推荐系统
一、 项目系统架构
项目以推荐系统建设领域知名的经过修改过的 MovieLens 数据集作为依托,以某科技公司电影网站真实业务数据架构为基础,构建了符合教学体系的一体化的电 影推荐系统,
包含了离线推荐与实时推荐体系,综合利用了协同过滤算法以及基于 内容的推荐方法来提供混合推荐。提供了从前端应用、后台服务、算法设计实现等多方面实现

2 项目数据流图

2.1 系统初始化部分
- 通过 Spark SQL 将系统初始化数据加载到 MongoDB 和 ElasticSearch 中。
2.2 离线推荐部分
- 离线统计服务:从 MongoDB 中加载数据,将【电影平均评分统计】、【电影评分个数统计】、【最近电影评分个数统计】三个统计算法进行运行实现,并将计算结果回 写到 MongoDB 中;
- 离线推荐服务:从 MongoDB 中加载数据,通过 ALS 算法分别将【用户推荐结果矩阵】、【影片相似度矩阵】回写到 MongoDB 中
2.3 实时推荐部分
- Flume 从综合业务服务的运行日志中读取日志更新,并将更新的日志实时推送到Kafka 中;
- Kafka 在收到这些日志之后,通过 kafkaStream 程序对获取的日志信息进行 过滤处理,获取用户评分数据流【UID|MID|SCORE|TIMESTAMP】,并发送到另外一 个 Kafka 队列;
- Spark Streaming 监听 Kafka 队列,实时获取 Kafka 过滤出来的用户评 分数据流,融合存储在 Redis 中的用户最近评分队列数据,提交给实时推荐算法, 完成对用户新的推荐结果计算;
- 计算完成之后,将新的推荐结构和 MongDB 数据库中的推荐结果进行合并。
2.4 业务系统部分
- 推荐结果展示部分,从 MongoDB、ElasticSearch 中将离线推荐结果、实时推荐结果、 内容推荐结果进行混合,综合给出相对应的数据。
- 电影信息查询服务通过对接 MongoDB 实现对电影信息的查询操作。
- 电影评分部分,获取用户通过 UI 给出的评分动作,后台服务进行数据库记录后,一 方面将数据推动到 Redis 群中,另一方面,通过预设的日志框架输出到 Tomcat 中的日志中。
- 项目通过 ElasticSearch 实现对电影的模糊检索。
- 电影标签部分,项目提供用户对电影打标签服务。
3. 项目初始介绍
- 启动服务后初次使用, 需要注册用户

- 用户注册成功之后

- 无数据页面

- 各项推荐业务完成之后

4、数据模型
4.1 Movie 电影数据表
/**
e.g.
Movie 数据集有 10 个字段,每个字段之间通过“^”符号进行分割。
mid,name,descri,timelong,issue,shoot,language,genres,actors,direc tors
1^Toy Story (1995)^ ^81 minutes^March 20, 2001^1995^English ^Adventure|Animation|Children|Comedy|Fantasy ^Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn|John Ratzenberger|Annie Potts|John Morris|Erik von Detten|Laurie Metcalf|R. Lee Ermey|Sarah Freeman|Penn Jillette|Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn ^John Lasseter
* Movie 数据集
* 260 电影ID,mid
* Star Wars: Episode IV - A New Hope (1977) 电影名称,name
* Princess Leia is captured and held hostage 详情描述,descri
* 121 minutes 时长,timelong
* September 21, 2004 发行时间,issue
* 1977 拍摄时间,shoot
* English 语言,language
* Action|Adventure|Sci-Fi 类型,genres
* Mark Hamill|Harrison Ford|Carrie Fisher 演员表,actors
* George Lucas 导演,directors
*/
case class Movie(mid: Int, name: String, descri: String, timelong: String, issue: String,
shoot: String, language: String, genres: String, actors: String, directors: String)
4.2 Rating 用户评分表
/**
* Rating数据集
* 1,31,2.5,1260759144
*/
case class Rating(uid: Int, mid: Int, score: Double, timestamp: Int )
4.3 Tag 电影标签表
/**
* Tag数据集
* 15,1955,dentist,1193435061
*/
case class Tag(uid: Int, mid: Int, tag: String, timestamp: Int)
4.4 User 用户表
{
"_id" : ObjectId("5e0057a2c0fe231b78308655"),
"uid" : 273892982,
"username" : "[email protected]",
"password" : "123456",
"first" : false,
"timestamp" : NumberLong("1577080738010"),
"prefGenres" : [
"Action",
"Crime",
"Romance"
]
}
4.5 RateMoreMoviesRecently 最近电影评分个数统计表
{
"_id" : ObjectId("5e005bcdc0fe231b964ec528"),
"mid" : 1527,
"count" : NumberLong(2),
"yearmonth" : 201604
}
4.6 RateMoreMovies 电影评分个数统计表
{
"_id" : ObjectId("5e005bc6c0fe231b964eba7c"),
"mid" : 1975,
"count" : NumberLong(9)
}
4.7 AverageMoviesScore 电影平均评分表
{
"_id" : ObjectId("5e005bcfc0fe231b964f4961"),
"mid" : 130580,
"avg" : 3.5
}
4.8 MovieRecs 电影相似度矩阵
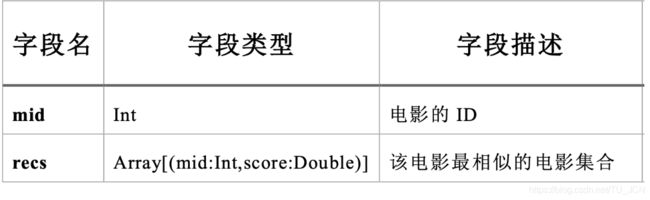
4.9 UserRecs 用户电影推荐矩阵

4.10 StreamRecs 用户实时电影推荐矩阵

二、项目准备
1. 环境准备
- 安装mongo
[root@cdh1 ~]$ wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel62-3. 4.3.tgz
# 将压缩包解压到指定目录
[root@cdh1 /opt/]$ tar -xf mongodb-linux-x86_64-rhel62-3.4.3.tgz -C ~/
# 将解压后的文件移动到最终的安装目录
[root@cdh1 ~]$ mv mongodb-linux-x86_64-rhel62-3.4.3/ /usr/local/mongodb
# 在安装目录下创建 data 文件夹用于存放数据和日志
[root@cdh1 mongodb]$ mkdir /usr/local/mongodb/data/
# 在 data 文件夹下创建 db 文件夹,用于存放数据
[root@cdh1 mongodb]$ mkdir /usr/local/mongodb/data/db/
# 在 data 文件夹下创建 logs 文件夹,用于存放日志
[root@cdh1 mongodb]$ mkdir /usr/local/mongodb/data/logs/
# 在 logs 文件夹下创建 log 文件
[root@cdh1 mongodb]$ touch /usr/local/mongodb/data/logs/mongodb.log
# 在 data 文件夹下创建 mongodb.conf 配置文件 [root@cdh1 mongodb]$ touch
/usr/local/mongodb/data/mongodb.conf
# 在 mongodb.conf 文件中输入如下内容
[root@cdh1 mongodb]$ vim ./data/mongodb.conf
#端口号 port = 27017
#数据目录
dbpath = /usr/local/mongodb/data/db
#日志目录
logpath = /usr/local/mongodb/data/logs/mongodb.log
#设置后台运行
fork = true
#日志输出方式
logappend = true
#开启认证
#auth = true
完成 MongoDB 的安装后,启动 MongoDB 服务器:
# 启动 MongoDB 服务器
[root@cdh1 mongodb]$ sudo /usr/local/mongodb/bin/mongod -config/usr/local/mongodb/data/mongodb.conf
# 访问 MongoDB 服务器
[root@cdh1 mongodb]$ /usr/local/mongodb/bin/mongo
# 停止 MongoDB 服务器
[root@cdh1 mongodb]$ sudo /usr/local/mongodb/bin/mongod -shutdown -config/usr/local/mongodb/data/mongodb.conf
- 安装Redis
# 通过 WGET 下载 REDIS 的源码
[bigdata@linux ~]$wget http://download.redis.io/releases/redis-4.0.2.tar.gz
# 将源代码解压到安装目录
[bigdata@linux ~]$ tar -xf redis-4.0.2.tar.gz -C ~/
# 进入 Redis 源代码目录,编译安装
[bigdata@linux ~]$ cd redis-4.0.2/
# 安装 GCC
[bigdata@linux ~]$ sudo yum install gcc
# 编译源代码
[bigdata@linux redis-4.0.2]$ make MALLOC=libc
# 编译安装
[bigdata@linux redis-4.0.2]$ sudo make install
# 创建配置文件
[bigdata@linux redis-4.0.2]$ sudo cp ~/redis-4.0.2/redis.conf /etc/
# 修改配置文件中以下内容
[bigdata@linux redis-4.0.2]$ sudo vim /etc/redis.conf
daemonize yes #37 行 #是否以后台 daemon 方式运行,默认不是后台运行
pidfile /var/run/redis/redis.pid #41 行 #redis 的 PID 文件路径(可选)
bind 0.0.0.0 #64 行 #绑定主机 IP,默认值为 127.0.0.1,我们是跨机器运行,所 以需要更改
logfile /var/log/redis/redis.log #104 行 #定义 log 文件位置,模式 log 信息定向到 stdout,输出到/dev/null(可选)
dir “/usr/local/rdbfile” #188 行 #本地数据库存放路径,默认为./,编译 安装默认存在在/usr/local/bin 下(可选)
在安装完 Redis 之后,启动 Redis
# 启动 Redis 服务器
[bigdata@linux redis-4.0.2]$ redis-server /etc/redis.conf
# 连接 Redis 服务器
[bigdata@linux redis-4.0.2]$ redis-cli
# 停止 Redis 服务器
[bigdata@linux redis-4.0.2]$ redis-cli shutdown
2. 创建项目
2.1 创建Maven项目
- 打开idea, 创建一个Maven项目, 命名为MovieRecommendSystem, 为了方便 后期的联调,我们会把业务系统的代码也添加进来,所以我们可以以 MovieRecommendSystem 作为父项目,并在其下建一个名为 recommender 的子项目, 然后再在下面搭建多个子项目用于提供不同的推荐服务。
2.2 项目框架搭建
