什么是缓冲区溢出以及如何利用漏洞?
在信息安全和编程中,缓冲区溢出是一种异常,其中程序在将数据写入缓冲区时会超出缓冲区边界并覆盖相邻的内存位置。缓冲区是留出的用于存储数据的内存区域,通常是在将数据从程序的一个部分移动到另一部分或在程序之间移动时使用的。如果假设所有输入都小于特定大小,并且缓冲区被创建为该大小,则产生更多数据的异常事务可能导致其写入缓冲区的末尾。
缓冲区溢出概念
缓冲区溢出是指当计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量溢出的数据覆盖在合法数据上,理想的情况是程序检查数据长度并不允许输入超过缓冲区长度的字符,但是绝大多数程序都会假设数据长度总是与所分配的储存空间相匹配,这就为缓冲区溢出埋下隐患,操作系统所使用的缓冲区,又被称为"堆栈"。在各个操作进程之间,指令会被临时储存在"堆栈"当中,"堆栈"也会出现缓冲区溢出。
缓冲区溢出攻击之所以成为一种常见安全攻击手段其原因在于缓冲区溢出漏洞太普遍了,并且易于实现。而且,缓冲区溢出成为远程攻击的主要手段其原因在于缓冲区溢出漏洞给予了攻击者他所想要的一切:奇热植入并且执行攻击代码。被植入的攻击代码以一定的权限运行有缓冲区溢出漏洞的程序,从而得到被攻击主机的控制权。
缓冲区溢出漏洞详解
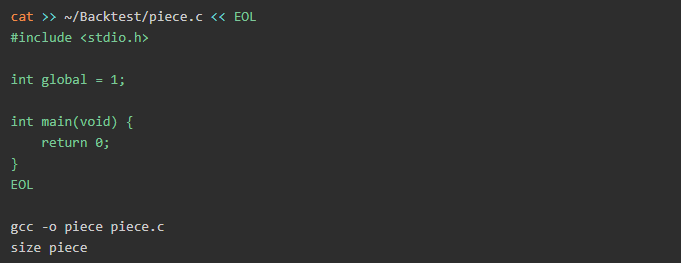
当你使用诸如“C”或“C ++”之类的语言开发程序并使用gcc使用以下命令对其进行编译时:
gcc -o program program.c
你知道gcc如何将你的代码从“C”转换为计算机可执行的机器语言吗?简而言之,我们可以说该过程分3个步骤完成:
“C”中的代码将转换为汇编语言,该汇编语言是二进制之后的最低级语言。此时,汇编代码被翻译成二进制。可执行文件是“链接的”,换句话说,链接是由代码使用的库建立的。
现在让我们看一下汇编器的基础知识,因为这种语言对于理解开发过程至关重要。
section .text global _start _start: push rdx mov rdi, 0x4444444444444444 ; v_addr mov rsi, 0x5555555555555555 ; len mov rdx, 0x7 ; RWX mov rax, 10 ; mprotect0x80483dc syscall mov rcx, 0x2222222222222222 mov rsi, 0x3333333333333333 mov rdx, 0x6666666666666666 ; random_int mov rdi, rsi jmp _loop _loop: cmp rcx, 0x0 je _end lodsb not al xor al, dl stosb loop _loopon _end: pop rdx mov rax, 0x1111111111111111 jmp rax
上面这段代码的目的只是向你展示它的外观。如你所见,代码是由诸如push,mov,cmp等指令组成的。
; Note, in assembler everything behind a semicolon is considered as a comment call 0x80483dc; Call function at address 0x80483dc push 0x0; puts the value 0x0 on the stack pop ebx; put what is at the top of the stack in ebx mov eax, 0x1; puts 0x1 in eax
如你所见,并不复杂。eax或ebx这些就是我们所说的寄存器。在其中存储一些值,例如地址,数字等。对于32位处理器,寄存器eax,ebx,ecx,edx,ebp,esp,eip和edi大小为8位。还有其他寄存器,但老实说,它们暂时对我们没有任何意义。还有一件事,对于64位处理器,我们将使用相同的寄存器,只是它们将是16位而不是8位,并且“e”将替换为“r”,因此寄存器名称将变为rax,rbx ,rcx,rdx,rbp,rsp,rip和rdi。
内存段
.data-存储全局变量的段;.bss-包含静态变量;.text-包含我们的代码,可能还不够清楚,所以让我们用一些代码来说明一下:

在上面的示例中,我们可以看到以下内容:
a和b在.bss中,c被放在堆栈上,而我们的函数主要在.text中。
让我们看看如何反汇编程序:

我们将通过编译上面的一小段代码进行测试。首先,打开你的终端,并简单地一个接一个地使用以下命令:
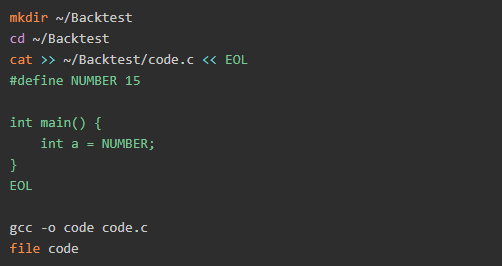
输出内容:

现在,我们已经编译了文件,我们将使用objdump对其进行反编译,objdump是大多数现代GNU / Linux发行版中提供的线性反汇编工具。
objdump -M intel -d code
输出内容:
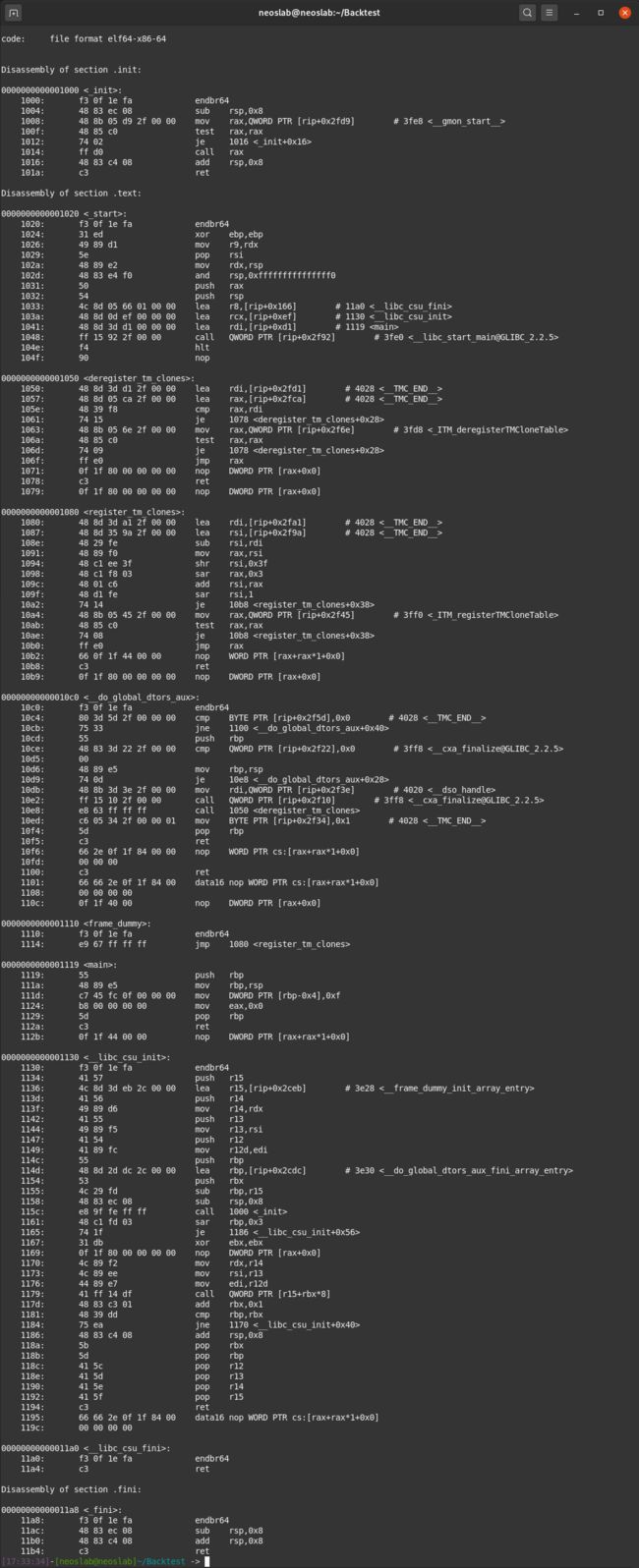
你所看到的一切都是正确的!从上面的屏幕截图中,我们将重点放在“0000000000001119

让我们继续检查一下我们程序的确切函数:
推送rbp,将rbp放入堆栈;
mov rbp,rsp,将rsp放入rbp;
mov DWORD PTR [rbp-0x4],0xf将0xf(十六进制为15)放入rbp;
mov eax,0x0将0放入eax;
pop rbp将什么放在栈顶中;
如你所见,没有定义变量。我们甚至可以说也没有变量名,但是最终我们在rbp中确实有15个。
让我们看一下这段代码:

输出内容:

从上面的输出中,我们将了解每个会话的大小。到目前为止,你可以看到引用的bss列的大小为“8”。
现在让我们看看如果通过添加新变量来修改代码:
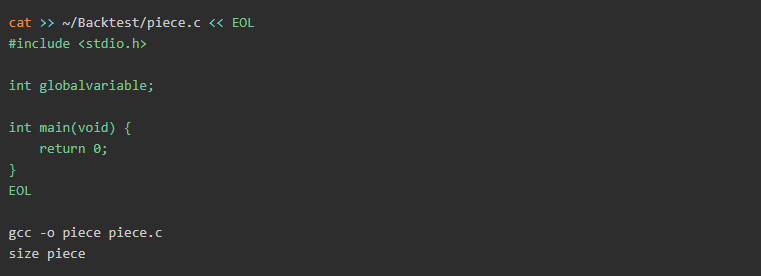
输出内容:

如你所见,bss从8个字节增加到12个字节,我们可以轻松地认为我们的全局变量存储在bss中,因为他的值确实增加了。
现在,我们将在主函数中包含一个静态变量,以进行另一项测试,然后看看会发生什么。
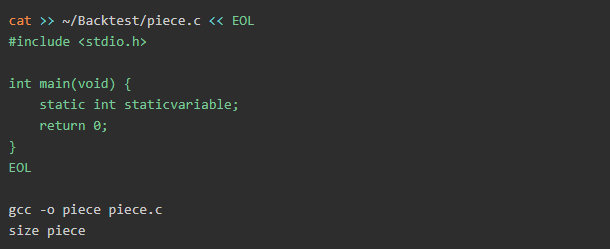
输出内容:

如你所见,变量没有像前面的示例那样存储在bss中,而是存储在从512字节变为516字节的数据中。看起来很有趣,不是吗?
进行最终测试,以了解如果初始化全局变量会发生什么。
输出内容:

我们得到相同的结果,你知道为什么吗?全局变量(如果已初始化)将被放入数据中。我认为如果此时已经开发了足够的内容,可以让你了解变量的存储位置和存储方式。
内存如何运作?
现在,我们将不谈论你的物理内存,而是谈论RAM及其如何由操作系统管理。在计算机上运行的进程需要内存,而在计算机中,内存量是有限的。
因此,进程必须寻找可用的内存才能工作。假设有多个进程同时运行。如果两个进程想要访问相同的内存区域,将会发生什么?而且,如果某个进程写入了一个内存区域,那么另一个进程将用其数据覆盖该相同的内存区域,那么第一个进程将考虑找到其数据,但它将找到第二个进程的数据。这可能是一个很大的问题,不是吗?
通过为每个进程分配一定范围的虚拟内存,在32位系统上限制为4GB,在64位系统上限制为8 GB,这是操作系统的主要函数用来解决此问题的位置。
每个进程将能够使用所需的内存地址,而不必担心其他进程,操作系统的内核将设法链接虚拟内存和实际内存。
栈和堆
现在,我们将继续进行一些非常重要的事情,堆可以由程序员操纵。这是写入动态分配的内存区域malloc()或calloc()的内存部分。
此存储区域没有固定大小,它根据我们的要求增加或减少,我们可以通过分配或释放算法保留或删除块以供将来使用。堆大小越大,内存地址越大,并且它们与堆栈中的内存地址越接近。与堆栈不同,除了物理内存限制外,堆中变量的大小不受限制。
程序中的任何地方都可以使用指针访问堆中存储的变量,堆栈的大小也可变,但是堆栈的大小增加得越大,内存地址减少的越多,从而接近堆的顶部。函数的堆栈框架是堆栈中的一个存储区域,在其中存储了调用此函数所需的所有信息,该函数还有局部变量。
理解堆栈的概念
让我们从LIFO开始讲起,它并不代表任何复杂的事情,因为我们之前已经看到过。 LIFO代表后进先出。这就是说,放到栈上的最后一件事是我们要发布的第一个东西,尤其是通过pop和push看到的。
最终缓冲区溢出
最后,我们进入开发部分。让我们来看下面的一小段代码。

