GA-Net : Guided Aggregation Net for End-to-End Stereo Matching
GA-Net : Guided Aggregation Net for End-to-End Stereo Matching
- 摘要
- 贡献
- 相关工作
- Local Cost Aggregation
- Semi-Global Matching
- GA-Net
- Guided Aggregation Layers引导聚合层
- Semi-Global Aggregation(SGA)半全局聚合
- Local Guided Aggregation(LGA)局部引导聚合
- Efficient Implementation
- 网络架构
- 损失函数
- 实验
- 消融实验
- 总结
- GA-Net代码训练
论文《GA-Net: Guided Aggregation Net for End-to-end Stereo Matching》是CVPR2019的收录文章。今天就来大概的写一写里面的知识点。若有错误的地方,大家多多指出哈。
论文链接:https://arxiv.org/pdf/1904.06587v1.pdf
代码链接:https://github.com/feihuzhang/GANet
摘要
在立体匹配任务中,为了准确地估计视差,传统方法和深度神经网络模型都需要对匹配代价进行聚合。GA-Net提出了两种新的神经网络层,分别用于捕获局部和全图像的代价依赖关系。第一个是半全局聚合层,它是半全局匹配的可微近似;第二个是局部引导聚合层,它遵循传统的代价过滤策略来细化结构。这两个层可以代替目前广泛使用的三维卷积层,因为三维卷积层具有立方计算/内存复杂度,计算量大,内存消耗大。实验结果表明,具有两层引导聚合块的网络性能优于具有19个三维卷积层的最先进的GC-Net。我们还训练了一个深度引导的聚合网络(GA-Net),它比最先进的方法在场景流数据集和KITTI基准测试上获得更好的准确性。
贡献
为了GA-Net提出了两个新的代价聚合层应用在端到端的立体匹配中,以取代三维卷积。注意,GA-Net文中最多的对比研究是GC-Net。GC-Net(https://arxiv.org/pdf/1703.04309.pdf)是ICCV 2017的收录论文,其中包含了19个三维卷积层。
- semi-global guided aggregation layer(SGA) 半全局引导聚合层
SGA大家看起来是不是觉得很眼熟?是的,在双目视觉的研究历史上,有一个很经典的研究是SGM(https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=4359315),称为半全局匹配算法,收录在PAMI 2008中。SGA可以近似为SGM算法,在整张图像的不同方向上聚合匹配代价。这使得算法可以在遮挡区域、大的无纹理/反射区进行精确的估计。 - local guided aggregation layer(LGA) 局部引导聚合层
LGA引入的目的是针对薄结构和对象边缘的处理,以恢复上下采样层造成的细节损失。
- GA复杂度
一个GA层的计算复杂度仅为三维卷积的1/100(浮点运算FLOPs)。这使得GA-Net建立的模型可以是实时的,与现有的实时算法相比,GA-Net的精度更高,运算速度为15-20帧/每秒。*****
相关工作
基于特征的匹配代价往往是模糊的,由于遮挡、平滑、反射、噪声等原因,错误的匹配代价很容易比正确的匹配代价低。为了解决这个问题,现已经开发了许多代价聚合方法来细化代价值并实现更好的估计。
Local Cost Aggregation
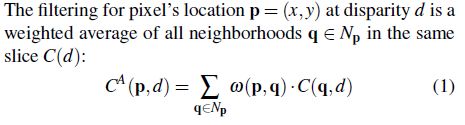
其中引导滤波权重w可以根据不同的图像滤波来获得。
Semi-Global Matching
立体匹配可以看作是通过最小化能量函数E(D)来寻找最优的视差图D

