第四章 Redis性能测试、手写及事务笔记
一、Redis慢查询分析
与mysql一样,当执行时间超过极大值时,会将发生时间耗时、命令记录
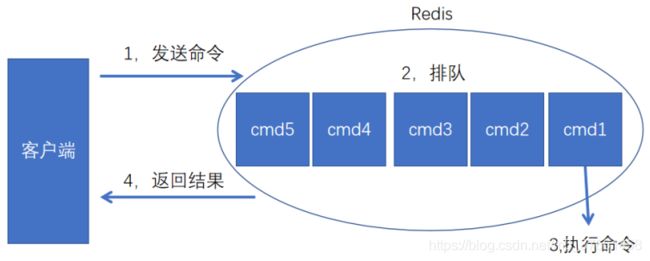
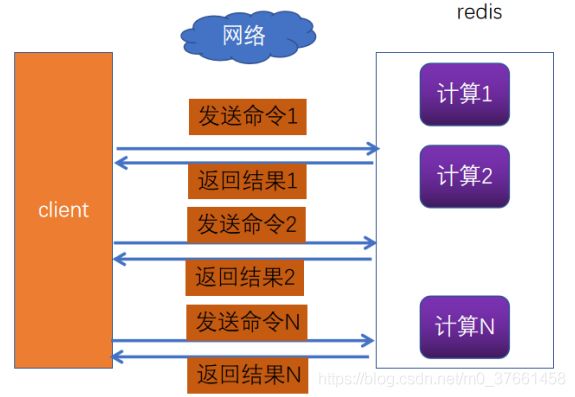
redis命令生命周期:发送、排队、执行、返回
慢查询只统计第3个执行步骤的时间
1、慢查询原理
慢查询记录也是存在队列里的,slow-max-len存放的记录最大条数,比如设置的slow-max-len=10,当有第11条慢查询命令插入时,队列的第一条命令就会出列,第11条入列到慢查询队列中,可以config set动态设置,也可以修改redis.conf完成配置。
2、慢查询极值设置
注:有两种方式,默认为10毫秒
1)动态设置指令: config set slowlog-log-slower-than 10000 //10毫秒
使用config set完后,若想将配置持久化保存到redis.conf,要执行config rewrite
2)配置文件redis.conf修改:找到slowlog-log-slower-than 10000,修改保存即可。
注意:slowlog-log-slower-than =0记录所有命令 -1命令都不记录
3、慢查询命令
获取队列里慢查询的命令:slowlog get
获取慢查询列表当前的长度:slowlog len //以上只有1条慢查询,返回1;
1)对慢查询列表清理(重置):slowlog reset //再查slowlog len此时返回0 清空;
2)对于线上slow-max-len配置的建议:线上可加大slow-max-len的值,记录慢查询存长命令时redis会做截断,不会占用大量内存,线上可设置1000以上。
3)对于线上slowlog-log-slower-than配置的建议:默认为10毫秒,根据redis并发量来调整,对于高并发比建议为1毫秒。
4)慢查询是先进先出的队列,访问日志记录出列丢失,需定期执行slowlog get,将结果存储到其它设备中(如mysql)。
4、Redis上线前应该做的事
Redis性能实战
1)100个并发连接,10000个请求,检测服务器性能
./redis-benchmark -h 192.168.30.156 -p 6379 -c 100 -n 10000
执行结果如下:
====== SET ======
10000 requests completed in 0.15 seconds
100 parallel clients
3 bytes payload
keep alive: 1
43.40% <= 1 milliseconds
98.79% <= 2 milliseconds
99.78% <= 3 milliseconds
100.00% <= 3 milliseconds
64935.07 requests per second
====== GET ======
10000 requests completed in 0.16 seconds
100 parallel clients
3 bytes payload
keep alive: 1
42.83% <= 1 milliseconds
98.79% <= 2 milliseconds
100.00% <= 2 milliseconds
64102.56 requests per second
====== INCR ======
10000 requests completed in 0.15 seconds
100 parallel clients
3 bytes payload
keep alive: 1
44.16% <= 1 milliseconds
98.31% <= 2 milliseconds
100.00% <= 2 milliseconds
64935.07 requests per second
====== LPUSH ======
10000 requests completed in 0.15 seconds
100 parallel clients
3 bytes payload
keep alive: 1
44.59% <= 1 milliseconds
99.14% <= 2 milliseconds
100.00% <= 2 milliseconds
64935.07 requests per second
......