在 MovieRecommendSystem 的 pom.xml 文 件 中 加 入 元 素 pom,然后新建一个 maven module 作为子项目,命名为 Recommender。同样的,再以 Recommender 为父项目,在它的 pom.xml 中加入 pom,然后新建一个 maven module 作为子项目。我们的第一 步是初始化业务数据,所以子项目命名为 DataLoader。父项目只是为了规范化项目结构,方便依赖管理,本身是不需要代码实现的,所以 MovieRecommendSystem 和 Recommender 下的 src 文件夹都可以删掉。

2.3 声明项目中工具的版本信息
我们整个项目需要用到多个工具,它们的不同版本可能会对程序运行造成影响,所以应该在最外层的 MovieRecommendSystem 中声明所有子项目共用的版本信息。 在 pom.xml 中加入以下配置:
修改: MovieRecommendSystem/pom.xml
1.2.17
1.7.22
2.0.0
3.1.1
6.4.3
6.4.3
2.9.0
0.10.2.1
2.1.1
2.11.8
1.2.1
2.4 添加项目依赖
- 首先,对于整个项目而言,应该有同样的日志管理,我们在MovieRecommendSystem 中引入公有依赖
修改: MovieRecommendSystem/pom.xml
org.slf4j
jcl-over-slf4j
${slf4j.version}
org.slf4j
slf4j-api
${slf4j.version}
org.slf4j
slf4j-log4j12
${slf4j.version}
log4j
log4j
${log4j.version}
- 同样,对于 maven 项目的构建,可以引入公有的插件:
修改: MovieRecommendSystem/pom.xml
org.apache.maven.plugins
maven-compiler-plugin
3.6.1
1.8
1.8
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
make-assembly
package
single
net.alchim31.maven
scala-maven-plugin
3.2.2
compile
testCompile
- 然后,在 Recommender 模块中,我们可以为所有的推荐模块声明 spark 相关依 赖(这里的 dependencyManagement 表示仅声明相关信息,子项目如果依赖需要自行 引入):
MovieRecommendSystem/Recommender/pom.xml
org.apache.spark
spark-core_2.11
${spark.version}
org.apache.spark
spark-sql_2.11
${spark.version}
org.apache.spark
spark-streaming_2.11
${spark.version}
org.apache.spark
spark-mllib_2.11
${spark.version}
org.apache.spark
spark-graphx_2.11
${spark.version}
org.scala-lang
scala-library
${scala.version}
- 由于各推荐模块都是 scala 代码,还应该引入 scala-maven-plugin 插件,用于 scala 程序的编译。因为插件已经在父项目中声明,所以这里不需要再声明版本和具体配 置:
net.alchim31.maven
scala-maven-plugin
- 对于具体的 DataLoader 子项目,需要 spark 相关组件,还需要 mongodb、elastic search 的相关依赖,我们在 pom.xml 文件中引入所有依赖(在父项目中已声明的不 需要再加详细信息):
MovieRecommendSystem/Recommender/DataLoader/pom.xml
org.apache.spark
spark-core_2.11
org.apache.spark
spark-sql_2.11
org.scala-lang
scala-library
org.mongodb
casbah-core_2.11
${casbah.version}
org.mongodb.spark
mongo-spark-connector_2.11
${mongodb-spark.version}
org.elasticsearch.client
transport
${elasticsearch.version}
org.elasticsearch
elasticsearch-spark-20_2.11
${elasticsearch-spark.version}
org.apache.hive
hive-service
2.5 数据加载准备
-
在 src/main/目录下,可以看到已有的默认源文件目录是 java,我们可以将其改 名为 scala。将数据文件 movies.csv,ratings.csv,tags.csv 复制到资源文件目录 src/main/resources 下,我们将从这里读取数据并加载到 mongodb 和 elasticsearch 中。
-
日志管理配置文件, log4j 对日志的管理,需要通过配置文件来生效。在 src/main/resources 下新建配
置文件 log4j.properties,写入以下内容:
-
log4j.rootLogger=info, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%n
三、数据加载
1 启动mongo
2. 数据加载程序主体实现
我们会为原始数据定义几个样例类,
通过 SparkContext 的 textFile 方法从文件 中读取数据,并转换成 DataFrame,
再利用 Spark SQL 提供的 write 方法进行数据的 分布式插入。
在 DataLoader/src/main/scala 下新建 package,命名为 com.kkb.recommender, 新建名为 DataLoader 的 scala class 文件。
程序主体如下
DataLoader/src/main/scala/com.kkb.recommerder/DataLoader.scala
/**
* Movie 数据集
*
* 260 电影ID,mid
* Star Wars: Episode IV - A New Hope (1977) 电影名称,name
* Princess Leia is captured and held hostage 详情描述,descri
* 121 minutes 时长,timelong
* September 21, 2004 发行时间,issue
* 1977 拍摄时间,shoot
* English 语言,language
* Action|Adventure|Sci-Fi 类型,genres
* Mark Hamill|Harrison Ford|Carrie Fisher 演员表,actors
* George Lucas 导演,directors
*
*/
case class Movie(mid: Int, name: String, descri: String, timelong: String, issue: String,
shoot: String, language: String, genres: String, actors: String, directors: String)
/**
* Rating数据集
*
* 1,31,2.5,1260759144
*/
case class Rating(uid: Int, mid: Int, score: Double, timestamp: Int )
/**
* Tag数据集
*
* 15,1955,dentist,1193435061
*/
case class Tag(uid: Int, mid: Int, tag: String, timestamp: Int)
// 把mongo和es的配置封装成样例类
/**
*
* @param uri MongoDB连接
* @param db MongoDB数据库
*/
case class MongoConfig(uri:String, db:String)
/**
*
* @param httpHosts http主机列表,逗号分隔
* @param transportHosts transport主机列表
* @param index 需要操作的索引
* @param clustername 集群名称,默认elasticsearch
*/
case class ESConfig(httpHosts:String, transportHosts:String, index:String, clustername:String)
object DataLoader {
// 定义常量
val MOVIE_DATA_PATH = "/Users/xingyeah/Desktop/workspace/MovieSystemRecommender/recomonder/dataLoader/src/main/resources/movies.csv"
val RATING_DATA_PATH = "/Users/xingyeah/Desktop/workspace/MovieSystemRecommender/recomonder/dataLoader/src/main/resources/ratings.csv"
val TAG_DATA_PATH = "/Users/xingyeah/Desktop/workspace/MovieSystemRecommender/recomonder/dataLoader/src/main/resources/tags.csv"
val MONGODB_MOVIE_COLLECTION = "Movie"
val MONGODB_RATING_COLLECTION = "Rating"
val MONGODB_TAG_COLLECTION = "Tag"
val ES_MOVIE_INDEX = "Movie"
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://cdh1:27017/recommender",
"mongo.db" -> "recommender",
"es.httpHosts" -> "cdh1:9200",
"es.transportHosts" -> "cdh1:9300",
"es.index" -> "recommender",
"es.cluster.name" -> "cluster_es"
)
// 创建一个sparkConf
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("DataLoader")
// 创建一个SparkSession
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
// 加载数据
val movieRDD = spark.sparkContext.textFile(MOVIE_DATA_PATH)
val movieDF = movieRDD.map(
item => {
val attr = item.split("\\^")
Movie(attr(0).toInt, attr(1).trim, attr(2).trim, attr(3).trim, attr(4).trim, attr(5).trim, attr(6).trim, attr(7).trim, attr(8).trim, attr(9).trim)
}
).toDF()
val ratingRDD = spark.sparkContext.textFile(RATING_DATA_PATH)
val ratingDF = ratingRDD.map(item => {
val attr = item.split(",")
Rating(attr(0).toInt,attr(1).toInt,attr(2).toDouble,attr(3).toInt)
}).toDF()
val tagRDD = spark.sparkContext.textFile(TAG_DATA_PATH)
//将tagRDD装换为DataFrame
val tagDF = tagRDD.map(item => {
val attr = item.split(",")
Tag(attr(0).toInt,attr(1).toInt,attr(2).trim,attr(3).toInt)
}).toDF()
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
// 将数据保存到MongoDB
storeDataInMongoDB(movieDF, ratingDF, tagDF)
// 数据预处理,把movie对应的tag信息添加进去,加一列 tag1|tag2|tag3...
import org.apache.spark.sql.functions._
/**
* mid, tags
*
* tags: tag1|tag2|tag3...