该代码看起来完全正常,在学习“C”语言时必须使用scanf函数。但是,如果我们看一下此示例中的堆栈,该怎么办。
[buffer (100)] [int a] [saved ebp] [saved eip]
你可能想知道保存的ebp和eip是什么?其实,我们不在乎“保存的ebp”,我们感兴趣的是“保存的eip”。你还记得eip包含什么吗?下一条要执行的指令的地址。如果我们更改此地址,我们可以执行任何操作!
但是,如何更改此值?这很简单!你会发现scanf不会检查接收到的字符数!让我们用以下一段代码来演示。

如果在执行scanf时给出的值太大(例如,多个“A”),则会导致缓冲区溢出。因此,该程序将向我们返回分段错误。但是,如果我们通过有效地址更改“A”值,则可以跳转到任何位置,特别是在adminfunction()上。
缓冲区溢出和远程堆溢出的区别,以iOS Mail 客户端MFMutable中的远程堆溢出为例。
在分析代码流时,我们确定了以下内容:
1.以原始MIME格式下载电子邮件时,会调用函数[MFDAMessageContentConsumer ConsumerData:length:format:mailMessage:],并且该函数也会多次调用,直到电子邮件以交换模式下载为止。它将创建一个新的NSMutableData对象,并为属于同一电子邮件/ MIME消息的任何新流数据调用appendData:。对于其他协议(例如IMAP),它改用-[MFConnection readLineIntoData:],但逻辑和漏洞是相同的。
2.NSMutableData将阈值设置为0x200000字节,如果数据大于0x200000字节,它将把数据写入文件,然后使用mmap系统调用将文件映射到设备内存。阈值大小0x200000可以轻易增加,因此每次需要添加新数据时,都会重新映射文件,并且文件大小以及mmap大小也会越来越大。
3.重新映射是在-[MFMutableData _mapMutableData:]内部完成的,该漏洞位于此函数内部。
易受攻击的函数的伪代码如下:-[MFMutableData _mapMutableData:] 在mmap系统调用失败时调用函数 MFMutableData__mapMutableData___block_invoke。
MFMutableData__mapMutableData___block_invoke的伪代码如下,它分配一个大小为8的堆内存,然后用分配的内存替换data-> bytes指针。
在执行-[MFMutableData _mapMutableData:]之后,进程继续执行-[MFMutableData appendBytes:length:],从而在将数据复制到分配的内存时导致堆溢出。
append_length是来自流式传输的数据块的长度,由于MALLOC_NANO是一个可预测的内存区域,因此可以利用此漏洞。
攻击者不需要耗尽最后一点内存来导致mmap失败,因为mmap需要一个连续的内存区域。
根据mmap的操作说明,如果指定了MAP_ANON并且可用内存不足,则mmap将失败。
目标是使mmap失败,理想情况下,一封足够大的邮件将不可避免地导致失败。但是,我们认为,可以使用其他可以耗尽资源的技巧来触发漏洞。这些技巧可以通过多部分、RTF和其他格式来实现,我们会在稍后再介绍。
另一个影响可利用性的重要因素是硬件规格:iPhone 6拥有1GB内存;iPhone 7有2GB内存;iPhone X有3GB内存;
较旧的设备具有较小的物理RAM和较小的虚拟内存空间,因此没有必要耗尽所有的RAM来触发这个漏洞,当mmap在可用的虚拟内存空间中找不到给定大小的连续内存时,它就会失败。
我们已经确定,MacOS不会同时受到这两个漏洞的攻击。
在iOS 12中,触发漏洞更容易,因为数据流传输是在同一过程中完成的,因为默认邮件应用程序(MobileMail)会处理更多的资源,从而耗尽分配的虚拟内存空间(尤其是UI),而在iOS 13中,MobileMail将数据流传递到后台进程(即邮件)。它把资源集中在解析电子邮件上,从而降低了虚拟内存空间意外耗尽的风险。
由于MobileMail / maild并未明确设置电子邮件大小的最大限制,因此可以设置自定义电子邮件服务器并发送包含几GB纯文本的电子邮件。 iOS MIME /消息库在流式传输数据时将数据平均分成大约0x100000字节,因此完全可以不下载整个电子邮件。
请注意,这只是如何触发此漏洞的一个示例。攻击者无需发送此类电子邮件即可触发此漏洞,并且采用多部分、RTF或其他格式的其他技巧也可以使用标准大小的电子邮件实现相同的目标。
目前,苹果修复了iOS 13.4.5 beta中的两个漏洞,如以下屏幕截图所示:
为了缓解这些漏洞,你可以使用最新版的Beta。如果无法使用Beta版,不过要禁用邮件应用程序,并使用不易受攻击的Outlook,Edison Mail或Gmail。