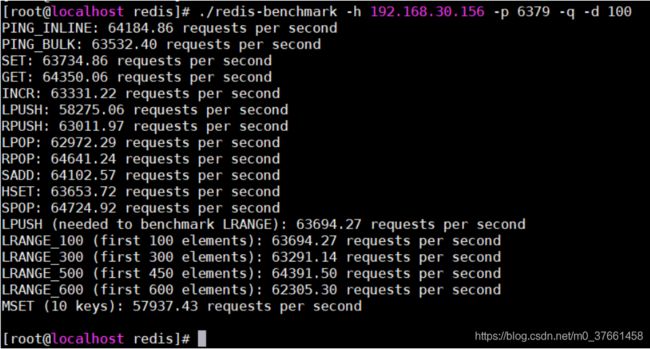
2)测试存取大小为100字节的数据包的性能
./redis-benchmark -h 192.168.30.156 -p 6379 -q -d 100
3)只测试 set,lpush操作的性能,10000个请求
./redis-benchmark -h 192.168.30.156 -p 6379 -t set,get -n 100000 -q
执行结果:
[root@localhost redis]# ./redis-benchmark -h 192.168.30.156 -p 6379 -t set,get -n 100000 -q
SET: 65231.57 requests per second
GET: 64892.93 requests per second
4)只测试某些数值存取的性能,10000个请求
./redis-benchmark -h 192.168.30.156 -p 6379 -n 100000 -q script load "redis.call('set','foo','bar')"
执行结果:
script load redis.call('set','foo','bar'): 63131.31 requests per second
二、Redis运行原理流程
发送命令-〉命令排队-〉命令执行-〉返回结果
1、什么是RESP协议?
Redis服务器与客户端通过RESP(Redis Serialization Protocol)协议通信,要以下特点:容易实现,解析快,人类可读。RESP底层采用的是TCP的连接方式,通过tcp进行数据传输,然后根据解析规则解析相应信息,完成交互。
我们可以测试下,首先运行一个serverSocket监听6379,来接收redis客户端的请求信息,实现如下服务端程序如下:
2、RESP抓包实战
使用Jedis模拟请求伪服务端,抓包测试分析
客户端测试代码:
public class ClientTest {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
jedis.set("name","rehash");
jedis.close();
}
}服务端伪的redis代码示例:
public class ServerRedis {
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(6379);
Socket rec = serverSocket.accept();
byte[] result = new byte[2048];
rec.getInputStream().read(result);
System.out.println(new String(result));
} catch (IOException e) {
e.printStackTrace();
}
}
}启动ServerRedis然后运行ClientTest保存数据(报错忽略),服务端返回结果如下:
*3 //代表有三组数据
$3 //第一组指令长度为3
SET //第一组指令为“set”
$4 //第二组执行长度为4
name //第一组指令为key值:name
$6 //第三组指令长度为6
rehash //第三组指令为对应的value值:rehash
结论:Redis通讯使用了RESP协议。
通过官网查看RESP协议:https://redis.io/topics/protocol
Redis clients communicate with the Redis server using a protocol called RESP (REdis Serialization Protocol). While the protocol was designed specifically for Redis, it can be used for other client-server software projects.
RESP is a compromise between the following things:
·Simple to implement.
·Fast to parse.
·Human readable.
