flink 知识点总结
1.什么是flink?
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。
Flink 能够提供毫秒级别的延迟,同时保证了数据处理的低延迟、高吞吐和结果的正确性,还提供 了丰富的时间类型和窗口计算、Exactly-once (就一次)语义支持,另外还可以进行状态管理,并提供 了 CEP(复杂事件处理)的支持。
2.Flink 的重要特点?
- 事件驱动
- List item
- 基于流的世界观
- 在Flink的世界观中,一切都是由流组成的,离线数据是有界限的流;
- 实时数据是一个没有界限的流:这就是所谓的有界流和无界流
- 分层API
- 越顶层越抽象,表达含义越简明,使用越方便
- 越底层越具体,表达能力越丰富,使用越灵活
3.什么是有界流和无界流?
在 spark 的世界观中,一切都是由批次组成的,离线数据是一个大批次,而实 时数据是由一个一个无限的小批次组成的。 而在 flink 的世界观中,一切都是由流组成的,离线数据是有界限的流,实时数 据是一个没有界限的流,这就是所谓的有界流和无界流。
- 无界数据流:无界数据流有一个开始但是没有结束,它们不会在生成时终止并 提供数据,必须连续处理无界流,也就是说必须在获取后立即处理 event(事件)。对于无界 数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取 event,以 便能够推断结果完整性。
- 有界数据流:有界数据流有明确定义的开始和结束,可以在执行任何计算之前 通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有 界数据集进行排序,有界流的处理也称为批处理
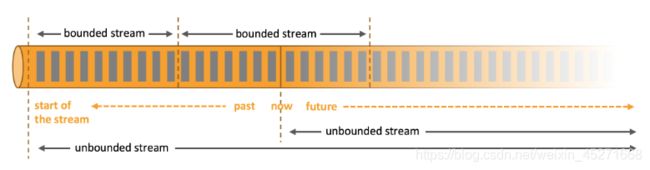
这种以流为世界观的架构,获得的最大好处就是具有极低的延迟。
4.flink的其他特点?
- 支持事件时间(event- time)和处理时间(processing time)
- 精确一次的状态一致性保证低延迟,
- 每秒处理数百万个事件,
- 毫秒级延迟与众多常用存储系统的连接
- 高可用,动态扩展,实现7*24小时全天候运行
5.flink和sparkStreaming 对比?
- 数据模型
- spark采用RDD模型,spark streaming的DStream实际上也就是一-组 组小批数据RDD的集合
- flink基本数据模型是数据流,以及事/件序列
- 运行架构
- spark是批计算,将DAG划分为不同的stage,一个完成后才可以计算下一个
- flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理
6.spark DAG 如何划分stage?
stage的切割规则:从后向前,遇到宽依赖就切割stage
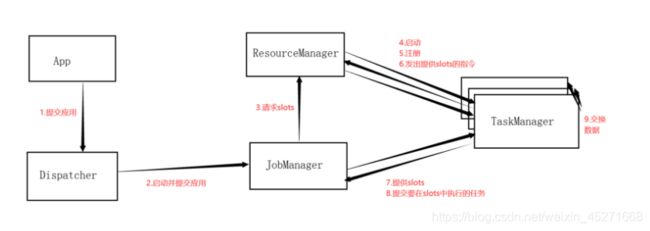
7.flink 运行的组件?
- jobManager:作业管理器
- taskManager:任务管理器
- resourceManager:资源管理器
- dispacher:分发器
8.jobmanager 的什么作用?
- 控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的
- jobManager所控制jobManager会先接收到要执行的应用程序,这个应用程序会包括:作业图,逻辑数据流图和打包了所有类、库和其它资源的jar包
- jobManager会把jobGraph转换成一个物理层面的数据流图,这个图被叫做“执行图”,包含了所有可以执行的任务
- jobManager会向资源管理器(resourceManager)请求执行任务必要的资源,也就是任务管理器(taskManager)上的插槽(slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的taskManager上。而在运行过程中,jobManager会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调
9.jobmanager接收到的应用程序包含?
