损失函数softmax_cross_entropy、binary_cross_entropy、sigmoid_cross_entropy之间的区别与联系
cross_entropy-----交叉熵是深度学习中常用的一个概念,一般用来求目标与预测值之间的差距。
在介绍softmax_cross_entropy,binary_cross_entropy、sigmoid_cross_entropy之前,先来回顾一下信息量、熵、交叉熵等基本概念。
---------------------
信息论
交叉熵是信息论中的一个概念,要想了解交叉熵的本质,需要先从最基本的概念讲起。
一、信息量
首先是信息量。假设我们听到了两件事,分别如下:
事件A:巴西队进入了2018世界杯决赛圈。
事件B:中国队进入了2018世界杯决赛圈。
仅凭直觉来说,显而易见事件B的信息量比事件A的信息量要大。究其原因,是因为事件A发生的概率很大,事件B发生的概率很小。所以当越不可能的事件发生了,我们获取到的信息量就越大。越可能发生的事件发生了,我们获取到的信息量就越小。那么信息量应该和事件发生的概率有关。
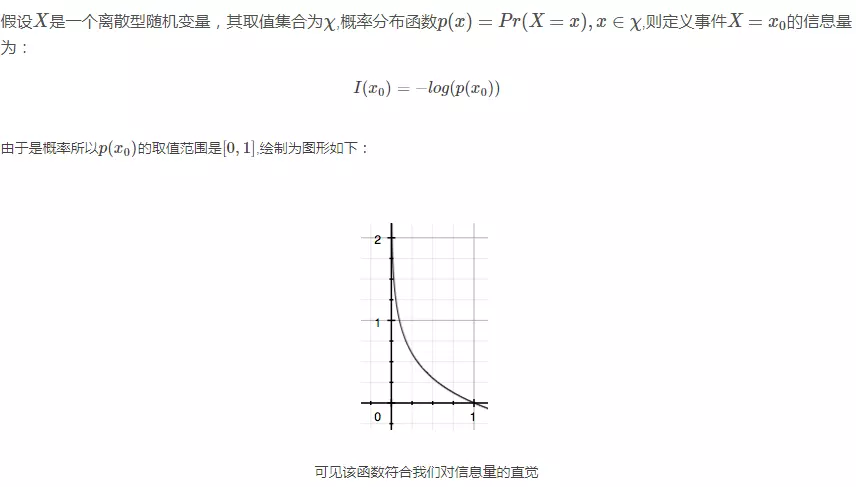
二、什么是熵
熵
对于某个事件,有n种可能性,每一种可能性都有一个概率p(xi)
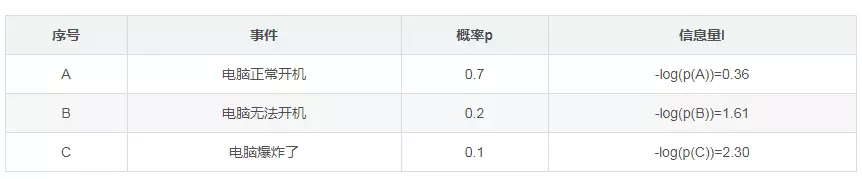
这样就可以计算出某一种可能性的信息量。举一个例子,假设你拿出了你的电脑,按下开关,会有三种可能性,下表列出了每一种可能的概率及其对应的信息量
注:文中的对数均为自然对数
我们现在有了信息量的定义,而熵用来表示所有信息量的期望,即:
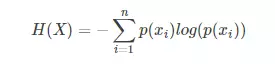
其中n代表所有的n种可能性,所以上面的问题结果就是
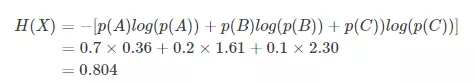
二、 相对熵(KL散度)
相对熵又称KL散度,如果我们对于同一个随机变量 x 有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异
在机器学习中,P往往用来表示样本的真实分布,比如[1,0,0]表示当前样本属于第一类。Q用来表示模型所预测的分布,比如[0.7,0.2,0.1]
KL散度的计算公式:
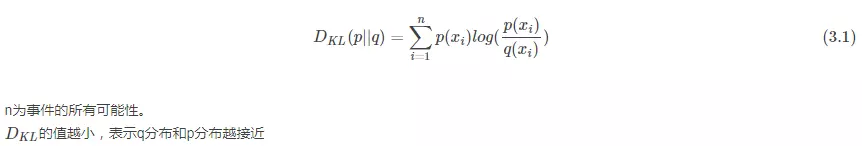
三、什么是交叉熵
交叉熵
对式3.1变形可以得到:
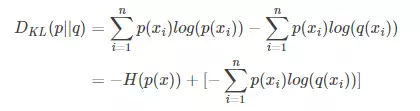
其中p代表label或者叫groundtruth,q代表预测值
在机器学习中,我们需要评估label和predicts之间的差距,使用KL散度刚刚好,即
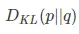
由于KL散度中的前一部分恰巧就是p的熵,p代表label或者叫groundtruth,故−H(p(x))不变,故在优化过程中,只需要关注交叉熵就可以了,所以一般在机器学习中直接用用交叉熵做loss,评估模型。
交叉熵:
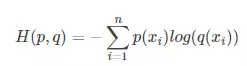
四、softmax_cross_entropy
以tensorflow中函数softmax_cross_entropy_with_logits为例,在二分类或者类别相互排斥多分类问题,计算 logits 和 labels 之间的 softmax 交叉熵。
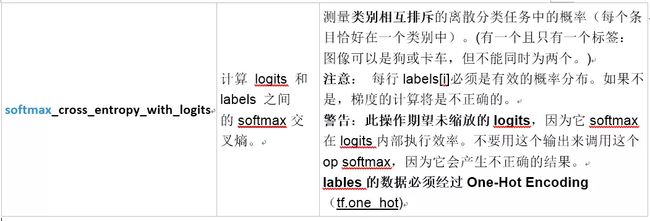
数据必须经过 One-Hot Encoding 编码
tf.one_hot
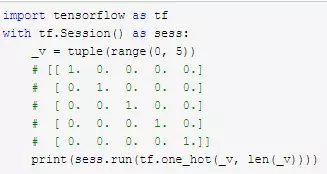
用 mnist 数据举例,如果是目标值是3,那么 label 就是[0,0,0,1,0,0,0,0,0,0],除了第4个值为1,其他全为0。