3、将你现有表数据快速存放到Redis
技术分析:数据库表快速导入到Redis
1)登录连接到数据库:mysql -uroot -proot
虚拟机:CentOS 7 64-MySQL
登录账号密码:root /chj@7
测试查询:
mysql> mysql -uroot -p'root'
mysql> use hankin;
2)执行sql查询语句:select * from order,返回结果result(order.sql文件)。
3)登录到Redis:./redis-cli -h 192.168.30.130 -p 6379 -a 12345678
4)通过Pipeline将order.sql文件数据导入到Redis中。
执行命令:
mysql -uroot -proot hankin --default-character-set=utf8 --skip-column-names --raw < order.sql | redis-cli -h 192.168.30.130 -p 6379 -a 12345678 --pipe

通过上面执行操作已经生成了11条数据,然后在Redis中查询所有数据:命令:keys *
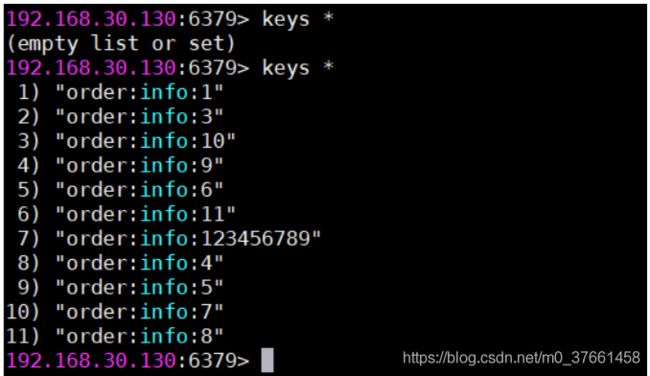
随机查询一条数据:
192.168.30.130:6379> hgetall order:info:123456789
1) "ordertime"
2) "2019-01-01 14:04:05"
3) "ordermoney"
4) "24"
5) "orderstatus"
6) "0"
7) "version"
8) "0"
查看sql文件:cat order.sql
SELECT CONCAT(
'*10\r\n',
'$', LENGTH(redis_cmd), '\r\n', redis_cmd, '\r\n',
'$', LENGTH(redis_key), '\r\n', redis_key, '\r\n',
'$', LENGTH(hkey1),'\r\n',hkey1,'\r\n',`order`
'$', LENGTH(hval1),'\r\n',hval1,'\r\n',
'$', LENGTH(hkey2),'\r\n',hkey2,'\r\n',
'$', LENGTH(hval2),'\r\n',hval2,'\r\n',
'$', LENGTH(hkey3),'\r\n',hkey3,'\r\n',
'$', LENGTH(hval3),'\r\n',hval3,'\r\n',
'$', LENGTH(hkey4),'\r\n',hkey4,'\r\n',
'$', LENGTH(hval4),'\r\n',hval4,'\r'
)
FROM (
SELECT
'HSET' AS redis_cmd,
CONCAT('order:info:',orderid) AS redis_key,
'ordertime' AS hkey1, ordertime AS hval1,
'ordermoney' AS hkey2, ordermoney AS hval2,
'orderstatus' AS hkey3, orderstatus AS hval3,
'version' AS hkey4, `version` AS hval4
FROM `order`
) AS t将对应的sql语句放到数据库中执行结果如下:
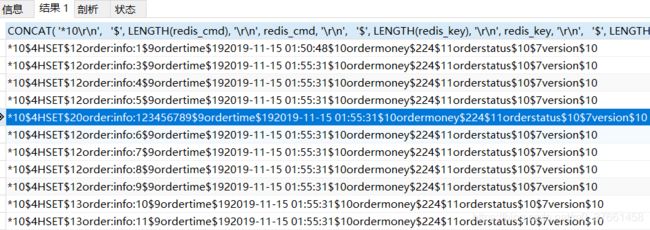
随机查看一条数据如下:
*10
$4
HSET
$12
order:info:1
$9
ordertime
$19
2019-11-15 01:50:48
$10
ordermoney
$2
24
$11
orderstatus
$1
0
$7
version
$1
0结论:
Jedis(Socket) ————RESP协议————Redis(ServerSocket)
三、手写Jedis实战
了解Redis基本命令特性与效果,手写自己的Jedis,完成与Redis服务端的请求与响应;
Redis操作存在的问题:对于某些操作无法提供批操作。
手写jedis代码示例:
public class MyJedis {
public static String set(Socket socket,String key, String value) throws IOException {
StringBuffer str = new StringBuffer();
str.append("*3").append("\r\n");
str.append("$3").append("\r\n");
str.append("SET").append("\r\n");
str.append("$").append(key.getBytes().length).append("\r\n");
str.append(key).append("\r\n");
str.append("$").append(value.getBytes().length).append("\r\n");
str.append(value).append("\r\n");
socket.getOutputStream().write(str.toString().getBytes());
byte[] response = new byte[2048];
socket.getInputStream().read(response);
return new String(response);
}
public static String get(Socket socket,String key) throws IOException {