作业图,逻辑数据流图和打包了所有类、库和其它资源的jar包
10.taskManager 的什么作用?
- flink中的工作进程。通常在flink中会有多个taskManager运行,每一taskManager都包含了一定数量的插槽(solts)。插槽的数量限制了taskManager能够执行的任务数量
- 启动之后,taskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,taskManager就会将一个或多个插槽提供给jobManager调用。jobManager就可以向插槽分配任务(tasks)来执行了
- 在执行过程中,一个taskManager可以跟其他运行同一应用程序的taskManager交换数据
11.resourceManager的作用?
- 主要负责管理任务管理器(taskManager)的插槽(solt),taskManager插槽是flink中定义的处理资源单元。
- flink为不同的环境和资源管理工具提供不同的资源管理工具,比如YARN、Mesos、K8s,以及standalone部署
- 当jonManager申请插槽资源时,ResourceManager会将有空间插槽来满足jobManager的请求,它还可以向资源提供平台发起会话,以提供启动taskManager进程的容器
12.flink的资源管理器有哪些?
YARN、Mesos、K8s,以及standalone
13.Dispatcher的作用?
- 可以跨作业运行,它为应用提交提供了REST接口。
- 当一个应用被提交执行时,分发器就会启动并将应用移交给一个jobManager
- dispatcher也会启动一个web UI,用来方便地展示和监控作业执行的信息
- dispatcher在架构中可能并不是必须的,这个取决于应用提交运行的方式
14.画出任务提交流程?
15.taskManager 通过什么控制task数量?
- flink中每一个taskManager都是一个JVM进程,它可能会在独立的线程上执行一个或者多个subtask
- 为了控制一个taskManager能接受多少个task,taskManager通过task
slot来进行控制(一个taskManager至少有一个slot)
16.flink 是否允许任务共享slot?
- 默认情况下,flink允许子任务共享slot,即使它们是不同的子任务。这样的结果是,一个slot可以保存作业的整个管道
- task slot是静态的概念,是指taskManager具有的并发执行能力
17.flink程序包含那几部分?
- 所有的flink程序都是由三部分的:source、Transformation和Sink
- source负责读取数据源,Transformation利用各种算子进行处理加工,Sink负责输出
18.flink 的执行图包含那四部分?
StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图
19.什么是streamgraph?
是根据用户通过Stream API编写的代码生成的最初的图。用来表示程序的拓扑结构
20.什么是jobgraph?
StreamGraph经过优化后生成JobGraph,提交给JobManager的数据结构。主要优化为,将多个符合条件的节点chain(链)在一起作为一个节点
21.什么是executiongraph?
JobManager根据JobGraph生成ExecutionGrouph。ExectionGrouph是JobGrouph的并行化版本,是调度层最核心的数据结构
22.什么是物理执行图?
JobManager根据ExectionGrouph对Job进行调度后,在各个taskManager上部署task后形成的“图”,并不是一个具体的数据结构
23.什么是并行度?
- 一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。一般情况下,一个stream的并行度,可以认为就是其所有算子中最大的并行度
- 一个程序中,不同的算子可能具有不同的并行度
- 算子之间传输数据的形式可以是one-to-one(forwarding)的模式也可以是redistributing的模式,具体是哪一种形式,取决于算子的种类
- one-to-one:stream维护者分区以及元素的顺序(比如source和map之间)。这就意味着map算子的子任务看到的元素的个数以及顺序跟source算子的子任务生产的元素的个数、顺序相同。map、fliter、flatmap、等算子都是one-to-one的对应关系
- redistributing:stream的分区会发生改变。每一个算子的子任务依据所选择的transformation发送数据到不同的目标任务。例如:keyBy基于hashCode重分区、而broadcast和rebalance会随即重新分区,这些算子都会引起redistribute过程,而redistribute过程就类似于spark中的shuffle过程
24.什么是stream最大并行度?
