20年的目标检测大综述(章节2+)

本栏目由计算机视觉战队独家呈献
今天我们继续接着上期第二章节继续说下去,但是今天内容较多,我们依然分两期把他说完。今天主要说说目标检测技术演变历程,我们一起来学习,共同进步!
Technical Evolution in Object Detection
Early Time’s Dark Knowledge
早期的目标检测 ( 在00年以前 ) 没有遵循滑动窗口检测等统一的检测理念。当时的检测器通常基于如下低层和中层的视觉设计。
(1)Components, shapes and edges(组件、形状和边缘)
“ 分量识别(Recognition-by-components)” 作为一种重要的认知理论,长期以来一直是图像识别和目标检测的核心思想。一些早期的研究人员将目标检测定义为测量对象组件、形状和轮廓之间的相似性,包括距离变换、形状上下文、小边特征等。尽管最初的结果很有希望,但在更复杂的检测问题上,事情进展得并不顺利。因此,基于机器学习的检测方法开始蓬勃发展。
基于机器学习的检测经历了包括外观统计模型在内的多个阶段 ( 1998年以前 ) 、小波特征表示 ( 1998-2005 ) 和基于梯度的表示 ( 2005-2012 )。
建立对象的统计模型,比如特征面(Eigenfaces)如下图(a)所示,是目标检测历史上第一波基于学习的方法。1991年,M.Turk等人利用特征脸分解技术在实验室环境中实现了实时人脸检测。与当时基于规则或模板的方法相比,统计模型通过从数据中学习特定于任务的知识,更好地提供了对象外观的整体描述。

自2000年以来,小波特征变换开始主导视觉识别和目标检测。这组方法的本质是通过将图像从像素点转换为一组小波系数来学习。其中,Haar小波由于其计算效率高,被广泛应用于一般目标检测、人脸检测,行人检测等目标检测任务中。下图(d)为VJ检测器学习到的一组用于人脸的Haar小波基。