*/
val newTag = tagDF.groupBy($"mid")
.agg( concat_ws( "|", collect_set($"tag") ).as("tags") )
.select("mid", "tags")
// newTag和movie做join,数据合并在一起,左外连接
val movieWithTagsDF = movieDF.join(newTag, Seq("mid"), "left")
implicit val esConfig = ESConfig(config("es.httpHosts"), config("es.transportHosts"), config("es.index"), config("es.cluster.name"))
// 保存数据到ES
storeDataInES(movieWithTagsDF)
spark.stop()
}
}
3. 将数据写入到Mongo
def storeDataInMongoDB(movieDF: DataFrame, ratingDF: DataFrame, tagDF: DataFrame)(implicit mongoConfig: MongoConfig): Unit ={
// 新建一个mongodb的连接
val mongoClient = MongoClient(MongoClientURI(mongoConfig.uri))
// 如果mongodb中已经有相应的数据库,先删除
mongoClient(mongoConfig.db)(MONGODB_MOVIE_COLLECTION).dropCollection()
mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION).dropCollection()
mongoClient(mongoConfig.db)(MONGODB_TAG_COLLECTION).dropCollection()
// 将DF数据写入对应的mongodb表中
movieDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_MOVIE_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
ratingDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_RATING_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
tagDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_TAG_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
//对数据表建索引
mongoClient(mongoConfig.db)(MONGODB_MOVIE_COLLECTION).createIndex(MongoDBObject("mid" -> 1))
mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION).createIndex(MongoDBObject("uid" -> 1))
mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION).createIndex(MongoDBObject("mid" -> 1))
mongoClient(mongoConfig.db)(MONGODB_TAG_COLLECTION).createIndex(MongoDBObject("uid" -> 1))
mongoClient(mongoConfig.db)(MONGODB_TAG_COLLECTION).createIndex(MongoDBObject("mid" -> 1))
mongoClient.close()
}
4. 将数据写入到elasticsearch
4.1 启动elasticsearch 服务器
4.2 代码相关
def storeDataInES(movieDF: DataFrame)(implicit eSConfig: ESConfig): Unit ={
// 新建es配置
val settings: Settings = Settings.builder().put("cluster.name", eSConfig.clustername).build()
// 新建一个es客户端
val esClient = new PreBuiltTransportClient(settings)
val REGEX_HOST_PORT = "(.+):(\\d+)".r
eSConfig.transportHosts.split(",").foreach{
case REGEX_HOST_PORT(host: String, port: String) => {
esClient.addTransportAddress(new TransportAddress( InetAddress.getByName(host), port.toInt ))
}
}
// 先清理遗留的数据
if( esClient.admin().indices().exists( new IndicesExistsRequest(eSConfig.index) )
.actionGet()
.isExists
){
esClient.admin().indices().delete( new DeleteIndexRequest(eSConfig.index) )
}
esClient.admin().indices().create( new CreateIndexRequest(eSConfig.index) )
movieDF.write
.option("es.nodes", eSConfig.httpHosts)
.option("es.http.timeout", "100m")
.option("es.mapping.id", "mid")
.mode("overwrite")
.format("org.elasticsearch.spark.sql")
.save(eSConfig.index + "/" + ES_MOVIE_INDEX)
}
注: 完整代码
package com.kkb.recommender
import java.net.InetAddress
import com.mongodb.casbah.commons.MongoDBObject
import com.mongodb.casbah.{MongoClient, MongoClientURI}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.elasticsearch.action.admin.indices.create.CreateIndexRequest
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest
import org.elasticsearch.action.admin.indices.exists.indices.IndicesExistsRequest
import org.elasticsearch.common.settings.Settings
import org.elasticsearch.common.transport.TransportAddress
import org.elasticsearch.transport.client.PreBuiltTransportClient
/**
* Movie 数据集
*
* 260 电影ID,mid
* Star Wars: Episode IV - A New Hope (1977) 电影名称,name
* Princess Leia is captured and held hostage 详情描述,descri
* 121 minutes 时长,timelong
* September 21, 2004 发行时间,issue
* 1977 拍摄时间,shoot
* English 语言,language
* Action|Adventure|Sci-Fi 类型,genres
* Mark Hamill|Harrison Ford|Carrie Fisher 演员表,actors
* George Lucas 导演,directors
*
*/
case class Movie(mid: Int, name: String, descri: String, timelong: String, issue: String,
shoot: String, language: String, genres: String, actors: String, directors: String)
/**
* Rating数据集
*
* 1,31,2.5,1260759144
*/
case class Rating(uid: Int, mid: Int, score: Double, timestamp: Int )
/**
* Tag数据集
*
* 15,1955,dentist,1193435061
*/
case class Tag(uid: Int, mid: Int, tag: String, timestamp: Int)
// 把mongo和es的配置封装成样例类
/**
*
* @param uri MongoDB连接
* @param db MongoDB数据库
*/
case class MongoConfig(uri:String, db:String)
/**
*
* @param httpHosts http主机列表,逗号分隔
* @param transportHosts transport主机列表
* @param index 需要操作的索引
* @param clustername 集群名称,默认elasticsearch
*/
case class ESConfig(httpHosts:String, transportHosts:String, index:String, clustername:String)
object DataLoader {
// 定义常量
val MOVIE_DATA_PATH = "/Users/xingyeah/Desktop/workspace/MovieSystemRecommender/recomonder/dataLoader/src/main/resources/movies.csv"
val RATING_DATA_PATH = "/Users/xingyeah/Desktop/workspace/MovieSystemRecommender/recomonder/dataLoader/src/main/resources/ratings.csv"
val TAG_DATA_PATH = "/Users/xingyeah/Desktop/workspace/MovieSystemRecommender/recomonder/dataLoader/src/main/resources/tags.csv"
val MONGODB_MOVIE_COLLECTION = "Movie"
val MONGODB_RATING_COLLECTION = "Rating"
val MONGODB_TAG_COLLECTION = "Tag"
val ES_MOVIE_INDEX = "Movie"
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://cdh1:27017/recommender",
"mongo.db" -> "recommender",
"es.httpHosts" -> "cdh1:9200",
"es.transportHosts" -> "cdh1:9300",
"es.index" -> "recommender",
"es.cluster.name" -> "cluster_es"
)
// 创建一个sparkConf
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("DataLoader")
// 创建一个SparkSession
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
// 加载数据
val movieRDD = spark.sparkContext.textFile(MOVIE_DATA_PATH)
val movieDF = movieRDD.map(
item => {
val attr = item.split("\\^")
Movie(attr(0).toInt, attr(1).trim, attr(2).trim, attr(3).trim, attr(4).trim, attr(5).trim, attr(6).trim, attr(7).trim, attr(8).trim, attr(9).trim)
}
).toDF()
val ratingRDD = spark.sparkContext.textFile(RATING_DATA_PATH)
val ratingDF = ratingRDD.map(item => {
val attr = item.split(",")
Rating(attr(0).toInt,attr(1).toInt,attr(2).toDouble,attr(3).toInt)
}).toDF()
val tagRDD = spark.sparkContext.textFile(TAG_DATA_PATH)
//将tagRDD装换为DataFrame
val tagDF = tagRDD.map(item => {
val attr = item.split(",")
Tag(attr(0).toInt,attr(1).toInt,attr(2).trim,attr(3).toInt)
}).toDF()
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
// 将数据保存到MongoDB
storeDataInMongoDB(movieDF, ratingDF, tagDF)
// 数据预处理,把movie对应的tag信息添加进去,加一列 tag1|tag2|tag3...
import org.apache.spark.sql.functions._
/**
* mid, tags
* 为了将数据存储到es中,方便通过标签检索, 可以在存储到es之前, 对数据做一些预处理,把movie对应的tag信息添加进去, 加一列 tag1|tag2|tag3
* 先按照mid进行分组选出电影的所有tag(聚合), 添加到movieDF应该是一个join操作
* 需要有一堆的算子, 按照mid做一个聚合, 然后用竖线分割联接在一起
* 所以我们先将sparksql里面的所有的函数导进来
* tags: tag1|tag2|tag3...
