4,250,10,0.0)
neuralNet.Train(self.train_data,self.train_label)
print("*********************************************************")
print("当使用的梯度更新策略为:"+s)
print("在验证集上的准确率为:"+str(neuralNet.Test(self.validate_data,self.validate_label)))
print("在测试集上的准确率为:"+str(neuralNet.Test(self.test_data,self.test_label)))
print("*********************************************************")
if __name__=='__main__':
a=Solver()
a.Init("D:\\data\\cifar-10-batches-py\\data_batch_",
"D:\\data\\cifar-10-batches-py\\test_batch")
a.Train()
运行的结果截图如下(输出中包含对于最终的测试集,对应的预测的标签号以及真实的标签号):