式(3)是当视差为d时,位置p在整张图像中从方向r上的聚合代价
式(3)这个公式其实不难理解,早在最初的双目神经网络MC-CNN中就应用过,为了在r方向上最小化E(D),MC-CNN定义在当前方向上的匹配代价Cr(p,d)为:
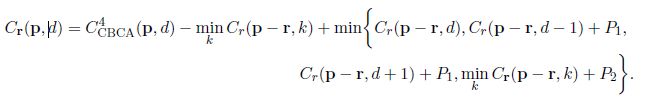
其中,减去第二项,是为了防止Cr(p,d)值增长过大,并且不会影响最佳视差图。
r指某个指向当前像素p的方向,在此可以理解为像素p左边的相邻像素。
Cr(p, d) 表示沿着当前方向(即从左向右),当目前像素p的disparity取值为d时,其最小cost值。
这个最小值是从4种可能的候选值中选取的最小值:
1.前一个像素(左相邻像素)disparity取值为d时,其最小的cost值。
2.前一个像素(左相邻像素)disparity取值为d-1时,其最小的cost值+惩罚系数P1。
3.前一个像素(左相邻像素)disparity取值为d+1时,其最小的cost值+惩罚系数P1。
4.前一个像素(左相邻像素)disparity取值为其他时,其最小的cost值+惩罚系数P2。
GA-Net
Guided Aggregation Layers引导聚合层
PSMNet和GC-Net中都建立了一个四维的匹配代价值(尺寸大小为HWDmax*F),其中F是特征图的大小
和上述研究不一样的是,GA-Net受到半全局和局部匹配代价聚合方法的灵感,提出了SGA和LGA层。
Semi-Global Aggregation(SGA)半全局聚合
- 传统SGM算法应用在神经网络中存在的困难
传统的SGM算法从不同的方向迭代的聚合匹配代价。但是在端到端可训练的深度神经网络中应用这种方法存在一些困难:
- SGM有许多用户自定义的参数(P1,P2),很难调优。这些参数在神经网络训练过程中都成为不稳定因素;
- SGM对所有像素、区域和图像的代价聚合和惩罚是固定的,不适应不同的条件;
- 在深度估计中,难例最小值选择会导致大量的前向平行曲面。
- 解决方案:SGA
为解决传统SGM存在的困难,GA-Net设计了一个新的可支持反向传播的半全局代价聚合步骤:
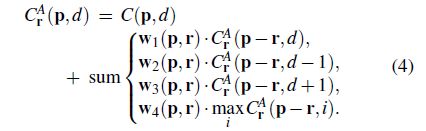
- SGA和SGM不同的地方:
- SGA使得用户自定义的参数是可学习的,并将他们作为匹配代价项的惩罚系数/权重相加。因此,这些权重将在不同的位置适应不同的情况,并且更加灵活。
- SGA将式(3)中的第一个/外部最小值选择替换为加权和,在精度上没有任何损失。
- 内部/第二个最小值选择被更改为最大值。这是因为在模型中的学习目标是最大化ground-truth的概率,而不是最小化匹配代价。
-
改进:
对于公式(3)和公式(4)而言,代价聚合的值沿着路径增加,这可能导致非常大的值。因此GA-Net将所有的项的权重进行归一化,避免上述问题。因此新的半全局聚合为:

注意:此处的w参数只是控制不同代价项的贡献权重 -
SGA和SGM中 r 的不同取值:
SGM在16个方向上进行聚合,目的是为了提高有效性;而GA-Net中的聚合在整张图像商沿着每行或者每列采用的总共是4个方向(左右上下)
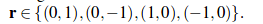
-
聚合输出:
GA-Net中最后的聚合输出是在4个方向上的代价聚合值中选取的最大值

最大值选择只保留来自一个方向的最优信息。这保证了聚合效果不会被其他方向模糊化。
Local Guided Aggregation(LGA)局部引导聚合
-
LGA的意义
LGA提出的目的是优化薄结构和目标边缘。下采样和上菜采样被广泛使用于立体匹配的模型中,但是它们会使得薄结构和目标边缘模糊。因此LGA层学习几个引导滤波去细化匹配代价,目的在于恢复薄结构的信息。 -
LGA

注意:此处的w参数是滤波
代价值的不同片(总共Dmax片)共享相同的滤波/聚合权重。 -
LGA和传统的代价滤波的不同之处
–传统的代价滤波方法在K×K局部/周围区域Np中采用K×K的滤波核去过滤代价值
–LGA层在每个像素位置p上拥有三个K×K的滤波(w0,w1,w2),分别是针对于视差d,d-1,d+1。也就是说,在每个像素位置p的K×K的局部区域中,LGA采用K×K×3的权重矩阵进行聚合。
Efficient Implementation
- 引导子网络
GA-Net采用几个2D卷积层去构建一个快速的引导子网络(如网络框架中所示)。 其输入是左右图,输出是聚合权重w。 - 引导子网络的参数量变化:
对于一个大小为H×W×D×F(D是最大视差,F是feature size)的4D代价值C而言:
—SGA:将引导子网络的输出分割、变形和归一化为四个H×W×K×F(K=5)权重矩阵,用于采用公式(5)进行四个方向的聚合。
注意:此处的K是公式5中的w0~w4这5个参数,所以K=5
—LGA:需要学习一个H×W×3K^2×F(K=5)的权重矩阵,然后使用公式(7)进行聚合。
注意:此处的K是滤波核大小
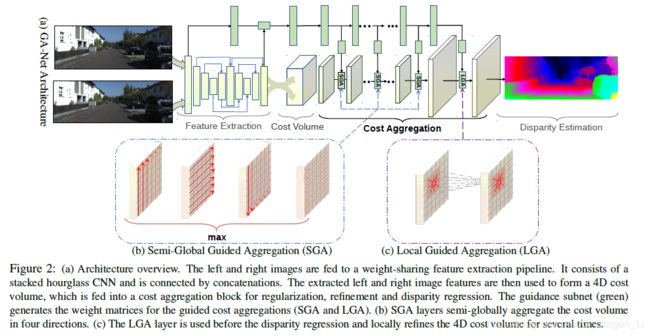
网络架构
GA-Net包含四个部分:
- 特征提取块:一个堆叠的沙漏网络。左右视角图共享该特征提取块。
- 对四维代价值的代价聚合:采用几个SGA层用于代价聚合。LGA层执行在视差回归的softmax层的前面和后面。
- 引导子网络:生成代价聚合权重
- 视差回归:softmax层
损失函数
采用smooth L1损失函数训练网络模型。相对于L2损失来说,smooth L1损失函数在不连续视差处具有鲁棒性,并且对奇异值和噪声具有低敏感性。