*/
val newTag = tagDF.groupBy($"mid")
.agg( concat_ws( "|", collect_set($"tag") ).as("tags") )
.select("mid", "tags")
// newTag和movie做join,数据合并在一起,左外连接
val movieWithTagsDF = movieDF.join(newTag, Seq("mid"), "left")
//和之前的mongo一样, 定义一个隐式的es配置参数
implicit val esConfig = ESConfig(config("es.httpHosts"), config("es.transportHosts"), config("es.index"), config("es.cluster.name"))
// 保存数据到ES
storeDataInES(movieWithTagsDF)
spark.stop()
}
def storeDataInMongoDB(movieDF: DataFrame, ratingDF: DataFrame, tagDF: DataFrame)(implicit mongoConfig: MongoConfig): Unit ={
// 新建一个mongodb的连接
val mongoClient = MongoClient(MongoClientURI(mongoConfig.uri))
// 如果mongodb中已经有相应的数据库,先删除
mongoClient(mongoConfig.db)(MONGODB_MOVIE_COLLECTION).dropCollection()
mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION).dropCollection()
mongoClient(mongoConfig.db)(MONGODB_TAG_COLLECTION).dropCollection()
// 将DF数据写入对应的mongodb表中
movieDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_MOVIE_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
ratingDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_RATING_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
tagDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_TAG_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
//对数据表建索引
mongoClient(mongoConfig.db)(MONGODB_MOVIE_COLLECTION).createIndex(MongoDBObject("mid" -> 1))
mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION).createIndex(MongoDBObject("uid" -> 1))
mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION).createIndex(MongoDBObject("mid" -> 1))
mongoClient(mongoConfig.db)(MONGODB_TAG_COLLECTION).createIndex(MongoDBObject("uid" -> 1))
mongoClient(mongoConfig.db)(MONGODB_TAG_COLLECTION).createIndex(MongoDBObject("mid" -> 1))
mongoClient.close()
}
def storeDataInES(movieDF: DataFrame)(implicit eSConfig: ESConfig): Unit ={
// 新建es配置
val settings: Settings = Settings.builder().put("cluster.name", eSConfig.clustername).build()
// 新建一个es客户端
val esClient = new PreBuiltTransportClient(settings)
val REGEX_HOST_PORT = "(.+):(\\d+)".r
eSConfig.transportHosts.split(",").foreach{
case REGEX_HOST_PORT(host: String, port: String) => {
// esClient.addTransportAddress(new InetSocketTransportAddress( InetAddress.getByName(host), port.toInt ))
esClient.addTransportAddress(new TransportAddress( InetAddress.getByName(host), port.toInt ))
}
}
// 先清理遗留的数据
if( esClient.admin().indices().exists( new IndicesExistsRequest(eSConfig.index) )
.actionGet()
.isExists
){
esClient.admin().indices().delete( new DeleteIndexRequest(eSConfig.index) )
}
esClient.admin().indices().create( new CreateIndexRequest(eSConfig.index) )
// 将movingDF写入到对应的index中去
movieDF.write
.option("es.nodes", eSConfig.httpHosts)
.option("es.http.timeout", "100m")
.option("es.mapping.id", "mid")
.mode("overwrite")
.format("org.elasticsearch.spark.sql")
.save(eSConfig.index + "/" + ES_MOVIE_INDEX)
}
}三、离线推荐
1、合并业务系统
1.1. 添加业务系统
-
将businessServer文件夹所有内容拷贝到MovieRecommendSystem目录下, 与Recommender同级
-
修改MovieRecommendSystem/pom.xml文件
- 修改businessServer/pom.xml文件,artifactId和groupId需要和MovieRecommendSystem/pom.xml保持一致
1.2. 运行业务系统
Maven --> businessServer --> Plugins --> tomcat7 --> tomcat:run 双击
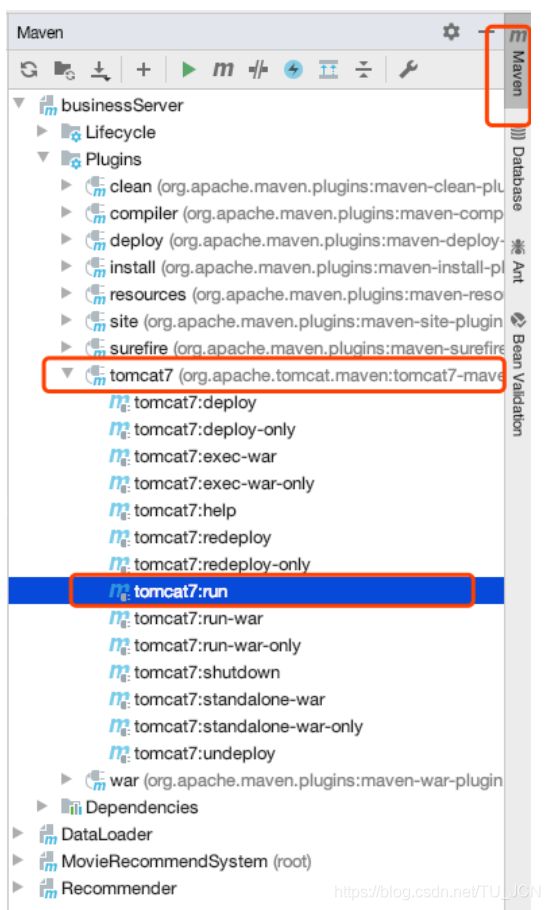
等待服务器启动之后, 在浏览器输入 localhost:8080/index.html, 即可访问业务系统

2、统计推荐(非个性化)
-
离线推荐服务是综合用户所有的历史数据,利用设定的离线统计算法和离线推 荐算法周期性的进行结果统计与保存,计算的结果在一定时间周期内是固定不变的, 变更的频率取决于算法调度的频率。
-
离线推荐服务主要计算一些可以预先进行统计和计算的指标,为实时计算和前 端业务相应提供数据支撑。
-
离线推荐服务主要分为统计性算法、基于 ALS 的协同过滤推荐算法以及基于 ElasticSearch 的内容推荐算法。
2.1 创建离线推荐模块
在 recommender 下新建子项目 StatisticsRecommender,pom.xml 文件中只需引入 spark、scala 和 mongodb 的相关依赖:
org.apache.spark
spark-core_2.11
org.apache.spark
spark-sql_2.11
org.scala-lang
scala-library
org.mongodb
casbah-core_2.11
${casbah.version}
org.mongodb.spark
mongo-spark-connector_2.11
${mongodb-spark.version}
2 添加日志配置文件
在 resources 文件夹下引入 log4j.properties,然后在 src/main/scala 下新建 scala 单例对象com.kkb.statistics.StatisticsRecommender。
3 创建项目文件StatisticsRecommender
- 在 resources 文件夹下引入 log4j.properties,然后在 src/main/scala 下新建 scala 单 例对象 com.kkb.statistics.StatisticsRecommender
- 定义样例类
- 创建sparkSession并加载数据
- 关闭spark
添加样例类: src/main/scala/com.kkb.statistics/StatisticsRecommender.scala:
// 2. 近期热门统计,按照“yyyyMM”格式选取最近的评分数据,统计评分个数
// 创建一个日期格式化工具
val simpleDateFormat = new SimpleDateFormat("yyyyMM")
// 注册udf,把时间戳转换成年月格式
spark.udf.register("changeDate", (x: Int) => simpleDateFormat.format(new Date(x * 1000L)).toInt)
// 对原始数据做预处理,去掉uid
val ratingOfYearMonth = spark.sql("select mid, score, changeDate(timestamp) as yearmonth from ratings")
ratingOfYearMonth.createOrReplaceTempView("ratingOfMonth")
// 从ratingOfMonth中查找电影在各个月份的评分,mid,count,yearmonth
val rateMoreRecentlyMoviesDF = spark.sql("select mid, count(mid) as count, yearmonth from ratingOfMonth group by yearmonth, mid order by yearmonth desc, count desc")
// 存入mongodb
storeDFInMongoDB(rateMoreRecentlyMoviesDF, RATE_MORE_RECENTLY_MOVIES)
4.3 电影平均得分统计
[基准对象]
根据历史数据中所有用户对电影的评分,周期性的计算每个电影的平均得分。
实现思路:
通过 Spark SQL 读取保存在 MongDB 中的 Rating 数据集,通过执行 SQL 语 句实现对于电影的平均分统计
// 3. 优质电影统计,统计电影的平均评分,mid,avg
val averageMoviesDF = spark.sql("select mid, avg(score) as avg from ratings group by mid")
storeDFInMongoDB(averageMoviesDF, AVERAGE_MOVIES)
4.4 每个类别优质电影统计
sci-fi: [基准对象]
根据提供的所有电影类别,分别计算每种类型的电影集合中评分最高的 10 个电影。 实现思路:
在计算完整个电影的平均得分之后,将影片集合与电影类型做笛卡尔积,然后 过滤掉电影类型不符合的条目,将 DataFrame 输出到 MongoDB 的 GenresTopMovies 集合中。
// 4. 各类别电影Top统计
// 定义所有类别
val genres = List("Action", "Adventure", "Animation", "Comedy", "Crime", "Documentary", "Drama", "Family", "Fantasy", "Foreign", "History", "Horror", "Music", "Mystery"
, "Romance", "Science", "Tv", "Thriller", "War", "Western")
// 把平均评分加入movie表里,加一列,inner join
val movieWithScore = movieDF.join(averageMoviesDF, "mid")
// 为做笛卡尔积,把genres转成rdd
val genresRDD = spark.sparkContext.makeRDD(genres)
// 计算类别top10,首先对类别和电影做笛卡尔积
val genresTopMoviesDF = genresRDD.cartesian(movieWithScore.rdd)
.filter {
// 条件过滤,找出movie的字段genres值(Action|Adventure|Sci-Fi)包含当前类别genre(Action)的那些
case (genre, movieRow) => movieRow.getAs[String]("genres").toLowerCase.contains(genre.toLowerCase)
}
.map {
case (genre, movieRow) => (genre, (movieRow.getAs[Int]("mid"), movieRow.getAs[Double]("avg")))
}
.groupByKey()
.map {
case (genre, items) => GenresRecommendation(genre, items.toList.sortWith(_._2 > _._2).take(10).map(item => Recommendation(item._1, item._2)))
}
.toDF()
storeDFInMongoDB(genresTopMoviesDF, GENRES_TOP_MOVIES)
注: 完整代码
package com.kkb.static
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* Movie 数据集
*
* 260 电影ID,mid
* Star Wars: Episode IV - A New Hope (1977) 电影名称,name
* Princess Leia is captured and held hostage 详情描述,descri
* 121 minutes 时长,timelong
* September 21, 2004 发行时间,issue
* 1977 拍摄时间,shoot
* English 语言,language