StringBuffer str = new StringBuffer();
str.append("*2").append("\r\n");
str.append("$3").append("\r\n");
str.append("GET").append("\r\n");
str.append("$").append(key.getBytes().length).append("\r\n");
str.append(key).append("\r\n");
socket.getOutputStream().write(str.toString().getBytes());
byte[] response = new byte[2048];
socket.getInputStream().read(response);
return new String(response);
}
public static void main(String[] args) throws IOException {
Socket socket = new Socket("127.0.0.1",6379);
set(socket,"hankin","helle my jedis");
System.out.println(get(socket,"hankin"));
}
}执行结果:
$14
helle my jedis
1、单个指令批量操作误区
2、PIPELINE操作流程
大多数情况下,我们都会通过请求-相应机制去操作redis。只用这种模式的一般的步骤是,先获得jedis 实例,然后通过jedis的get/put方法与redis交互。由于redis是单线程的,下一次请求必须等待上一次请求执行完成后才能继续执行。然而使用Pipeline模式,客户端可以一次性的发送多个命令,无需等待服务端返回。这样就大大的减少了网络往返时间,提高了系统性能。
1)批量操作时使用如下代码网络开销非常大(1128毫秒)
// 删除10000条数据
public static void delNoStus(String...keys){
Jedis jedis = new Jedis(RedisTools.ip,RedisTools.port);
for(String key:keys){
jedis.del(key);
}
jedis.close();
}每一次请求都会建立网络连接, 非常耗时, 特别是跨机房的场景下
2)使用PIPELINE可以解决网络开销的问题,代码如下:
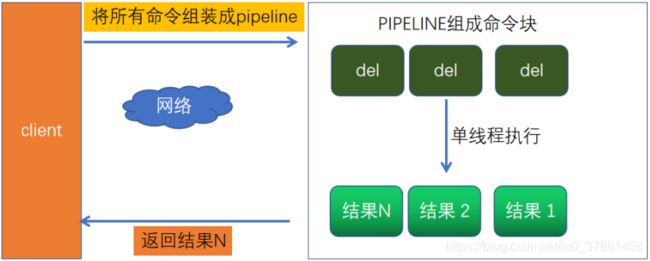
自定义pipeline类代码实现:
public class TestPipeline {
private Socket socket;
public TestPipeline(Socket socket) {
this.socket = socket;
}
/**
* 传入数组KEY,批量删除 String[]{"key:0","key:1","key:2","key:3","key:4"})
*/
public void mdel(String... keys) throws Exception {
StringBuffer str = new StringBuffer();
for(String key:keys){
str.append("*2").append("\r\n");
str.append("$3").append("\r\n");
str.append("del").append("\r\n");
str.append("$").append(key.getBytes().length).append("\r\n");
str.append(key).append("\r\n");
}
socket.getOutputStream().write(str.toString().getBytes());
}
/**
* 获取从Redis服务端响应的结果
*/
public String resp() throws Exception {
byte[] b = new byte[2048];
socket.getInputStream().read(b );
return new String(b);
}
}3、性能对比实战
测试代码:
public class ServiceTest {
public static void main(String[] args) {
RedisTools.initRedisData();
long t = System.currentTimeMillis();
// 1128毫秒
// delNoStus(RedisTools.keys);
// 32 毫秒
delNoPipe(RedisTools.keys);
System.out.println(System.currentTimeMillis()-t);
}
// 删除10000条数据
public static void delNoStus(String...keys){
Jedis jedis = new Jedis(RedisTools.ip,RedisTools.port);
for(String key:keys){
jedis.del(key);
}
jedis.close();
}
// 使用Pipeline方式删除10000条数据(批量操作)
public static void delNoPipe(String...keys){
Jedis jedis = new Jedis(RedisTools.ip,RedisTools.port);
Pipeline pipelined = jedis.pipelined();
for(String key:keys){
pipelined.del(key);//redis?
