关于siamfc++代码的几个要点
Siamfc++是较早发表的anchor-free的单目标跟踪器,可说是比较经典的,所以有精读的必要,就像siamfc一样。下面就几点代码中比较重要的部分写一下,以便后续回想。

1、data pair的生成和增强
datapipeline主要由下面三部分构成,在videoanalyst/data/datapipeline/builder.py有体现:
sampler = build_sampler(task, cfg.sampler, seed=seed)
transformers = build_transformer(task, cfg.transformer, seed=seed) # a list of TransformerBase
target = build_target(task, cfg.target)
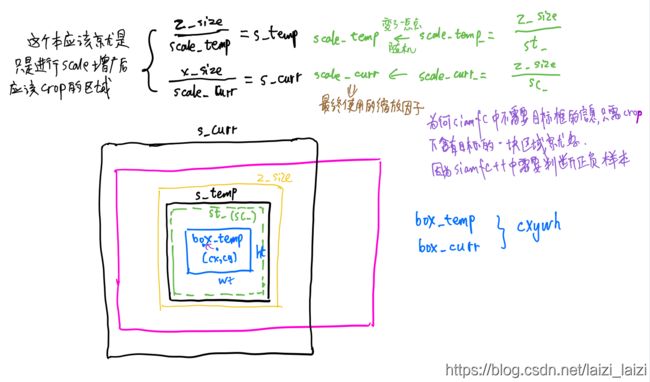
build_sampler从同一个序列中产生一个positive pair或者是从不同序列中产生一个negative pair,然后,送给 build_transformer进行数据增广,主要有scale和shift,使search patch和templete patch并不是正好目标中心对着的,会有一点偏移【这一部分其实和siamfc是差不多的,只是用了一个集crop和resize的更高效的函数cv2.warpAffine,而不再是cv2.copyMakeBorder】;然后又送给build_target来构造label。都调用了三种方法的__call__方法,最后返回的是:
training_data = dict(
im_z=im_z, # 经过crop和resize之后的templete patch
im_x=im_x, # 经过crop和resize之后的search patch
bbox_z=bbox_z, #坐标相对于im_z的templete gt_bbox
bbox_x=bbox_x, #坐标相对于im_x的search gt_bbox
cls_gt=cls_label, # (h*w ,1)的cls label
ctr_gt=ctr_label, # (h*w ,1)的ctr label
box_gt=box_label, # (h*w ,4)的reg label
is_negative_pair=int(is_negative_pair), # 标志位
)
然后将training_data送入到DataLoader()中去构成batch的数据
其中build_transformer是比较难理解的,可以参考下面这幅图辅助理解:
下面是对visdrone的uav0000043_00377_s序列的可视化:

2、label的构造
因为有classification、regression和centerness分支,所以有三个头部的label【类似FCOS】:
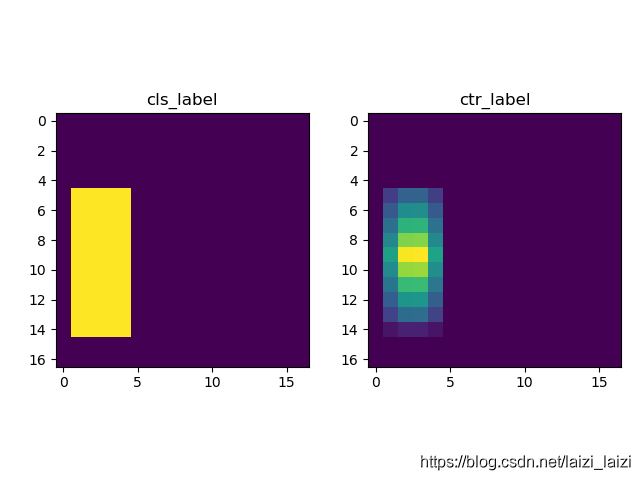
- classification分支:这个就像论文中说的,当score map的位置映射回search patch,如果在im_x的gt_bbox中,则赋值为1,其他为0,假定在其中的这块区域记作
gt_on_fm(对于negative_pair,则1的地方为0,0的地方为-1) - centerness分支:在
gt_on_fm中撒一些类似高斯分布的点,范围是[0, 1] - regression分支:在四个通道
ltrb的gt_on_fm区域分别赋值为bbox_x的 ( x 0 , y 0 , x 1 , y 1 ) (x_{0},y_{0},x_{1},y_{1}) (x0,y0,x1,y1)
进行可视化之后的样子是这样的:

这里面需要注意一点,centerness其实是从下面红框中选出来的(红框就是im_x上的GT BBox,具体请看make_densebox_target函数):
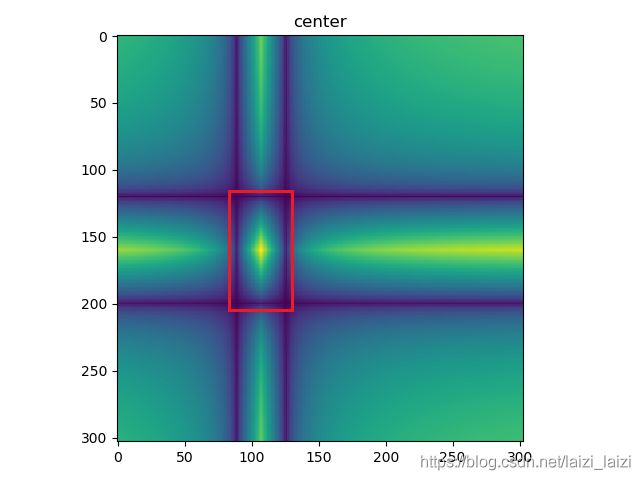
这一步最重要的就是如何判断score map的位置映射回search patch是否在在im_x的gt_bbox中,分享原作者的一次分享【这里面减1的原因是间距数是点数-1】:

3、loss的写法
loss的话因为有三个分支,所以也有三个部分:classification的focal loss;regression的IoU loss和centerness的BCE loss。
3.1、focal loss
focal loss的公式就是:
f o c a l l o s s = − α ( 1 − y ^ ) γ y l o g ( y ^ ) − ( 1 − α ) y ^ γ ( 1 − y ) l o g ( 1 − y ^ ) focal loss=-\alpha(1-\hat y)^{\gamma}ylog(\hat y)-(1-\alpha)\hat y^{\gamma} (1-y)log(1-\hat y) focalloss=−α(1−y^)γylog(y^)−(1−α)y^γ(1−y)log(1−y^)
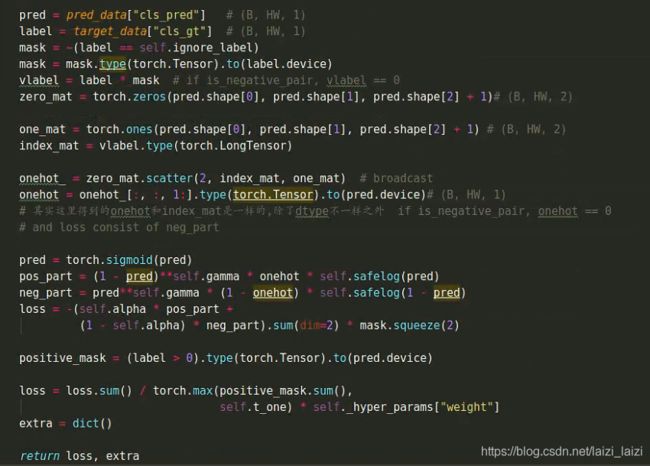
其中 α \alpha α用来关注正负样本, γ \gamma γ调节难易样本。学习的目标就是让预测的gt_on_fm区域接近1,其余接近0,因为只有一个输出通道(因为二分类,不像有的就是输出两个通道,都一样),下面是代码截图:注意,如果对于is_negative_pair只有neg_part的损失:
3.2、binary cross entropy loss
这是对于centerness分支的,BCE loss公式是:
B C E l o s s = − z l o g ( x ) − ( 1 − z ) l o g ( 1 − x ) BCE loss=-zlog(x)-(1-z)log(1-x) BCEloss=−zlog(x)−(1−z)log(1−x),这里的 x x x是logits,
有一个稳定版的:推导过程可以看这里
B C E l o s s = m a x ( x , 0 ) − x ∗ z + l o g ( 1 + e − ∣ x ∣ ) BCE loss=max(x, 0) - x * z + log(1 + e^{-\left|x \right|}) BCEloss=max(x,0)−x∗z+log(1+e−∣x∣),所以代码如下:

但是这里为什么会有个loss_residual呢?因为我们的centerness label是介于[0, 1]直接的float数,而不是{0, 1},所以不同于一般的BCE loss的最小值为0,所以我们要算出此时情况下的最小值,然后减去这一项,推导过程如下(佩服作者的代码严谨性):
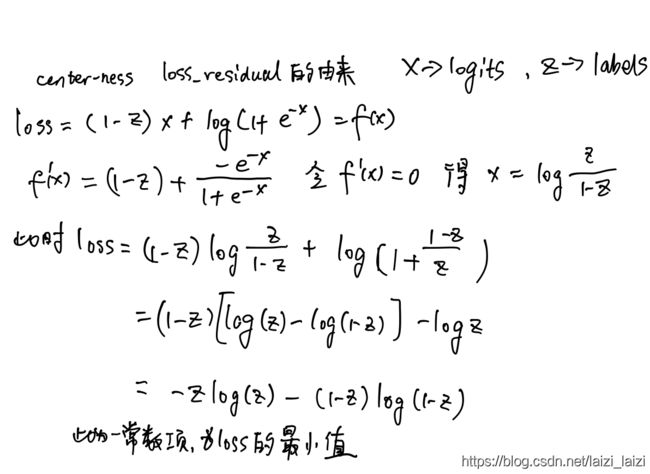
3.3、IoU loss
最初的IoU loss来自论文UnityBox,公式是: − l n ( I o U ) -ln(IoU) −ln(IoU),因为我们regression预测的是offsets,通过逆向求解出预测的bbox_pred(这其实是head的输出),而target是真实bbox_x的 ( x 0 , y 0 , x 1 , y 1 ) (x_{0},y_{0},x_{1},y_{1}) (x0,y0,x1,y1):
l ∗ = ( ⌊ s 2 ⌋ + x s ) − x 0 , t ∗ = ( ⌊ s 2 ⌋ + y s ) − y 0 r ∗ = x 1 − ( ⌊ s 2 ⌋ + x s ) , b ∗ = y 1 − ( ⌊ s 2 ⌋ + y s ) \begin{array}{ll} l^{*}=\left(\left\lfloor\frac{s}{2}\right\rfloor+x s\right)-x_{0}, & t^{*}=\left(\left\lfloor\frac{s}{2}\right\rfloor+y s\right)-y_{0} \\ r^{*}=x_{1}-\left(\left\lfloor\frac{s}{2}\right\rfloor+x s\right), & b^{*}=y_{1}-\left(\left\lfloor\frac{s}{2}\right\rfloor+y s\right) \end{array} l∗=(⌊2s⌋+xs)−x0,r∗=x1−(⌊2s⌋+xs),t∗=(⌊2s⌋+ys)−y0b∗=y1−(⌊2s⌋+ys)然后计算他们之间的IoU及IoU loss(注意只计算gt_on_fm的点 ( x , y ) (x, y) (x,y)映射回im_x后的框):

4、tracking的流程

这里放一下penalty和window influence的语句吧:
#r_c和s_c分别是当前预测框和上一帧目标的ratio和scale的比值,越大惩罚越强
penalty = np.exp(-(r_c * s_c - 1) * penalty_k)
pscore = penalty * score
# cos window (motion model)
window_influence = self._hyper_params['window_influence']
pscore = pscore * (1 - window_influence) + self._state['window'] * window_influence
best_pscore_id = np.argmax(pscore)
最后返回原图进行框中心的确定,然后采用线性更新策略来更新当前帧的框的大小:
pred_in_crop = box_wh[best_pscore_id, :] / np.float32(scale_x)
# about np.float32(scale_x)
# attention!, this casting is done implicitly
# which can influence final EAO heavily given a model & a set of hyper-parameters
# box post-postprocessing
test_lr = self._hyper_params['test_lr']
lr = penalty[best_pscore_id] * score[best_pscore_id] * test_lr
res_x = pred_in_crop[0] + target_pos[0] - (x_size // 2) / scale_x
res_y = pred_in_crop[1] + target_pos[1] - (x_size // 2) / scale_x
res_w = target_sz[0] * (1 - lr) + pred_in_crop[2] * lr
res_h = target_sz[1] * (1 - lr) + pred_in_crop[3] * lr
原文关于测试阶段的描述

5、Bonus
视频讲解:https://www.bilibili.com/video/BV1Hp4y1S74D/
PS
源码阅读笔记下载:https://download.csdn.net/download/laizi_laizi/12676399
videoanalyst/pipeline/utils/crop.py下的cv2.warpAffine的用法可以参考这篇