该函数把一个维度上的 labels 作为一个整体判断,结果给出整个维度的损失值。
这个函数传入的 logits 是 unscaled 的,既不做 sigmoid 也不做 softmax ,因为函数实现会在内部更高效得使用 softmax 。
softmax_cross_entropy_with_logits计算过程
1、对输入进行softmax
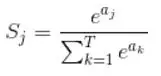
softmax公式
举个例子:假设你的输入S=[1,2,3],那么经过softmax层后就会得到[0.09,0.24,0.67],这三个数字表示这个样本属于第1,2,3类的概率分别是0.09,0.24,0.67。
2、计算交叉熵
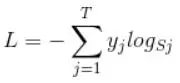
交叉熵公式
L是损失,Sj是softmax的输出向量S的第j个值,前面已经介绍过了,表示的是这个样本属于第j个类别的概率。yj前面有个求和符号,j的范围也是1到类别数T,因此label——y是一个1*T的向量,里面的T个值,而且只有1个值是1,其他T-1个值都是0。真实标签对应的位置的那个值是1,其他都是0。所以这个公式其实有一个更简单的形式:
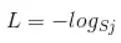
来举个例子吧。假设一个5分类问题,然后一个样本I的标签y=[0,0,0,1,0],也就是说样本I的真实标签是4,假设模型预测的结果概率(softmax的输出)p=[0.1,0.15,0.05,0.6,0.1],可以看出这个预测是对的,那么对应的损失L=-log(0.6),也就是当这个样本经过这样的网络参数产生这样的预测p时,它的损失是-log(0.6)。那么假设p=[0.15,0.2,0.4,0.1,0.15],这个预测结果就很离谱了,因为真实标签是4,而你觉得这个样本是4的概率只有0.1(远不如其他概率高,如果是在测试阶段,那么模型就会预测该样本属于类别3),对应损失L=-log(0.1)。
补充:sparse_softmax_cross_entropy_with_logits
sparse_softmax_cross_entropy_with_logits 是 softmax_cross_entropy_with_logits 的易用版本,除了输入参数不同,作用和算法实现都是一样的。
区别是:softmax_cross_entropy_with_logits 要求传入的 labels 是经过 one_hot encoding 的数据,而 sparse_softmax_cross_entropy_with_logits 不需要。
五、binary_cross_entropy
binary_cross_entropy是二分类的交叉熵,实际是多分类softmax_cross_entropy的一种特殊情况,当多分类中,类别只有两类时,即0或者1,即为二分类,二分类也是一个逻辑回归问题,也可以套用逻辑回归的损失函数。
1、利用softmax_cross_entropy_with_logits来计算二分类的交叉熵
来举个例子,假设一个2分类问题,假如一个batch包含两个样本,那么标签要制成二维,形如
y=[ [1, 0],[0, 1] ],
模型预测输出也为二维,形如
p=[ [0.8,0.2],[0.4,0.6] ] #(softmax的输出)
那么对应的损失
L=( -log(0.8) - log(0.6) ) / 2
实际在计算中若采用softmax_cross_entropy_with_logits函数,不要事先做softmax处理。
2、套用逻辑回归代价损失函数来计算二分类的交叉熵
逻辑回归的损失函数如下:
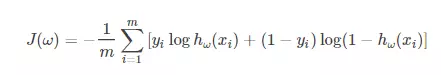
来举个例子,假设一个2分类问题,假如一个batch包含两个样本,那么标签要制成一维,形如
y=[0,1 ],
模型预测输出也为一维,形如
p=[ 0.2,0.6 ] #sigmoid的输出,这里一定要预先用sigmod处理,将预测结果限定在0~1之间,
