机器学习实验 | 用tensorflow简单实现 cifar-10 数据集构建卷积神经网络
cifar-10构建卷积神经网络
- 说明
- 代码
- 实验结果
说明
以下的代码包含:
1. 数据导入
2. 把数据label标记成one-hot
3. 定义神经网络
4. 定义损失
5. 定义优化器
6. 保存模型
7. 保存日志
8. 测试代码
运行环境:win10 + python 3.6 + CUDA 10.0 + Cudnn 7.5.1 + tensorflow 1.13.1
上面这个版本我在网上查到这是最稳定的,之前笔者的环境是CUDA10.1 + Cudnn7.6.5 这个会报错,具体报错没有及时截图,运行下面的代码也遇到过很多bug。
如果有读者运行下面代码遇到了某些bug,可以留言给我,如果我遇到过,我会及时给你回复如何修改bug噢!
PS:由于是在笔记本上跑,害怕跑崩了,就只是用了部分数据集进行训练,没有使用所有的训练集训练。
提供cifar-10数据集下载链接:http://www.cs.toronto.edu/~kriz/cifar.html

一定要注意看在什么环境下运行,就选择下载什么环境的数据集。笔者之前下载了最后一类,但是运行并不成功!
cifar-10 参考代码:https://tensorflow.googlesource.com/tensorflow/+/master/tensorflow/models/image/cifar10/
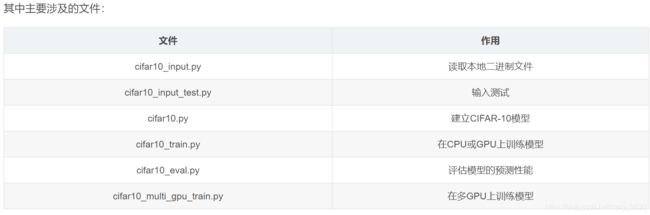
具体参考Tensorflow中文社区:http://tensorfly.cn/tfdoc/tutorials/deep_cnn.html
代码
Python 代码如下:
#coding:utf-8
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
import cifar10, cifar10_input
import pickle
import numpy as np
import matplotlib.pyplot as plt
import time
batch_size = 50
max_step = 500
LR = 0.0001
# prepare data
def unpickle(file):
with open(file, 'rb') as f:
dict = pickle.load(f, encoding = 'latin1')
return dict
def onehot(labels):
# one-hot encoding
n_sample = len(labels)
n_class = max(labels) + 1
onehot_labels = np.zeros((n_sample, n_class))
onehot_labels[np.arange(n_sample), labels] = 1
return onehot_labels
# labels = []
# X_train = []
# for i in range(1, 6):
# files = "D:/Courses/machine learning/test/test06/cifar-10-python/cifar-10-batches-py/data_batch_" + str(i)
# # print(files)
# data = unpickle(files)
# labels.append(data['labels'])
# X_train.append(data['data'])
# print(X_train)
# input train data
data1 = unpickle('D:/Courses/machine learning/test/test06/cifar-10-python/cifar-10-batches-py/data_batch_1')
data2 = unpickle('D:/Courses/machine learning/test/test06/cifar-10-python/cifar-10-batches-py/data_batch_2')
# data3 = unpickle('D:/Courses/machine learning/test/test06/cifar-10-python/cifar-10-batches-py/data_batch_3')
# data4 = unpickle('D:/Courses/machine learning/test/test06/cifar-10-python/cifar-10-batches-py/data_batch_4')
# data5 = unpickle('D:/Courses/machine learning/test/test06/cifar-10-python/cifar-10-batches-py/data_batch_5')
# X_train = np.concatenate((data1['data'], data2['data'], data3['data'], data4['data'], data5['data']), axis=0)
# labels = np.concatenate((data1['labels'], data2['labels'], data3['labels'], data4['labels'], data5['labels']), axis=0)
X_train = np.concatenate((data1['data'], data2['data']), axis=0)
labels = np.concatenate((data1['labels'], data2['labels']), axis=0)
y_train = onehot(labels)
# input test data
test = unpickle('D:/Courses/machine learning/test/test06/cifar-10-python/cifar-10-batches-py/test_batch')
X_test = test['data'][:5000, :]
y_test = onehot(test['labels'])[:5000, :]
# define network
tf_X = tf.compat.v1.placeholder(tf.float32, shape = [None, 3072])
tf_y = tf.compat.v1.placeholder(tf.float32, shape = [None, 10])
keep_prob = tf.compat.v1.placeholder(tf.float32) # 解决过拟合问题
# build network
W_conv = {
'conv1':tf.Variable(tf.random.truncated_normal([3, 3, 3, 32], stddev = 0.0001)),
'conv2':tf.Variable(tf.random.truncated_normal([3, 3, 32, 64], stddev = 0.01)),
'fc1':tf.Variable(tf.random.truncated_normal([8*8*64, 384], stddev = 0.1)),
'fc2':tf.Variable(tf.random.truncated_normal([384, 192], stddev = 0.1)),
'fc3':tf.Variable(tf.random.truncated_normal([192, 10], stddev = 0.1))
}
b_conv = {
'conv1':tf.Variable(tf.constant(0.0, dtype = tf.float32, shape = [32])),
'conv2':tf.Variable(tf.constant(0.1, dtype = tf.float32, shape = [64])),
'fc1':tf.Variable(tf.constant(0.1, dtype = tf.float32, shape = [384])),