一般情况下,一个stream的并行度,可以认为就是其所有算子中最大的并行度
25.算子的数据传输 2种形式?
- one-to-one:stream维护者分区以及元素的顺序(比如source和map之间)。这就意味着map算子的子任务看到的元素的个数以及顺序跟source算子的子任务生产的元素的个数、顺序相同。map、fliter、flatmap、等算子都是one-to-one的对应关系
- redistributing:stream的分区会发生改变。每一个算子的子任务依据所选择的transformation发送数据到不同的目标任务。例如:keyBy基于hashCode重分区、而broadcast和rebalance会随即重新分区,这些算子都会引起redistribute过程,而redistribute过程就类似于spark中的shuffle过程
26.flink 的任务链?
- flink采用了一种称为任务链的优化技术,可以在特定的条件下减少本地雍熙的开销。为了满足任务链的要求,必须将两个或者多个算子设为相同的并行度,并通过本地转发(local forward)的方式进行连接
- 相同并行度的 one-to-one操作,flink这样相连的算子链接在一起形成一个task,原来的算子成为里面的subtask
- 并行度相同、并且是one-to-one操作,两个条件缺一不可
27.满足任务链的要求?
并行度相同、并且是one-to-one操作,两个条件缺一不可
28.flink 流split ,select?
- Split
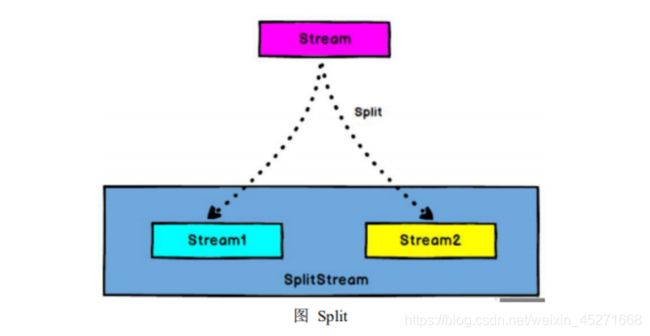
DataStream → SplitStream:根据某些特征把一个 DataStream 拆分成两个或者 多个 DataStream。
- Select
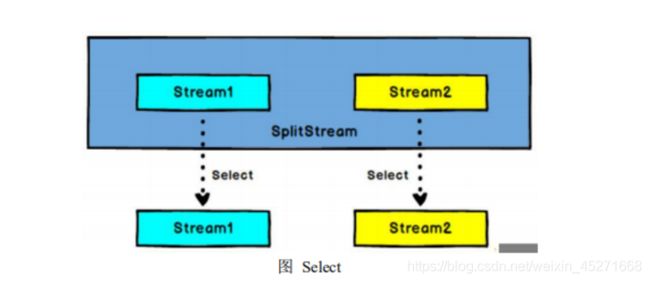
SplitStream→DataStream:从一个 SplitStream 中获取一个或者多个 DataStream。 需求:传感器数据按照温度高低(以 30 度为界),拆分成两个流
29.流的connect 和 union 的区别?