那么对应的损失
L=( - 0*log(0.2) - (1 - 0)*log(1- 0.2) - log(0.6) - (1 -1)*log(1 - 0.6) ) / 2 = ( -log(0.8) - log(0.6) ) / 2
六、sigmoid_cross_entropy
以tensorflow中函数sigmoid_cross_entropy_with_logits为例说明
sigmoid_cross_entropy_with_logits函数,测量每个类别独立且不相互排斥的离散分类任务中的概率。(可以执行多标签分类,其中图片可以同时包含大象和狗。)
import tensorflow as tf
_logits = [[0.5, 0.7, 0.3], [0.8, 0.2, 0.9]]
_one_labels = tf.ones_like(_logits)
# [[1 1 1]
# [1 1 1]]
_zero_labels = tf.zeros_like(_logits)
# [[0 0 0]
# [0 0 0]]
with tf.Session() as sess:
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=_logits, labels=_one_labels)
print(sess.run(loss))
# [[0.47407699 0.40318602 0.5543552]
# [0.37110069 0.59813887 0.34115386]]
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=_logits, labels=_zero_labels)
print(sess.run(loss))
# [[0.97407699 1.10318601 0.85435522]
# [1.17110074 0.79813886 1.24115384]]
看看sigmoid_cross_entropy_with_logits函数定义
def sigmoid_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, name=None):
#为了描述简洁,规定 x = logits,z = labels,那么 Logistic 损失值为:
z * -log(sigmoid(x)) + (1 - z) * -log(1 - sigmoid(x))
= z * -log(1 / (1 + exp(-x))) + (1 - z) * -log(exp(-x) / (1 + exp(-x)))
= z * log(1 + exp(-x)) + (1 - z) * (-log(exp(-x)) + log(1 + exp(-x)))
= z * log(1 + exp(-x)) + (1 - z) * (x + log(1 + exp(-x))
= (1 - z) * x + log(1 + exp(-x))
= x - x * z + log(1 + exp(-x))该函数与 softmax_cross_entropy_with_logits的区别在于:softmax_cross_entropy_with_logits中的labels 中每一维只能包含一个 1,而sigmoid_cross_entropy_with_logits中的labels 中每一维可以包含多个 1。
softmax_cross_entropy_with_logits函数把一个维度上的 labels 作为一个整体判断,结果给出整个维度的损失值,而 sigmoid_cross_entropy_with_logits 是每一个元素都有一个损失值,都是一个二分类(binary_cross_entropy)问题。
参考:https://www.cnblogs.com/guqiangjs/p/8202899.html