视差回归:

视差估计d是每个视差候选项的概率加权之和。每个视差d的概率是在代价聚合后通过softmax造作计算得到。
实验
- 数据集:Scene Flow & KITTI
- 框架:pytorch or caffe
- 预处理:对图像的每一个通道进行归一化处理(减去平均值并除以标准差)
消融实验
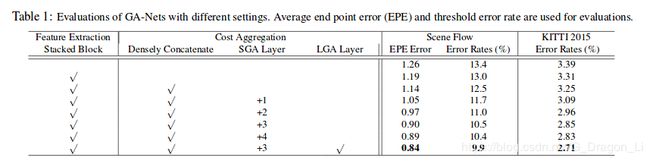
- GA引导聚合
如下表所示,和GC-Net与PSMNet进行对比发现,GA-Net的参数更少,运行速度更快,并且达到了很好的精确度。

下图是为了证明GA层的效果,和没有GA层的相同的结构进行对比,发现GA可以有效的提高模型的精确度

为了分析GA层的效果,下图中绘制了一系列候选视差的post-softmax概率。
4(a)中,由于在大的无纹理区域中没有任何特色的可正确匹配的特征,所以会存在很多噪声。SGA层通过聚合周围的匹配信息成功地在概率上抑制了这些噪声。
4(b)中,SGA和LGA层纠正错误的匹配,并将峰值集中在正确的视差值上。
4©中,SGA和LGA使用空间聚合和适当的最大选择来减少背景中错误匹配信息的聚合,从而抑制背景视差值处出现的错误概率峰值。

- SGA和SGMs、3D卷积的比较
- SGA与SGM的比较
SGA层是SGM 的可微近似,但是与原始的SGM和MC-CNN方法对比,它能产生更好的效果。原因在于: - SGA没有任何用户自定义的参数,全部都是在一个端到端的模型中学习的
- SGA的聚合是通过权重矩阵引导和控制的。引导子网络学习有效的几何信息和上下文信息去完全控制代价聚合的方向、范围和强度
- 与原始的SGM相比,在无纹理的大区域中,大多数前向平行近似都被避免了(如下图所示)。这可能受益于:
a、公式(5)中加权和的使用(公式(3)中是采用最大/最小选择)
b、公式(9)中的回归损失帮助实现超像素的精度 - SGA与3D卷积的比较
SGA层比3D卷积层更高效,原因在于:3D卷积层仅仅能聚合卷积核大小限制的局部区域。因此,一系列的三维卷积以及编码器和解码器架构是不可分割的,以获得良好的效果。相比之下,SGA层能在一个更有效的单层中进行半全局聚合。SGA的另一个优点是,聚合的方向、范围和强度完全由不同位置的不同几何和上下文信息的可变权重引导。例如,SGA在遮挡和大平滑区域的表现完全不同。但是,三维卷积层具有固定的权重,并且对整个图像中的所有位置都始终执行相同的操作。

- 模型复杂度
- 3D卷积的复杂度:
- 一个3D卷积层的计算复杂度是:

其中N是输出blob的元素数,K是卷积核的大小,C是输入blob的通道数。 - SGA的复杂度:
- 对于四方向或者八方向聚合,SGA的复杂度是O(4KN) 或者O(8KN)。
- 实时:
在GC-Net和PSMNet中,K=3,C=32,64 or 128,在GA-Net中,SGA层中的K=5。因此,所提出的SGA层的浮点运算(flops)计算复杂度小于一个三维卷积层的1/100。
->因此,建立一个精确实时的模型是可行的
GA-Net-1(一个3D卷积层,没有LGA层)是在caffe框架上实现的,该模型简单的将代价值进行4倍降采样和上采样。这个实时的模型在TESLA P40 GPU上运行速度为15~20帧每秒,图像大小为300×1000的。
如下图,实时的GA-Net远远超过了现有的实时立体匹配模型。

- KITTI
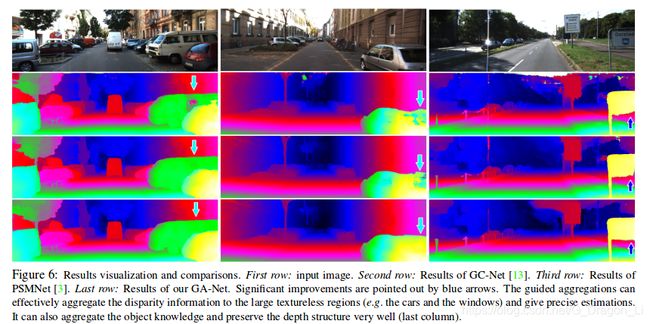

- 实时:
总结
提出啦引导匹配代价聚合(GA)策略,包括半全局聚合(SGA)和局部引导聚合(LGA)。GA层有效地在挑战区域提高了视差估计的精度,例如遮挡、大无纹理/反射区域和薄结构。GA层可以用来代替3D卷积,获得更高的精度。
GA-Net代码训练
<正在训练中,在过程中也遇见了一些bug,后续会接着更新>