* Action|Adventure|Sci-Fi 类型,genres
* Mark Hamill|Harrison Ford|Carrie Fisher 演员表,actors
* George Lucas 导演,directors
*
*/
case class Movie(mid: Int, name: String, descri: String, timelong: String, issue: String,
shoot: String, language: String, genres: String, actors: String, directors: String)
/**
* Rating数据集
*
* 1,31,2.5,1260759144
*/
case class Rating(uid: Int, mid: Int, score: Double, timestamp: Int)
case class MongoConfig(uri: String, db: String)
// 定义一个基准推荐对象
case class Recommendation(mid: Int, score: Double)
// 定义电影类别top10推荐对象
case class GenresRecommendation(genres: String, recs: Seq[Recommendation])
object StaticRecommender {
// 定义表名
val MONGODB_MOVIE_COLLECTION = "Movie"
val MONGODB_RATING_COLLECTION = "Rating"
//统计的表的名称
val RATE_MORE_MOVIES = "RateMoreMovies"
val RATE_MORE_RECENTLY_MOVIES = "RateMoreRecentlyMovies"
val AVERAGE_MOVIES = "AverageMovies"
val GENRES_TOP_MOVIES = "GenresTopMovies"
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://cdh1:27017/recommender",
"mongo.db" -> "recommender"
)
// 创建一个sparkConf
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("StatisticsRecommeder")
// 创建一个SparkSession
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
// 从mongodb加载数据
val ratingDF = spark.read
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_RATING_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[Rating]
.toDF()
val movieDF = spark.read
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_MOVIE_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[Movie]
.toDF()
// 创建名为ratings的临时表
ratingDF.createOrReplaceTempView("ratings")
// 不同的统计推荐结果
// 1. 历史热门统计,历史评分数据最多,mid,count
val rateMoreMoviesDF = spark.sql("select mid, count(mid) as count from ratings group by mid")
// 把结果写入对应的mongodb表中
storeDFInMongoDB(rateMoreMoviesDF, RATE_MORE_MOVIES)
// 2. 近期热门统计,按照“yyyyMM”格式选取最近的评分数据,统计评分个数
// 创建一个日期格式化工具
val simpleDateFormat = new SimpleDateFormat("yyyyMM")
// 注册udf,把时间戳转换成年月格式
spark.udf.register("changeDate", (x: Int) => simpleDateFormat.format(new Date(x * 1000L)).toInt)
// 对原始数据做预处理,去掉uid
val ratingOfYearMonth = spark.sql("select mid, score, changeDate(timestamp) as yearmonth from ratings")
ratingOfYearMonth.createOrReplaceTempView("ratingOfMonth")
// 从ratingOfMonth中查找电影在各个月份的评分,mid,count,yearmonth
val rateMoreRecentlyMoviesDF = spark.sql("select mid, count(mid) as count, yearmonth from ratingOfMonth group by yearmonth, mid order by yearmonth desc, count desc")
// 存入mongodb
storeDFInMongoDB(rateMoreRecentlyMoviesDF, RATE_MORE_RECENTLY_MOVIES)
// 3. 优质电影统计,统计电影的平均评分,mid,avg
val averageMoviesDF = spark.sql("select mid, avg(score) as avg from ratings group by mid")
storeDFInMongoDB(averageMoviesDF, AVERAGE_MOVIES)
// 4. 各类别电影Top统计
// 定义所有类别
val genres = List("Action", "Adventure", "Animation", "Comedy", "Crime", "Documentary", "Drama", "Family", "Fantasy", "Foreign", "History", "Horror", "Music", "Mystery"
, "Romance", "Science", "Tv", "Thriller", "War", "Western")
// 把平均评分加入movie表里,加一列,inner join
val movieWithScore = movieDF.join(averageMoviesDF, "mid")
// 为做笛卡尔积,把genres转成rdd
val genresRDD = spark.sparkContext.makeRDD(genres)
// 计算类别top10,首先对类别和电影做笛卡尔积
val genresTopMoviesDF = genresRDD.cartesian(movieWithScore.rdd)
.filter {
// 条件过滤,找出movie的字段genres值(Action|Adventure|Sci-Fi)包含当前类别genre(Action)的那些
case (genre, movieRow) => movieRow.getAs[String]("genres").toLowerCase.contains(genre.toLowerCase)
}
.map {
case (genre, movieRow) => (genre, (movieRow.getAs[Int]("mid"), movieRow.getAs[Double]("avg")))
}
.groupByKey()
.map {
case (genre, items) => GenresRecommendation(genre, items.toList.sortWith(_._2 > _._2).take(10).map(item => Recommendation(item._1, item._2)))
}
.toDF()
storeDFInMongoDB(genresTopMoviesDF, GENRES_TOP_MOVIES)
spark.stop()
}
def storeDFInMongoDB(df: DataFrame, collection_name: String)(implicit mongoConfig: MongoConfig): Unit = {
df.write
.option("uri", mongoConfig.uri)
.option("collection", collection_name)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
}
}
添加样例类: src/main/scala/com.kkb.statistics/StatisticsRecommender.scala:
case class Movie(mid: Int, name: String, descri: String, timelong: String, issue: String, shoot: String, language: String, genres: String, actors: String, directors: String)
case class Rating(uid: Int, mid: Int, score: Double, timestamp: Int)
case class MongoConfig(uri:String, db:String)
// 定义一个基准推荐对象
case class Recommendation(mid: Int, score: Double)
// 定义电影类别top10推荐对象
case class GenresRecommendation(genres: String, recs: Seq[Recommendation])
object StaticRecommender {
// 定义表名
val MONGODB_MOVIE_COLLECTION = "Movie"
val MONGODB_RATING_COLLECTION = "Rating"
//统计的表的名称
val RATE_MORE_MOVIES = "RateMoreMovies"
val RATE_MORE_RECENTLY_MOVIES = "RateMoreRecentlyMovies"
val AVERAGE_MOVIES = "AverageMovies"
val GENRES_TOP_MOVIES = "GenresTopMovies"
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://cdh1:27017/recommender",
"mongo.db" -> "recommender"
)
// 创建一个sparkConf
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("StatisticsRecommeder")
// 创建一个SparkSession
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
// 从mongodb加载数据
val ratingDF = spark.read
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_RATING_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[Rating]
.toDF()
val movieDF = spark.read
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_MOVIE_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[Movie]
.toDF()
// 创建名为ratings的临时表
ratingDF.createOrReplaceTempView("ratings")
//TODO: 不同的统计推荐结果
spark.stop()
}
4 离线统计服务
4.1 历史热门电影统计
根据所有历史评分数据,计算历史评分次数最多的电影。
实现思路:
通过 Spark SQL 读取评分数据集,统计所有评分中评分数最多的电影,然后按 照从大到小排序,将最终结果写入 MongoDB 的 RateMoreMovies 数据集中。
//统计所有历史数据中每个电影的评分数
//数据结构 -》 mid,count
// 1. 历史热门统计,历史评分数据最多,mid,count
val rateMoreMoviesDF = spark.sql("select mid, count(mid) as count from ratings group by mid")
storeDFInMongoDB(rateMoreMoviesDF, RATE_MORE_MOVIES)
4.2 封装存储数据的统一方法
def storeDFInMongoDB(df: DataFrame, collection_name: String)(implicit mongoConfig: MongoConfig): Unit = {
df.write
.option("uri", mongoConfig.uri)
.option("collection", collection_name)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
}
4.2 最近热门电影统计
根据评分,按月为单位计算最近时间的月份里面评分数最多的电影集合。
实现思路:
通过 Spark SQL 读取评分数据集,通过 UDF 函数将评分的数据时间修改为月, 然后统计每月电影的评分数。统计完成之后将数据写入到 MongoDB 的 RateMoreRecentlyMovies 数据集中。
-
离线推荐服务是综合用户所有的历史数据,利用设定的离线统计算法和离线推 荐算法周期性的进行结果统计与保存,计算的结果在一定时间周期内是固定不变的, 变更的频率取决于算法调度的频率。
-
离线推荐服务主要计算一些可以预先进行统计和计算的指标,为实时计算和前 端业务相应提供数据支撑。
-
离线推荐服务主要分为统计性算法、基于 ALS 的协同过滤推荐算法以及基于 ElasticSearch 的内容推荐算法。
- 在 recommender 下新建子项目 StatisticsRecommender,pom.xml 文件中只需引入 spark、scala 和 mongodb 的相关依赖:
- 在 resources 文件夹下引入 log4j.properties,然后在 src/main/scala 下新建 scala 单 例对象 com.kkb.statistics.StatisticsRecommender
- 定义样例类
- 创建sparkSession并加载数据