}
pipelined.sync();//
jedis.close();
}
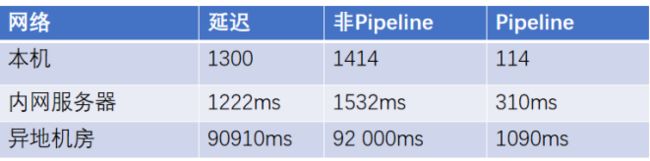
}本地非Pipeline删除10000条数据耗时1128毫秒,使用Pipeline耗时 32 毫秒。
结论:
4、redis事务
刚大家知道,pipeline 是多条命令的组合,为了保证它的原子性,redis 提供了简单的事务,什么是事务?事务是指一组动作的执行,这一组动作要么成功,要么失败。
redis的简单事务,将一组需要一起执行的命令放到multi和exec两个命令之间,其中multi代表事务开始,exec代表事务结束。
注:在 multi 前 set user:age 4 //请提前初始化该值
1)事务操作
192.168.30.156:6379> multi
OK
192.168.30.156:6379> sadd user:name hankin
QUEUED
192.168.30.156:6379> sadd user:age 30
QUEUED
192.168.30.156:6379> get user:age
QUEUED
192.168.30.156:6379> exec
1) (integer) 1
2) (integer) 1
3) (error) WRONGTYPE Operation against a key holding the wrong kind of value
192.168.30.156:6379> smembers user:age
1) "30"
2)中断事务(数据保存失败,查询为nil)
192.168.30.156:6379> multi
OK
192.168.30.156:6379> sadd key1 1001
QUEUED
192.168.30.156:6379> discard
OK
192.168.30.156:6379> exec
(error) ERR EXEC without MULTI
192.168.30.156:6379> get key1
(nil)
3)命令错误,语法不正确,导致事务不能正常结束
192.168.30.156:6379> multi
OK
192.168.30.156:6379> set aa 123
QUEUED
192.168.30.156:6379> sett bb 456
(error) ERR unknown command 'sett'
192.168.30.156:6379> exec
(error) EXECABORT Transaction discarded because of previous errors.
192.168.30.156:6379> get aa
(nil)
4)运行错误,语法正确,但类型错误,事务可以正常结束
192.168.30.156:6379> multi
OK
192.168.30.156:6379> set t 1
QUEUED
192.168.30.156:6379> sadd t 1
QUEUED
192.168.30.156:6379> set t 2
QUEUED
192.168.30.156:6379> exec
1) OK
2) (error) WRONGTYPE Operation against a key holding the wrong kind of value
3) OK
192.168.30.156:6379> get t
"2"
结论:可以看到 redis 不支持回滚功能
5)Watch让事务失效,操作命令

总结:redis提供了简单的事务,不支持事务回滚
四、redis发布与订阅
redis提供了“发布、订阅”模式的消息机制,其中消息订阅者与发布者不直接通信,发布者向指定的频道(channel)发布消息,订阅该频道的每个客户端都可以接收到消息。
1、redis发布与订阅命令
redis主要提供发布消息、订阅频道、取消订阅以及按照模式订阅和取消订阅
1)发布消息:
publish channel:test "hello world" // 此时没有订阅返回0
2)订阅消息:subscribe channel:test
此时另一个客户端发布一个消息:publish channel:test "hankin test"
当前订阅者客户端会收到如下消息:
192.168.30.156:6379> subscribe channel:test
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "channel:test"
3) (integer) 1
和很多专业的消息队列(kafka rabbitmq)相比redis的发布订阅显得很lower,比如无法实现消息规程和回溯,但就是简单,如果能满足应用场景,用这个也可以。
3)查看订阅数:
pubsub numsub channel:test // 频道 channel:test 的订阅数
192.168.30.156:6379> pubsub numsub channel:test
1) "channel:test"
2) (integer) 0
4)取消订阅:unsubscribe channel:test
客户端可以通过unsubscribe命令取消对指定频道的订阅,取消后不会再收到该频道的消息。
192.168.30.156:6379> unsubscribe channel:test
1) "unsubscribe"
2) "channel:test"
3) (integer) 0
5)按模式订阅和取消订阅:psubscribe ch*
psubscribe ch* //订阅以 ch 开头的所有频道
192.168.30.156:6379> psubscribe ch*
Reading messages... (press Ctrl-C to quit)
1) "psubscribe"
2) "ch*"
3) (integer) 1
punsubscribe ch* //取消以 ch 开头的所有频道