- Connect 与 Union 区别:
- Union 之前两个流的类型必须是一样,Connect 可以不一样,在之后的coMap 中再去调整成为一样的。
- Connect 只能操作两个流,Union 可以操作多个。
- connect
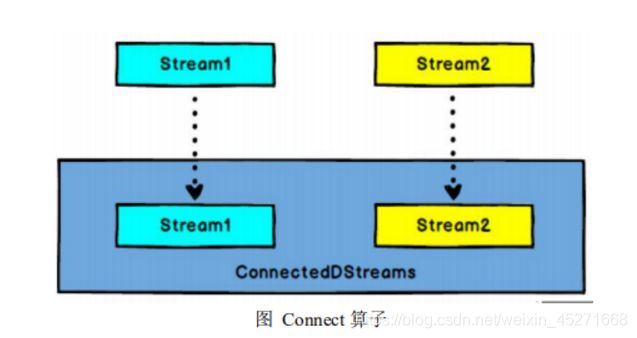
DataStream,DataStream → ConnectedStreams:连接两个保持他们类型的数据 流,两个数据流被 Connect 之后,只是被放在了一个同一个流中,内部依然保持各 自的数据和形式不发生任何变化,两个流相互独立。
- union
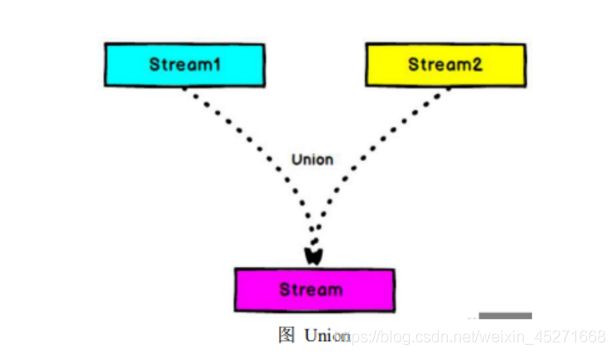
DataStream → DataStream:对两个或者两个以上的 DataStream 进行 union 操 作,产生一个包含所有 DataStream 元素的新 DataStream。
30.flink的数据类型?
- 基础数据类型
- Flink支持所有的Java和Scala基础数据类型,Int, Double, Long, String, …
- Java和Scala元组(Tuples)
- Scala样例类(case classes)
- Java简单对象(POJOs)
- 其它(Arrays, Lists, Maps, Enums, 等等)
- Flink对Java和Scala中的一些特殊目的的类型也都是支持的,比如Java的ArrayList,HashMap,Enum等等。
31.什么是富函数? 富函数有什么作用?
“富函数”是 DataStream API 提供的一个函数类的接口,所有 Flink 函数类都 有其 Rich 版本。它与常规函数的不同在于,可以获取运行环境的上下文,并拥有一 些生命周期方法,所以可以实现更复杂的功能。
- RichMapFunction
- RichFlatMapFunction
- RichFilterFunction
- …
- Rich Function 有一个生命周期的概念。典型的生命周期方法有:
- open()方法是 rich function 的初始化方法,当一个算子例如 map 或者 filter 被调用之前 open()会被调用。
- close()方法是生命周期中的最后一个调用的方法,做一些清理工作。
- getRuntimeContext()方法提供了函数的 RuntimeContext 的一些信息,例如函 数执行的并行度,任务的名字,以及
state 状态
32.flink window的类型?
- 时间窗口(Time Window)
- 滑动时间窗口
- 滚动时间窗口
- 会话窗口
- 计数窗口(Count Window)
- 滑动计数窗口
- 滚动计数窗口
33.window function 有哪些?
- 增量聚合函数(incremental aggregation functions)
- 每条数据到来就进行计算,保持一个简单的状态ReduceFunction, AggregateFunction
- 全窗口函数(full window functions)
- 先把窗口所有数据收集起来,等到计算的时候会遍历所有数据ProcessWindowFunction
34.flink 的时间语义?
- Event Time:事件创建的时间
- Ingestion Time:数据进入Flink的时间
- Processing Time:执行操作算子的本地系统时间,与机器相关
35.乱序数据有什么影响?
- 当Flink 以Event Time模式处理数据流时,它会根据数据里的时间戳来处理基于时间的算子
- 由于网络、分布式等原因,会导致乱序数据的产生
- 乱序数据会让窗口计算不准确
36.什么是watermark?
- Watermark是一种衡量Event Time进展的机制,可以设定延迟触发
- Watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark机制结合window来实现;
- 数据流中的Watermark用于表示timestamp小于Watermark的数据,都已经到达了,因此,window的执行也是由Watermark触发的。
- watermark用来让程序自己平衡延迟和结果正确性
37.watermark的特点?