- 关闭spark
- Introduction
- 1. 推荐系统项目
- 1.1. 项目搭建
- 1.2. 数据介绍
- 2. 加载数据
- 2.1. 创建项目
- 2.2. 读取数据
- 3. 离线推荐
- 3.1. 添加业务系统
- 3.2. 统计推荐
- 3.3. 基于内容推荐
- 3.4. 隐语义协同过滤推荐
- 4. 实时推荐
- 4.1. 实时推荐服务建设
- 4.2. 实时推荐联调
- Published with GitBook
课程概述
[TOC]
推荐系统相关算法
1. 基于内容的推荐算法
- Content-based Recommendations (CB)根据推荐物品或内容的元数据,发现物品的相关性,再基于用户过去的喜好记录,为用户推荐相似的物品。
- 通过抽取物品内在或者外在的特征值,实现相似度计算。
- 比如一个电影,有导演、演员、用户标签UGC、用户评论、时长、风格等等,都可以算是特征。
- 将用户(user) 个人信息的特征(基 于喜好记录或是预设兴趣标签),和物品(item)的特征相匹配,就能得到用户对物品感兴趣的程度
- 在一-些电影、音乐、图书的社交网站有很成功的应用,有些网站还请专业的人员对物品进行基因编码/打标签(PGC)
1.1 基于内容推荐算法的数据获取和预处理
-
对于物品的特征提取- -- 打标签(tag)
-
专家标签(PGC)
-
用户自定义标签(UGC)
-
降维分析数据,提取隐语义标签(LFM)
-
-
对于文本信息的特征提取- --关键词
-
分词、语义处理和情感分析(NLP)
-
潜在语义分析(LSA)
-
1.2 相似度计算
相似度的评判,可以用距离表示,而一般更常用的是“余弦相似度”
- 欧式距离
- 余弦相似度
2 基于协同过滤和基于内容过滤的区别
基于内容 (Content based, CB)主要利用的是用户评价过的物品的内容特征,而CF方法还可以利用其他用户评分过的物品内容
- CF 可以解决CB的一些局限
- 物品内容不完全或者难以获得时,依然可以通过其他用户的反馈给出推荐
- CF基于用户 之间对物品的评价质量,避免了CB仅依赖内容可能造成的对物品质量 判断的干扰
- CF推荐不受内容限制, 只要其他类似用户给出了对不同物品的兴趣,CF就可以给 用户推荐出内容差异很大的物品(但有 某种内在联系)分为两类:基于近邻和基于模型
- 分为两类
- 基于近邻
- 基于模型
3 代码实现
package com.kkb.content
import org.apache.spark.SparkConf
import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer}
import org.apache.spark.ml.linalg.SparseVector
import org.apache.spark.sql.SparkSession
import org.jblas.DoubleMatrix
// 需要的数据源是电影内容信息
case class Movie(mid: Int, name: String, descri: String, timelong: String, issue: String,
shoot: String, language: String, genres: String, actors: String, directors: String)
case class MongoConfig(uri:String, db:String)
// 定义一个基准推荐对象
case class Recommendation( mid: Int, score: Double )
// 定义电影内容信息提取出的特征向量的电影相似度列表
case class MovieRecs( mid: Int, recs: Seq[Recommendation] )
object ContentRecommender {
// 定义表名和常量
val MONGODB_MOVIE_COLLECTION = "Movie"
val CONTENT_MOVIE_RECS = "ContentMovieRecs"
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://cdh1:27017/recommender",
"mongo.db" -> "recommender"
)
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("OfflineRecommender")
// 创建一个SparkSession
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
// 加载数据,并作预处理
val movieTagsDF = spark.read
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_MOVIE_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[Movie]
.map(
// 提取mid,name,genres三项作为原始内容特征,分词器默认按照空格做分词
x => ( x.mid, x.name, x.genres.map(c=> if(c=='|') ' ' else c) )
)
.toDF("mid", "name", "genres")
.cache()
// 核心部分: 用TF-IDF从内容信息中提取电影特征向量
// 创建一个分词器,默认按空格分词
val tokenizer = new Tokenizer().setInputCol("genres").setOutputCol("words")
// 用分词器对原始数据做转换,生成新的一列words
val wordsData = tokenizer.transform(movieTagsDF)
//可以显示wordsData
// wordsData.show()
// 引入HashingTF工具,可以把一个词语序列转化成对应的词频
val hashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(50)
val featurizedData = hashingTF.transform(wordsData)
// 引入IDF工具,可以得到idf模型
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
// 训练idf模型,得到每个词的逆文档频率
val idfModel = idf.fit(featurizedData)
// 用模型对原数据进行处理,得到文档中每个词的tf-idf,作为新的特征向量
val rescaledData = idfModel.transform(featurizedData)
// rescaledData.show(truncate = false)
val movieFeatures = rescaledData.map(
row => ( row.getAs[Int]("mid"), row.getAs[SparseVector]("features").toArray )
)
.rdd
.map(
x => ( x._1, new DoubleMatrix(x._2) )
)
movieFeatures.collect().foreach(println)
// 对所有电影两两计算它们的相似度,先做笛卡尔积
val movieRecs = movieFeatures.cartesian(movieFeatures)
.filter{
// 把自己跟自己的配对过滤掉
case (a, b) => a._1 != b._1
}
.map{
case (a, b) => {
val simScore = this.consinSim(a._2, b._2)
( a._1, ( b._1, simScore ) )
}
}
.filter(_._2._2 > 0.6) // 过滤出相似度大于0.6的
.groupByKey()
.map{
case (mid, items) => MovieRecs( mid, items.toList.sortWith(_._2 > _._2).map(x => Recommendation(x._1, x._2)) )
}
.toDF()
movieRecs.write
.option("uri", mongoConfig.uri)
.option("collection", CONTENT_MOVIE_RECS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
spark.stop()
}
// 求向量余弦相似度
def consinSim(movie1: DoubleMatrix, movie2: DoubleMatrix):Double ={
movie1.dot(movie2) / ( movie1.norm2() * movie2.norm2() )
}
}
分词之后的数据
TF 转换之后的数据
计算得到的 tf-idf的值
协同过滤推荐(CF)
通过 ALS 训练出来的 Model 来计算所有当前用户电影的推荐矩阵,主要思路如下:
- UserId 和 MovieID 做笛卡尔积,产生(uid,mid)矩阵 (空矩阵)
- 通过模型预测(uid,mid)的元组。
- 将预测结果通过预测分值进行排序。
- 返回分值最大的 K 个电影,作为当前用户的推荐。
最后生成数据结构如下: 将数据保存到MongoDB的UserRecs表中
2. 代码实现
2.1 新建 recommender 的子项目 OfflineRecommender,引入 spark、scala、mongo 和 jblas 的依赖:
org.scalanlp
jblas
${jblas.version}
org.apache.spark
spark-core_2.11
org.apache.spark
spark-sql_2.11
org.apache.spark
spark-mllib_2.11
org.scala-lang
scala-library
org.mongodb
casbah-core_2.11
${casbah.version}
org.mongodb.spark
mongo-spark-connector_2.11
${mongodb-spark.version}
3. 加载数据计算模型
同样经过前期的构建样例类、声明配置、创建 SparkSession 等步骤,可以加载 数据开始计算模型了。
src/main/scala/com.kkb.offline/OfflineRecommender.scala
package com.kkb.offline
import org.apache.spark.SparkConf
import org.apache.spark.mllib.recommendation.{ALS, Rating}
import org.apache.spark.sql.SparkSession
import org.jblas.DoubleMatrix
// 基于评分数据的LFM,只需要rating数据
case class MovieRating(uid: Int, mid: Int, score: Double, timestamp: Int )
case class MongoConfig(uri:String, db:String)
// 定义一个基准推荐对象
case class Recommendation( mid: Int, score: Double )
// 定义基于预测评分的用户推荐列表
case class UserRecs( uid: Int, recs: Seq[Recommendation] )
// 定义基于LFM电影特征向量的电影相似度列表
case class MovieRecs( mid: Int, recs: Seq[Recommendation] )
object OfflineRecommender {
// 定义表名和常量
val MONGODB_RATING_COLLECTION = "Rating"
val USER_RECS = "UserRecs"
val MOVIE_RECS = "MovieRecs"
val USER_MAX_RECOMMENDATION = 20
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://cdh1:27017/recommender",
"mongo.db" -> "recommender"
)
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("OfflineRecommender")
// 创建一个SparkSession
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
// 加载数据
val ratingRDD = spark.read
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_RATING_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[MovieRating]
.rdd
.map( rating => ( rating.uid, rating.mid, rating.score ) ) // 转化成rdd,并且去掉时间戳
.cache()
// 训练隐语义模型
val trainData = ratingRDD.map( x => Rating(x._1, x._2, x._3) )
val (rank, iterations, lambda) = (200, 5, 0.05)
val model = ALS.train(trainData, rank, iterations, lambda)
println("++++++++++++++++++++++++++++")
// 从rating数据中提取所有的uid和mid,并去重
val userRDD = ratingRDD.map(_._1).distinct()
val movieRDD = ratingRDD.map(_._2).distinct()
// 基于用户和电影的隐特征,计算预测评分,得到用户的推荐列表
// 计算user和movie的笛卡尔积,得到一个空评分矩阵
val userMovies = userRDD.cartesian(movieRDD)
// 调用model的predict方法预测评分
val preRatings = model.predict(userMovies)
val userRecs = preRatings
.filter(_.rating > 0) // 过滤出评分大于0的项
.map(rating => ( rating.user, (rating.product, rating.rating) ) )
.groupByKey()
.map{
case (uid, recs) => UserRecs( uid, recs.toList.sortWith(_._2>_._2).take(USER_MAX_RECOMMENDATION).map(x=>Recommendation(x._1, x._2)) )