(2)Early time’s CNN for object detection
使用CNN检测物体的历史可以追溯到20世纪90年代,当时Y. LeCun等人做出了巨大的贡献。由于计算资源的限制,当时的CNN模型比现在的模型要小得多,也要浅得多。尽管如此,在早期基于CNN的检测模型中,计算效率仍然被认为是难以破解的难题之一。Y. LeCun等人进行了一系列改进,如 “ 共享权值复制神经网络(shared-weight replicated neural network) ”和“ 空间位移网络(space displacement network)”通过扩展卷积网络的每一层,覆盖整个输入图像,减少计算量,如下图(b)-(c)所示。
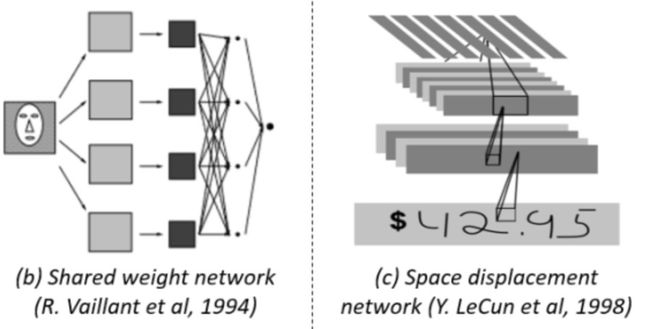
这样,只需一次网络的正向传播,就可以提取出整个图像任意位置的特征。这可以看作是当今全卷积网络 ( FCN ) 的原型,FCN 几乎是在20年后提出的。CNN也被应用于其他任务,如人脸检测和手势实时跟踪(hand tracking of its time)。
Technical Evolution of Multi-Scale Detection
多尺度检测(Multi-scale detection)对象的 “ 不同尺寸 ” 和 “ 不同纵横比 ” 是目标检测的主要技术难题之一。近20年来,多尺度检测经历了多个历史时期:“ 特征金字塔和滑动窗口(2014年前) ”,“ 基于对象建议的检测(2010-2015年) ”,“ 深度回归(2013-2016) ”、“ 多参考检测( multi-reference detection,2015年后 ) ”、“ 多分辨率检测( multi-resolution detection,2016年后 ) ”,如下图所示:
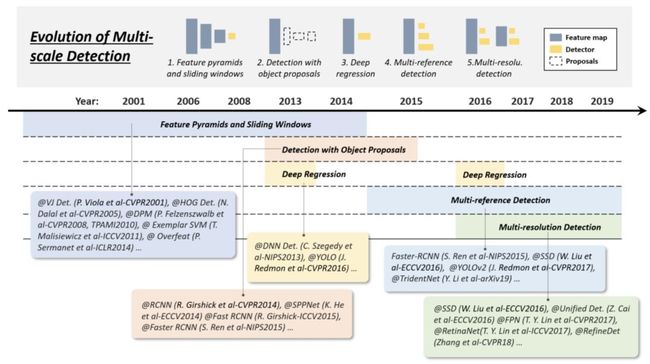
(1)Feature pyramids + sliding windows (before 2014)
随着VJ检测器后计算能力的提高,研究者们开始更加关注一种直观的检测方法,即构建 “ 特征金字塔+滑动窗口 ”。从2004年到2014年,基于这种检测范式构建了许多里程碑式的检测器,包括HOG检测器、DPM,甚至深度学习时代的Overfeat检测器( ILSVRC-13定位任务获奖者 )。
早期的检测模型,如VJ检测器和HOG检测器,都是专门针对具有 “ 固定长宽比 ” (如人脸和直立的行人)的对象,只需构建特征金字塔,并在其上滑动固定大小检测窗口。当时没有考虑检测 “ 各种纵横比 ”。为了检测具有更复杂外观(如 PASCAL VOC 中的外观)的对象,R. Girshick等人开始在特征金字塔外寻找更好的解决方案。“ 混合模型 ”是当时最好的解决方案之一,它通过训练多个模型来检测不同纵横比的物体。除此之外,基于范例的检测通过为训练集的每个对象实例 ( 范例 ) 训练单独的模型,提供了另一种解决方案。
随着现代数据集中的对象(例如MS-COCO)变得更加多样化,混合模型或基于范例的方法不可避免地会导致更加复杂的检测模型。于是一个问题就自然而然地产生了:是否存在一种统一的多尺度方法来检测不同长宽比的对象? “ 对象建议(object proposals) ” 的提出已经回答了这个问题。
(2)Detection with object proposals (2010-2015)
对象建议(object proposals)引用一组可能包含任何对象的与类无关的候选框。它于2010年首次应用于目标检测。使用对象建议进行检测有助于避免对图像进行彻底的滑动窗口搜索。
目标/对象建议检测算法应满足以下三个要求:
1) 高召回率,
2) 高定位准确率,
3) 在前两个要求的基础上,提高精度,减少处理时间。
现代的建议检测方法可以分为三类:1) 分割分组方法,2) 窗口评分方法,3) 基于神经网络的方法。我们建议读者阅读以下论文,以全面回顾这些方法。
早期的建议检测方法遵循自底向上的检测理念,深受视觉显著性检测的影响。后来,研究人员开始转向低水平的视觉 ( 如边缘检测 ) 和更精细的手工技能,以改进候选框的定位。2014年以后,随着深度CNN在视觉识别领域的普及,基于自上而下学习的方法在这个问题上开始显示出更多的优势。从那时起,对象建议检测就从自下而上的视觉演化为 “ 对一组特定对象类的过度拟合 ”,检测器与建议生成器之间的区别也变得模糊。
随着 “ object proposal ” 对滑动窗口检测的革命性变革,并迅速主导基于深度学习的检测器,2014-2015年,许多研究者开始提出以下问题:object proposal 在检测中的主要作用是什么? 是为了提高准确度,还是仅仅为了加快检测速度? 为了回答这个问题,一些研究人员试图削弱 proposal 的作用或单纯对CNN特征进行滑动窗口检测,均未得到满意的结果。在单级检测器和 “ 深度回归 ” 技术兴起之后,建议检测很快就淡出了人们的视线。
(3)Deep regression (2013-2016)
近年来,随着GPU计算能力的提高,人们处理多尺度检测的方式变得越来越直接和暴力。使用深度回归来解决多尺度问题的思想非常简单,即,基于深度学习特征直接预测边界框的坐标。这种方法的优点是简单易行,缺点是定位不够准确,特别是对于一些小对象。“ 多参考检测 ” 解决了这一问题。
(4)Multi-reference/-resolution detection (after 2015)
多参考检测是目前最流行的多尺度目标检测框架。它的主要思想是在图像的不同位置预先定义一组不同大小和宽高比的参考框(即锚框),然后根据这些参考框预测检测框。每个预定义锚框的典型损失包括两部分:1) 类别识别的交叉熵损失;2) 目标定位的L1/L2回归损失。损失函数的一般形式可以写成如下形式:
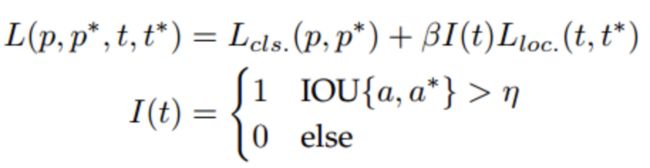
其中t和t*是predicted和ground-truth的边界框的位置,p和p*是它们的类别概率。IOU{a,a*}是锚框a和它ground-truth a*之间的IOU。η是一个IOU阈值,比如0.5。如果锚框没有覆盖任何对象,其定位损失不计入最终损失。
近两年来另一种流行的技术是多分辨率检测,即在网络的不同层检测不同尺度的目标。由于CNN在正向传播过程中自然形成了一个特征金字塔,更容易在较深的层中检测到较大的物体,在较浅的层中检测到较小的物体。多参考和多分辨率检测已成为当前最先进的目标检测系统的两个基本组成部分。
通知
计算机视觉战队正在组建深度学习技术群,欢迎大家私信申请加入!
加入“计算机视觉战队”,一起学习!
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。

我们开创一段时间的“计算机视觉协会”知识星球,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。