- watermark是一条特殊的数据记录
- watermark必须单调递增,以确保任务的事件时间时钟在向前推进,而不是在后退
- watermark与数据的时间戳相关
38.flink 状态管理包含哪些?
状态一致性,故障处理以及高效存储和访问,以便开发人员可以专注于应用程序的逻辑。
39.flink 状态的类型?
- 算子状态(Operator State)
- 算子状态的作用范围限定为算子
- 任务键控状态(Keyed State)
- 根据输入数据流中定义的键(key) 来维护和访问
40.算子状态的特点?
- 算子状态的作用范围限定为算子任务,由同一并行任务所处理的所有数据都可以访问到相同的状态
- 状态对于同一任务而言是共享的
- 算子状态不能由相同或不同算子的另一个任务访问
41.算子状态的数据结构?
- 列表状态(List state)
- 将状态表示为一组数据的列表
- 联合列表状态(Union list state)
- 也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint) 启动应用程序时如何恢复
- 广播状态(Broadcast state)
- 如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
42.键控状态特点?
- 键控状态是根据输入数据流中定义的键(key) 来维护和访问的
- Flink为每个key维护一一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态
- 当任务处理一条数据时, 它会自动将状态的访问范围限定为当前数据的key
43.键控状态的数据结构?
- 值状态(Value state)
- 将状态表示为单个的值
- 列表状态(List state)
- 将状态表示为一组数据的列表
- 映射状态(Map state)
- 将状态表示为一组Key-Value对
- 聚合状态(Reducing state & Aggregating State)
- 将状态表示为一个用于聚合操作的列表
44.什么是状态后端?
- 每传入一条数据,有状态的算子任务都会读取和更新状态
- 由于有效的状态访问对于处理数据的低延迟至关重要,因此每个并行任务都会在本地维护其状态,以确保快速的状态访问
- 状态的存储、访问以及维护,由一个可插入的组件决定,这个组件就叫做状态后端(state backend)
45.状态后端的职责?
状态后端主要负责两件事:本地的状态管理,以及将检查点(checkpoint)状态写入远程存储
46.状态后端的类型?
- MemoryStateBackend
- 内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在TaskManager的JVM堆上,而将checkpoint存储在JobManager的内存中
- 特点:快速、低延迟,但不稳定
- FsStateBackend
- 将checkpoint存到远程的持久化文件系统(FileSystem) 上,而对于本地状态,跟MemoryStateBackend一样,也会存在TaskManager的JVM堆上
- 同时拥有内存级的本地访问速度,和更好的容错保证
- RocksDBStateBackend
- 将所有状态序列化后,存入本地的RocksDB中存储。
47.什么是processfunction 函数?
- ProcessFunction是一个低阶的流处理操作,它可以访问流处理程序的基础构建模块:
- 事件(event)(流元素)
- 状态(state)(容错性,一致性, 仅在keyed stream中)
- 定时器(timers)(event time和processing time,仅在keyed stream中)
- ProcessFunction可以看作是一个具有keyed state和timers访问权的FlatMapFunction
- 通过RuntimeContext访问keyed state
- 计时器允许应用程序对处理时间和事件时间中的更改作出响应。对processElemet(…)函数的每次调用都获得一个Context对象,该对象可以访问元素的event time timestamp和TimerService
- TimerService可用于为将来的event/process time瞬 间注册回调。当到达计时器的特定时间时,将调用onT1imer…)方法。在该调用期间,所有状态都再次限定在创建计时器时使用的键的范围内,从而允许计时器操作键控状态
48.processfunction 函数有哪些?
Flink 提供了 8 个 Process Function:
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- ProcessJoinFunction
- BroadcastProcessFunction
- KeyedBroadcastProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
49.什么是侧输出流?