}
.toDF()
println("++++++++++++++++++++++++++++")
userRecs.write
.option("uri", mongoConfig.uri)
.option("collection", USER_RECS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
// 基于电影隐特征,计算相似度矩阵,得到电影的相似度列表
val movieFeatures = model.productFeatures.map{
case (mid, features) => (mid, new DoubleMatrix(features))
}
// 对所有电影两两计算它们的相似度,先做笛卡尔积
val movieRecs = movieFeatures.cartesian(movieFeatures)
.filter{
// 把自己跟自己的配对过滤掉
case (a, b) => a._1 != b._1
}
.map{
case (a, b) => {
val simScore = this.consinSim(a._2, b._2)
( a._1, ( b._1, simScore ) )
}
}
.filter(_._2._2 > 0.6) // 过滤出相似度大于0.6的
.groupByKey()
.map{
case (mid, items) => MovieRecs( mid, items.toList.sortWith(_._2 > _._2).map(x => Recommendation(x._1, x._2)) )
}
.toDF()
println(movieRecs, "++++++++++++++++++++++++++++")
movieRecs.write
.option("uri", mongoConfig.uri)
.option("collection", MOVIE_RECS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
spark.stop()
}
// 求向量余弦相似度
def consinSim(movie1: DoubleMatrix, movie2: DoubleMatrix):Double ={
movie1.dot(movie2) / ( movie1.norm2() * movie2.norm2() )
}
}
- Introduction
- 1. 推荐系统项目
- 1.1. 项目搭建
- 1.2. 数据介绍
- 2. 加载数据
- 2.1. 创建项目
- 2.2. 读取数据
- 3. 离线推荐
- 3.1. 添加业务系统
- 3.2. 统计推荐
- 3.3. 基于内容推荐
- 3.4. 隐语义协同过滤推荐
- 4. 实时推荐
- 4.1. 实时推荐服务建设
- 4.2. 实时推荐联调
- Published with GitBook
课程概述
实时推荐服务
1. 实时推荐算法设计
当用户 u 对电影 p 进行了评分,将触发一次对 u 的推荐结果的更新。由于用 户 u 对电影 p 评分,对于用户 u 来说,他与 p 最相似的电影们之间的推荐强度将 发生变化,所以选取与电影 p 最相似的 K 个电影作为候选电影。
每个候选电影按照“推荐优先级”这一权重作为衡量这个电影被推荐给用户 u 的优先级。
这些电影将根据用户 u 最近的若干评分计算出各自对用户 u 的推荐优先级,然 后与上次对用户 u 的实时推荐结果的进行基于推荐优先级的合并、替换得到更新后 的推荐结果。
具体来说: 首先,获取用户 u 按时间顺序最近的 K 个评分,记为 RK;获取电影 p 的最
相似的 K 个电影集合,记为 S; 然后,对于每个电影 q S ,计算其推荐优先级 ,计算公式如下:
把相似度和评分结合起来做一个加权操作先拿到最近的K个评分, 另外拿到和当前评分的电影相似的电影作为备选, 有一个备选电影列表接下来考察每一个备选电影, 按照模型给一个推荐评分,就是把备选电影和最近评分过的电影挨个做比对, 他俩是不是可以从相似度矩阵中取出他们的相似度, 他俩的相似度再乘以最近评分过的电影的评分是不是就相当于做了加权, 最后求和之后再除以评分过的个数, 是不是做了一个加权的平均数啊, 这就是我们最后推荐分数的基准项, 最后还有两个偏移项, 分别是奖励和惩罚
基本实现流程如下:
代码实现
- 新建StreamingRecommender模块, 配置pom.xml文件, 并且引入log4j.properties文件
- 修改java -> scala
- 创建实时推荐scala文件 com.kkb.stream.StreamingRecommender
StreamingRecommender/pom.xml文件
org.apache.spark
spark-core_2.11
org.apache.spark
spark-sql_2.11
org.apache.spark
spark-streaming_2.11
org.scala-lang
scala-library
org.mongodb
casbah-core_2.11
${casbah.version}
org.mongodb.spark
mongo-spark-connector_2.11
${mongodb-spark.version}
redis.clients
jedis
2.9.0
org.apache.kafka
kafka-clients
0.10.2.1
org.apache.spark
spark-streaming-kafka-0-10_2.11
${spark.version}
项目代码
package com.kkb.streaming
import com.mongodb.casbah.commons.MongoDBObject
import com.mongodb.casbah.{MongoClient, MongoClientURI}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import redis.clients.jedis.Jedis
// 定义连接助手对象,序列化
object ConnHelper extends Serializable{
val jedis = new Jedis("cdh1" , 6379)
lazy val mongoClient = MongoClient( MongoClientURI("mongodb://cdh1:27017/recommender") )
}
case class MongoConfig(uri:String, db:String)
// 定义一个基准推荐对象
case class Recommendation( mid: Int, score: Double )
// 定义基于预测评分的用户推荐列表
case class UserRecs( uid: Int, recs: Seq[Recommendation] )
// 定义基于LFM电影特征向量的电影相似度列表
case class MovieRecs( mid: Int, recs: Seq[Recommendation] )
object StreamingRecommender {
val MAX_USER_RATINGS_NUM = 20
val MAX_SIM_MOVIES_NUM = 20
val MONGODB_STREAM_RECS_COLLECTION = "StreamRecs"
val MONGODB_RATING_COLLECTION = "Rating"
val MONGODB_MOVIE_RECS_COLLECTION = "MovieRecs"
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://cdh1:27017/recommender",
"mongo.db" -> "recommender",
"kafka.topic" -> "recommender"
)
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("StreamingRecommender")
sparkConf.registerKryoClasses(Array(classOf[MongoConfig], classOf[Recommendation], classOf[UserRecs], classOf[MovieRecs]))
// 创建一个SparkSession
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
// 拿到streaming context
val sc = spark.sparkContext
val ssc = new StreamingContext(sc, Seconds(2)) // batch duration
import spark.implicits._
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
// 加载电影相似度矩阵数据,把它广播出去 , 一个excutor上留存一个副本, 不会在每个任务上都保存副本, 比较节省内存资源
val simMovieMatrix = spark.read
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_MOVIE_RECS_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[MovieRecs]
.rdd
.map{ movieRecs => // 为了查询相似度方便,转换成map, 一个mid, 一个列表, 但是查询速度不够快, 将每一个元素转换成为map就能够查询更快一些, 整体转换成map
(movieRecs.mid, movieRecs.recs.map( x=> (x.mid, x.score) ).toMap )
}.collectAsMap() // 整体转为map
// 定义广播变量, 将数据广播出去
val simMovieMatrixBroadCast = sc.broadcast(simMovieMatrix)
// 定义kafka连接参数
val kafkaParam = Map(
"bootstrap.servers" -> "cdh1:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "recommender",
"auto.offset.reset" -> "latest"
)
// 通过kafka创建一个DStream
val kafkaStream = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent, // 偏向连续的策略
// 根据kafkaParam创建一个消费者, 订阅了我们的topic, 如果kafka那边来数据, 我们这边就可以获取到了, 就把数据打通了
ConsumerStrategies.Subscribe[String, String](Array(config("kafka.topic")), kafkaParam) // param1: topic列表, kafka的配置项
)
// 把原始数据UID|MID|SCORE|TIMESTAMP 转换成评分流
val ratingStream = kafkaStream.map{
msg =>
val attr = msg.value().split("\\|")
( attr(0).toInt, attr(1).toInt, attr(2).toDouble, attr(3).toInt )
}
// 继续做流式处理,核心实时算法部分
ratingStream.foreachRDD{
//rdds, 是某一个时间窗口中的一组rdd
rdds => rdds.foreach{ // feach 遍历, 获取rdd的具体类容
case (uid, mid, score, timestamp) => {
println("rating data coming! >>>>>>>>>>>>>>>>")
// 1. 从redis里获取当前用户最近的K次评分,保存成Array[(mid, score)]
val userRecentlyRatings = getUserRecentlyRating( MAX_USER_RATINGS_NUM, uid, ConnHelper.jedis )
// 2. 从相似度矩阵中取出当前电影最相似的N个电影,作为备选列表,Array[mid]
val candidateMovies = getTopSimMovies( MAX_SIM_MOVIES_NUM, mid, uid, simMovieMatrixBroadCast.value )
// 3. 对每个备选电影,计算推荐优先级,得到当前用户的实时推荐列表,Array[(mid, score)]
val streamRecs = computeMovieScores( candidateMovies, userRecentlyRatings, simMovieMatrixBroadCast.value )
// 4. 把推荐数据保存到mongodb
saveDataToMongoDB( uid, streamRecs )
println("<<<<<<<<<<<<<<<<< rating data coming! >>>>>>>>>>>>>>>>")
}
}
}
// 开始接收和处理数据
ssc.start()
println("+++++++++++++++++ streaming started! +++++++++++++++++++")
ssc.awaitTermination() // 一直等待处理, 除非手动停止或者异常退出
}
// redis操作返回的是java类,为了用map操作需要引入转换类
import scala.collection.JavaConversions._
def getUserRecentlyRating(num: Int, uid: Int, jedis: Jedis): Array[(Int, Double)] = {
val jedis1 = new Jedis("cdh1" , 6379)
jedis1.select(2)
// 从redis读取数据,用户评分数据保存在 uid:UID 为key的队列里,value是 MID:SCORE
jedis1.lrange("uid:" + uid, 0, num-1)
.map{
item => // 具体每个评分又是以冒号分隔的两个值
val attr = item.split("\\:")
( attr(0).trim.toInt, attr(1).trim.toDouble )
}
.toArray
}
/**
* 获取跟当前电影做相似的num个电影,作为备选电影
* @param num 相似电影的数量
* @param mid 当前电影ID
* @param uid 当前评分用户ID
* @param simMovies 相似度矩阵
* @return 过滤之后的备选电影列表
*/