192.168.30.156:6379> punsubscribe ch*
1) "punsubscribe"
2) "ch*"
3) (integer) 0
2、redis发布与订阅-应用场景
1)今日头条订阅号、微信订阅公众号、新浪微博关注、邮件订阅系统
2)即使通信系统
3)群聊部落系统(微信群)
测试实践:微信班级群class:20191114
① 学生C订阅一个主题叫:class:20191114
192.168.30.156:6379> subscribe class:20191114
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "class:20191114"
3) (integer) 1
② 学生A针对class:20191114主体发送消息,那么所有订阅该主题的用户都能够接收到该数据。
192.168.30.156:6379> publish class:20191114 "hello world! I am A"
③ 学生B针对class:20191114主体发送消息,那么所有订阅该主题的用户都能够接收到该数据。
192.168.30.156:6379> publish class:20191114 "hello world! I am BB"
展示学生C接受到的A\B同学发送过来的消息信息:
192.168.30.156:6379> subscribe class:20191114
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "class:20191114"
3) (integer) 1
1) "message"
2) "class:20191114"
3) "hello world! I am A"
1) "message"
2) "class:20191114"
3) "hello world! I am BB"
五、键的迁移
1、键的迁移-move
把部分数据迁移到另一台redis服务器
move key db //reids有16个库, 编号为0-15
set name hankin1
move name 5 //迁移到第6个库
select 5 //数据库切换到第6个库,get name可以取到hankin1
这种模式不建议在生产环境使用,在同一个reids里可以玩
2、键的迁移—dump
restore key ttl value //实现不同redis实例的键迁移,ttl=0代表没有过期时间
1)在A服务器上 192.168.30.130
set name hankin
dump name //得到"\x00\x05james\b\x001\x82;f\"DhJ"
2)在B服务器上:192.168.30.156
restore name 0 "\x00\x05james\b\x001\x82;f\"DhJ" //0代表没有过期时间
get name //返回hankin
3、键的迁移—migrate
migrate用于在Redis实例间进行数据迁移,实际上migrate命令是将dump、restore、del三个命令进行组合,从而简化了操作流程。migrate命令具有原子性,从Redis 3.0.6版本后已经支持迁移多个键的功能。
migrate命令的数据传输直接在源Redis和目标Redis上完成,目标Redis完成restore后会发送OK给源Redis。

比如:把130上的name键值迁移到156上的redis
192.168.30.156:6379> migrate 192.168.30.130 6379 name 0 1000 copy
4、Key的遍历
4.1、键全量遍历
mset country china city bj name hankin //设置3个字符串键值对
keys * //返回所有的键, *匹配任意字符多个字符
keys *y //以结尾的键,
keys n*e //以n开头以e结尾,返回name
keys n?me // ?问号代表只匹配一个字符 返回name,全局匹配
keys n?m* //返回name
keys [h,l]* //返回以h l开头的所有键,keys [h]hankin 全量匹配hankin
考虑到是单线程, 在生产环境不建议使用,如果键多可能会阻塞,如果键少可以使用。
4.2、渐进式遍历
1)初始化数据:
mset n1 1 n2 2 n3 3 n4 4 n5 5 n6 6 n7 7 n8 8 n9 9 n10 10 n11 11 n12 12 n13 13
2)遍历匹配:
scan 0 match n* count 5 //匹配以n开头的键,最大是取5条。
第一次scan 0开始。
第二次从游标4096开始取20个以n开头的键,相当于一页一页的取当最后返回0时,键被取完,但count有时不准。
192.168.30.130:6379> scan 0 match n* count 5
1) "18"
2) 1) "n12"
2) "n11"
192.168.30.130:6379>
4.3、两种遍历对比
scan相比keys具备有以下特点:
1)通过游标分布进行的,不会阻塞线程。
2)提供limit参数,可以控制每次返回结果的最大条数,limit不准,返回的结果可多可少。
3)同keys 一样,Scan也提供模式匹配功能。
4)服务器不需要为游标保存状态,游标的唯一状态就是scan返回给客户端的游标整数。
5)scan返回的结果可能会有重复,需要客户端去重复。
6)scan遍历的过程中如果有数据修改,改动后的数据能不能遍历到是不确定的。
7)单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零。
4.4、其它数据结构的遍历
除scan字符串外,还有以下:
- SCAN 命令用于迭代当前数据库中的数据库键。
- SSCAN 命令用于迭代集合键中的元素。
- HSCAN 命令用于迭代哈希键中的键值对。
- ZSCAN 命令用于迭代有序集合中的元素(包括元素成员和元素分值)。
- 用法和scan一样。