Flink 处理数据流时,我们经常会遇到这种情况:在处理一个数据源时,往往需要将该数据源中的不同类型的数据做分割处理,如果使用filter算子对数据源进行筛选分割的话,势必会造成数据流的多次复制,造成不必要的性能浪费;Flink中的侧输出就是将数据流进行分割,而不对流进行复制的一种分流机制,flink的侧输出的另一个作用就是对延时迟到的数据进行处理,这样就可以不必丢弃迟到的数据。案例:假设我们的需求是实时的从kafka接收生产数据,我们需要对迟到超过一定时长的数据进行另行处理。
50.flink 故障恢复机制的核心?
flink故障恢复机制的核心,就是应用状态的一致性检查点。
51.什么是有状态的一致性检查点?
有状态流应用的一致检查点,其实就是所有任务的状态,在某个时间点的一份拷贝(一 份快照) ;这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候
52.如何从检查点恢复状态?
- 在执行流应用程序期间,Flink 会定期保存状态的一致检查点
- 如果发生故障,Flink 将会使用最近的检查点来一致恢复应用程序的状态,并重新启动处理流程
- 遇到故障之后,第一步就是重启应用
- 第二步是从checkpoint中读取状态,将状态重置
- 从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同
- 第三步:开始消费并处理检查点到发生故障之间的所有数据
- 这种检查点的保存和恢复机制可以为应用程序状态提供"精确一次"(exactly-once)的一致性,因为所有算子都会保存检查点并恢复其所有状态,这样一来所有的输入流就都会被重置到检查点完成时的位置
53.什么是保存点?
- Flink还提供了可以自定义的镜像保存功能,就是保存点(savepoints)
- 原则上,创建保存点使用的算法与检查点完全相同,因此保存点可以认为就是具有一些额外元数据的检查点
- Flink不会自动创建保存点,因此用户(或者外部调度程序)必须明确地触发创建操作
- 保存点是一个强大的功能。除了故障恢复外, 保存点可以用于:有计划的手动备份,更新应用程序,版本迁移,暂停和重启应用,等等
54.检查点(checkpoint)和保存点(savepoint)的区别?
- checkpoint的侧重点是“容错”,即Flink作业意外失败并重启之后,能够直接从早先打下的checkpoint恢复运行,且不影响作业逻辑的准确性。而savepoint的侧重点是“维护”,即Flink作业需要在人工干预下手动重启、升级、迁移或A/B测试时,先将状态整体写入可靠存储,维护完毕之后再从savepoint恢复现场。
- savepoint是“通过checkpoint机制”创建的,所以savepoint本质上是特殊的checkpoint。
- checkpoint面向Flink Runtime本身,由Flink的各个TaskManager定时触发快照并自动清理,一般不需要用户干预;savepoint面向用户,完全根据用户的需要触发与清理。
- checkpoint的频率往往比较高(因为需要尽可能保证作业恢复的准确度),所以checkpoint的存储格式非常轻量级,但作为trade-off牺牲了一切可移植(portable)的东西,比如不保证改变并行度和升级的兼容性。savepoint则以二进制形式存储所有状态数据和元数据,执行起来比较慢而且“贵”,但是能够保证portability,如并行度改变或代码升级之后,仍然能正常恢复。
- checkpoint是支持增量的(通过RocksDB),特别是对于超大状态的作业而言可以降低写入成本。savepoint并不会连续自动触发,所以savepoint没有必要支持增量。
55.什么是状态一致性?
- 有状态的流处理,内部每个算子任务都可以有自己的状态
- 对于流处理器内部来说,所谓的状态一致性, 其实就是我们所说的计算结果要保证准确。
- 一条数据不应该丢失,也不应该重复计算
- 在遇到故障时可以恢复状态,恢复以后的重新计算,结果应该也是完全正确的。
56.状态一致性的分类?