def getTopSimMovies(num: Int, mid: Int, uid: Int, simMovies: scala.collection.Map[Int, scala.collection.immutable.Map[Int, Double]])
(implicit mongoConfig: MongoConfig): Array[Int] ={
// 1. 从相似度矩阵中拿到所有相似的电影
val allSimMovies = simMovies(mid).toArray
// 2. 从mongodb中查询用户已看过的电影
val ratingExist = ConnHelper.mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION)
.find( MongoDBObject("uid" -> uid) )
.toArray
.map{
item => item.get("mid").toString.toInt
}
// 3. 把看过的过滤,得到输出列表
allSimMovies.filter( x=> ! ratingExist.contains(x._1) )
.sortWith(_._2>_._2)
.take(num)
.map(x=>x._1)
}
// 对每个备选电影,计算推荐优先级,得到当前用户的实时推荐列表
def computeMovieScores(candidateMovies: Array[Int],
userRecentlyRatings: Array[(Int, Double)],
simMovies: scala.collection.Map[Int, scala.collection.immutable.Map[Int, Double]]): Array[(Int, Double)] ={
// 定义一个ArrayBuffer,用于保存每一个备选电影的基础得分
val scores = scala.collection.mutable.ArrayBuffer[(Int, Double)]()
// 定义一个HashMap,保存每一个备选电影的增强减弱因子
val increMap = scala.collection.mutable.HashMap[Int, Int]()
val decreMap = scala.collection.mutable.HashMap[Int, Int]()
for( candidateMovie <- candidateMovies; userRecentlyRating <- userRecentlyRatings){
// 拿到备选电影和最近评分电影的相似度
val simScore = getMoviesSimScore( candidateMovie, userRecentlyRating._1, simMovies )
println(s"当前评分:${simScore}")
if(simScore > 0.7){
// 计算备选电影的基础推荐得分
scores += ( (candidateMovie, simScore * userRecentlyRating._2) )
if( userRecentlyRating._2 > 3 ){
//若果大于3, 就应该以备选电影的mid作为key 去存一个值, 这个值给多少呢
increMap(candidateMovie) = increMap.getOrDefault(candidateMovie, 0) + 1
} else{
decreMap(candidateMovie) = decreMap.getOrDefault(candidateMovie, 0) + 1
}
}
}
// 根据备选电影的mid做groupby,根据公式去求最后的推荐评分
scores.groupBy(_._1).map{
// groupBy之后得到的数据 Map( mid -> ArrayBuffer[(mid, score)] )
case (mid, scoreList) =>
( mid, scoreList.map(_._2).sum / scoreList.length + log(increMap.getOrDefault(mid, 1)) - log(decreMap.getOrDefault(mid, 1)) )
}.toArray.sortWith(_._2>_._2)
}
// 获取两个电影之间的相似度
def getMoviesSimScore(mid1: Int, mid2: Int, simMovies: scala.collection.Map[Int,
scala.collection.immutable.Map[Int, Double]]): Double ={
simMovies.get(mid1) match {
case Some(sims) => sims.get(mid2) match {
case Some(score) => score
case None => 0.0
}
case None => 0.0
}
}
// 求一个数的对数,利用换底公式,底数默认为10
def log(m: Int): Double ={
val N = 10
math.log(m)/ math.log(N)
}
def saveDataToMongoDB(uid: Int, streamRecs: Array[(Int, Double)])(implicit mongoConfig: MongoConfig): Unit ={
// 定义到StreamRecs表的连接
val streamRecsCollection = ConnHelper.mongoClient(mongoConfig.db)(MONGODB_STREAM_RECS_COLLECTION)
// 如果表中已有uid对应的数据,则删除
streamRecsCollection.findAndRemove( MongoDBObject("uid" -> uid) )
// 将streamRecs数据存入表中
streamRecsCollection.insert(
MongoDBObject( "uid"->uid, "recs"-> streamRecs.map(x=>MongoDBObject( "mid"->x._1, "score"->x._2 ))
)
)
}
}
实时系统联调
我们的系统实时推荐的数据流向是:业务系统 -> 日志 -> flume 日志采集 -> kafka streaming 数据清洗和预处理 -> spark streaming 流式计算。在我们完成实时推 荐服务的代码后,应该与其它工具进行联调测试,确保系统正常运行。
启动实时系统的基本组件
- 启动实时推荐系统 StreamingRecommender 以及 mongodb、redis
- 启动 zookeeper
- 设置flume
- 启动 kafka
- 构建 Kafka Streaming 程序
构建 Kafka Streaming 程序
在 recommender 下新建 module,KafkaStreaming,主要用来做日志数据的预处理, 过滤出需要的内容。pom.xml 文件需要引入依赖:
org.apache.kafka
kafka-streams
0.10.2.1
org.apache.kafka
kafka-clients
0.10.2.1
kafkastream
org.apache.maven.plugins
maven-assembly-plugin
com.atguigu.kafkastream.Application
jar-with-dependencies
make-assembly
package
single
org.apache.maven.plugins
maven-compiler-plugin
8
8
- 在 src/main/java 下新建 java 类 com.atguigu.kafkastreaming.Application
package com.kkb.kafkastream;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.processor.TopologyBuilder;
import java.util.Properties;
public class Application {
public static void main(String[] args) {
String brokers = "cdh1:9092";
String zookeepers = "cdh1:2181";
// 输入和输出的topic
String from = "log";
String to = "recommender";
// 定义kafka streaming的配置
Properties settings = new Properties();
settings.put(StreamsConfig.APPLICATION_ID_CONFIG, "logFilter");
settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
settings.put(StreamsConfig.ZOOKEEPER_CONNECT_CONFIG, zookeepers);
// 创建 kafka stream 配置对象
StreamsConfig config = new StreamsConfig(settings);
// 创建一个拓扑建构器
TopologyBuilder builder = new TopologyBuilder();
// 定义流处理的拓扑结构
builder.addSource("SOURCE", from)
.addProcessor("PROCESSOR", ()->new LogProcessor(), "SOURCE")
.addSink("SINK", to, "PROCESSOR");
KafkaStreams streams = new KafkaStreams( builder, config );
streams.start();
System.out.println("Kafka stream started!>>>>>>>>>>>");
}
}
配置flume
- 在 flume 的 conf 目录下新建 log-kafka.properties,对 flume 连接 kafka 做配置:
- 如果将项目打包提交到集群上运行, 需要agent.sources.exectail.command 设置为日志文件所在路径
agent.sources = exectail
agent.channels = memoryChannel
agent.sinks = kafkasink
# For each one of the sources, the type is defined agent.sources.exectail.type = exec
# 下面这个路径是需要收集日志的绝对路径,改为自己的日志目录
agent.sources.exectail.command = tail –f /Users/xingyeah/Desktop/workspace/MovieRecommendSystem22/businessServer/src/main/log/agent.log
agent.sources.exectail.interceptors=i1
agent.sources.exectail.interceptors.i1.type=regex_filter
# 定义日志过滤前缀的正则
agent.sources.exectail.interceptors.i1.regex=.+MOVIE_RATING_PREFIX.+
# The channel can be defined as follows.
agent.sources.exectail.channels = memoryChannel
# Each sink's type must be defined
agent.sinks.kafkasink.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.kafkasink.kafka.topic = log
agent.sinks.kafkasink.kafka.bootstrap.servers = cdh1:9092
agent.sinks.kafkasink.kafka.producer.acks = 1
agent.sinks.kafkasink.kafka.flumeBatchSize = 20
#Specify the channel the sink should use
agent.sinks.kafkasink.channel = memoryChannel
# Each channel's type is defined.
agent.channels.memoryChannel.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
agent.channels.memoryChannel.capacity = 10000
启动后台业务系统
- maven -> plugins --> tomcat7 --> tomcat7:run
常用命令
# 启动mongo
cd /opt/cdh/mongodb-linux-x86_64-3.2.1/bin/mongo
./mongo # 启动mongo服务
# 启动elasticsearch
# 进入elastic用户
su elastic
# 启动elastic服务
/home/elastic/elasticsearch-6.4.3/bin/elasticsearch
# 1. 启动web_server, 点击tomcat
点击 tomcat-run.sh
# 2. 启动flume
bin/flume-ng agent -c ./conf/ -f ./conf/log-kafka.properties -n agent -Dflume.root.logger=INFO,console
# 启动kafka producer 生产数据
bin/kafka-console-producer.sh --broker-list cdh1:9092 --topic recommender
# 输入数据
1|1271|4.5|1554276432
273892982|168|5.0|835355710
273892982|186|4.0|835355664
# kafka消费数据
bin/kafka-console-consumer.sh --zookeeper cdh1:2181 --from-beginning --topic recommender
# 8.查看topic列表
bin/kafka-topics.sh --list --zookeeper cdh1:2181
# kafka删除topic
bin/kafka-topics.sh --delete --zookeeper cdh1:2181 --topic recommender
# kafka创建topic
bin/kafka-topics.sh --create --zookeeper cdh1:2181 --replication-factor 3 --partitions 5 --topic recommender