- AT-MOST-ONCE (最多一次)
- 当任务故障时,最简单的做法是什么都不干,既不恢复丢失的状态,也不重 播丢失的数据。At-most-once 语义的含义是最多处理一次事件。
- AT-LEAST-ONCE (至少一次)
- 在大多数的真实应用场景,我们希望不丢失事件。这种类型的保障称为at- least-once,意思是所有的事件都得到了处理,而一些事件还可能被处理多次。
- EXACTLY-ONCE (精确一次)
- 恰好处理一次是最严格的保证,也是最难实现的。恰好处理一次语义不仅仅意味着没有事件丢失,还意味着针对每一个数据, 内部状态仅仅更新一次。
57.端到端的精确性?
- 目前我们看到的一致性保证都是由流处理器实现的,也就是说都是在Flink流处理器内部保证的;而在真实应用中,流处理应用除了流处理器以外还包含了数据源(例如Kafka)和输出到持久化系统
- 端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终;每一个组件都保证了它自己的一致性
- 整个端到端的一致性级别取决于所有组件中-一致性最弱的组件
58.什么是幂等写入?
所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了
59.什么是2PC?
就是两阶段提交(Two-Phase-Commit)
- 对于每个checkpoint, sink 任务会启动一个事务,并将接下来所有接收的数据添加到事务里
- 然后将这些数据写入外部sink系统,但不提交它们–这时只是"预提交"
- 当它收到checkpoint完成的通知时,它才正式提交事务,实现结果的真正写入
- 这种方式真正实现了exactly-once,它需要一个提供事 务支持的外部sink系统。Flink 提供了TwoPhaseCommitSinkFunction接口。
60.flink和kafka端到端状态一致性的保证?
- 内部 – 利用checkpoint机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性
- source – kafka
consumer作为source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性 - sink-- kafka producer作为sink,采用两阶段提交sink,需要实现一个TwoPhaseCommitSinkFunction
61.kafka精确一致性(Exactly-once ) 两阶段提交的步骤?
- 第一条数据来了之后,开启一个kafka的事务(transaction) ,正常写入kafka分区日志但标记为未提交,这就是"预提交"
- jobmanager触发checkpoint操作,barrier 从source开始向下传递,遇到barrier的算子将状态存入状态后端,并通知jobmanager
- sink连接器收到barrier,保存当前状态,存入checkpoint,通知jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
- jobmanager收到所有任务的通知,发出确认信息,表示checkpoint完成
- sink任务收到jobmanager的确认信息,正式提交这段时间的数据
- 外部kafka关闭事务,提交的数据可以正常消费了。
62.Flink 的数据抽象及数据交换过程?
Flink 为了避免 JVM 的固有缺陷例如 java 对象存储密度低,FGC 影响吞吐和响应等,实现了自主管理内存。MemorySegment 就是 Flink 的内存抽象。默认情况下,一个 MemorySegment 可以被看做是一个 32kb 大的内存块的抽象。这块内存既可以是 JVM 里的一个 byte[],也可以是堆外内存(DirectByteBuffer)。在 MemorySegment 这个抽象之上,Flink 在数据从 operator 内的数据对象在向 TaskManager 上转移,预备被发给下个节点的过程中,使用的抽象或者说内存对象是 Buffer。对接从 Java 对象转为 Buffer 的中间对象是另一个抽象 StreamRecord。
63.flink Checkpoint的理解
- 轻量级容错机制(全局异步,局部同步)
- 保证exactly-once 语义
- 用于内部失败的恢复
- 基本原理:通过往source 注入barrier,barrier作为checkpoint的标志
64.什么是CEP?
- 复杂事件处理(Complex Event Processing,CEP)
- flink CEP 是在flink中实现的复杂事件处理(CEP)库
- CEP允许在无休止的事件流中检测事件模式,让我们有机会掌握数据中重要的部分
- 一个或多个由简单事件构成的事件流通过一定的规则匹配,然后输出用户想得到的数据—满足规则的复杂时间
65.flink CEP 的模式有那些?
- 个体模式(Individual Patterns)
- 组成复杂规则的每一个单独的模式定义,就是"个体模式
"start.time(3).where(_.behavior.startsWith(“fav”)
- 组成复杂规则的每一个单独的模式定义,就是"个体模式
- 组合模式(Combining Patterns,也叫模式序列)
- 很多个体模式组和起来,就形成了整个的模式序列
- 模式序列必须以一个"初始模式"开始:val start = Pattern.begin(“start”)
- 模式组(Groups of patterns)
- 将一个模式序列作为条件嵌套在个体模式里,成为一组模式
66.flink CEP 个体模式分为?
- 单例(singleton)模式
- 只接收一个事件
- 循环(looping)模式
- 可以接收多个事件
67.flink CEP 个体模式的条件?
- 每个模式都需要指定触发条件,作为模式是否接受事件进入的判断依据
- CEP中的个体模式主要通过调用.where()和.until()来指定条件
- 按不同的调用方式,可以分为以下几类
-
简单条件(Simple Condition)
- 通过.where()方法对事件中的字段进行判断筛选,决定是否接收该事件
start.where(event =>event.getName.startsWith(“foo”))
- 通过.where()方法对事件中的字段进行判断筛选,决定是否接收该事件
-
组合条件(Combining Condition)
- 将简单条件进行合并;.or()方法表示或逻辑相连,where的直接组合就是
ANDpattern.where(event => …/*some condition */).or(event => … /*or condition */)
- 将简单条件进行合并;.or()方法表示或逻辑相连,where的直接组合就是
-
终止条件(Stop Condition)
- 如果使用了oneOrMore或者oneOrMore.optional,建议使用.until()作为终止条件,以便清理状态
-
迭代条件(Iterative Condition)
- 能够对模式之前都有的事件进行处理调用
.where((value,ctx) =>{…}),可以调用ctx.getEventForPattern(“name”)
- 能够对模式之前都有的事件进行处理调用
-
68.flink CEP 模式序列的几种模式?
-
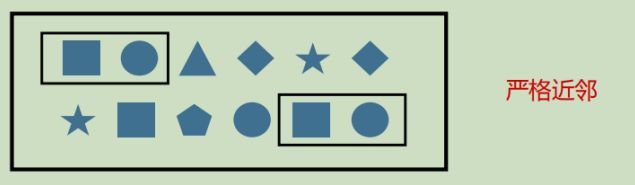
严格近邻(Strict Contiguity)
- 所有时间按照严格的顺序出现,中间没有任何不匹配的事件,由.next()指定
- 例如对于模式"a next b",事件序列[a,c,b1,b2]没有匹配
-
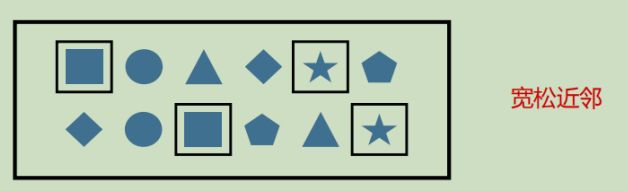
宽松近邻(Relaxed Contiguity)
- 允许中间出现不匹配的事件,由.followedBy()指定
- 例如对于模式"a followsBy b",事件序列[a,c,b1,b2]匹配为[a,b1]
-
非确定性宽松近邻(Non-Deterministic Relaxed Contiguity)
- 进一步放宽条件,之前已经匹配的事件也可以再次使用,由.followedByAny()指定
- 例如对于模式"a followedByAny b",事件序列[a,c,b1,b2]匹配为{a,b1}{a,b2}
-
除以上模式序列外,还可以定义"不希望出现某种近邻关系"
- .notNext() ----- 不想让某事件严格近邻前一个事件发生
- .notFollowedBy() ---- 不想让某事件在两件事件之间发生
-
需要注意:
- 所有模式序列必须以.begin()开始
- 模式序列不能以.ntFollowedBy()结束
- "not"类型的模式不能被optional所修饰
- 此外,还可以为模式指定事件约束,用来要求在多长时间内匹配有效next.within(Time.senconds(10))