'fc2' : tf.Variable(tf.constant(0.1, dtype = tf.float32, shape=[192])),
'fc3' : tf.Variable(tf.constant(0.0, dtype = tf.float32, shape=[10]))
}
x_image = tf.reshape(tf_X, [-1, 32, 32, 3])
# conv layer 1
conv1 = tf.nn.conv2d(x_image, W_conv['conv1'], strides=[1, 1, 1, 1], padding='SAME')
conv1 = tf.nn.bias_add(conv1, b_conv['conv1'])
conv1 = tf.nn.relu(conv1)
# pool layer 1
poo11 = tf.nn.avg_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME')
# LRN layer,Local Response Normalization
norm1 = tf.nn.lrn(poo11, 4, bias=1.0, alpha=0.001/9.0, beta=0.75)
# conv layer 2
conv2 = tf.nn.conv2d(norm1, W_conv['conv2'], strides=[1, 1, 1, 1], padding='SAME')
conv2 = tf.nn.bias_add(conv2, b_conv['conv2'])
conv2 = tf.nn.relu(conv2)
# LRN layer
norm2 = tf.nn.lrn(conv2, 4, bias=1.0, alpha=0.001/9.0, beta=0.75)
# pool layer 2
pool2 = tf.nn.avg_pool(norm2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
reshape = tf.reshape(pool2, [-1, 8*8*64])
# fc 1
fc1 = tf.add(tf.matmul(reshape, W_conv['fc1']), b_conv['fc1'])
fc1 = tf.nn.relu(fc1)
# fc 2
fc2 = tf.add(tf.matmul(fc1, W_conv['fc2']), b_conv['fc2'])
fc2 = tf.nn.relu(fc2)
# fc 3
fc3 = tf.nn.softmax(tf.add(tf.matmul(fc2, W_conv['fc3']), b_conv['fc3']))
# define loss
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=fc3, labels=tf_y))
tf.compat.v1.summary.scalar("loss", loss)
# define optimizer
optimizer = tf.compat.v1.train.GradientDescentOptimizer(learning_rate=LR).minimize(loss)
# define evaluate
correct_pred = tf.equal(tf.argmax(fc3, 1), tf.argmax(tf_y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
tf.compat.v1.summary.scalar("accuracy", accuracy)
init = tf.global_variables_initializer()
# saver
saver = tf.train.Saver()
isTrain = True
train_steps = 100
checkpoint_steps = 20
checkpoint_path = "D:/Courses/machine learning/test/test06/model/model.ckpt"
with tf.Session() as sess:
sess.run(init)
c = []
total_batch = int(X_train.shape[0] / batch_size)
# print(total_batch)
start_time = time.time()
mysummary = tf.summary.merge_all()
f_summary = tf.summary.FileWriter(logdir="./log", graph=sess.graph)
if isTrain:
# sess.run(init)
for i in range(train_steps):
for batch in range(total_batch):
batch_x = X_train[batch*batch_size : (batch+1)*batch_size, :]
# print(X_train.shape)
# print(batch_x.shape)
# print(y_train.shape)
# print(batch)
# print(batch_size)
batch_y = y_train[batch*batch_size : (batch+1)*batch_size, :]
sess.run(optimizer, feed_dict={tf_X: batch_x, tf_y : batch_y})
tmp_summary = sess.run(mysummary, feed_dict={tf_X: batch_x, tf_y : batch_y})
f_summary.add_summary(summary=tmp_summary, global_step=i+1)
if (i + 1) % checkpoint_steps == 0:
save_path = saver.save(sess, checkpoint_path, global_step=i+1)
# print(save_path)
else:
pass
acc = sess.run(accuracy, feed_dict={tf_X: batch_x, tf_y: batch_y})
_, loss_ = sess.run([optimizer, loss], {tf_X: batch_x, tf_y: batch_y})
# print("Train accuracy:", acc)
print('Step:', i, '| train loss: %.4f' % loss_, '| test accuracy: %.2f' % acc)
c.append(acc)
end_time = time.time()
print('time:', (end_time - start_time))
start_time = end_time
print( "--------------%d " %i, "onpech is finished------------")
else:
sess.run(init)
ckpt = tf.train.get_checkpoint_state(checkpoint_path)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
else:
pass
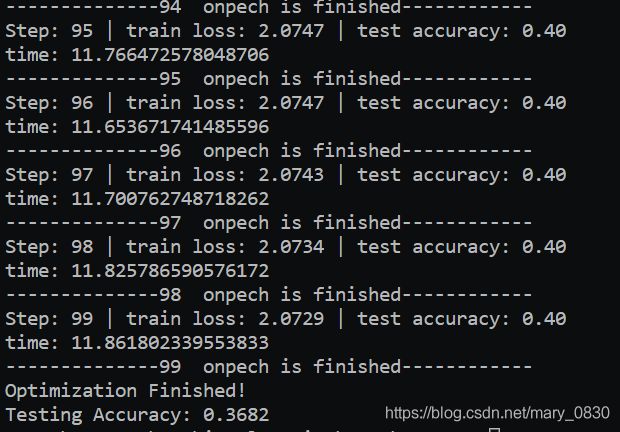
print("Optimization Finished!")
# TEST
test_acc = sess.run(accuracy, feed_dict={tf_X : X_test, tf_y : y_test})
print("Testing Accuracy:", test_acc)
plt.plot(c)
plt.xlabel('Iter')
plt.ylabel('Cost')
plt.title('lr=%f, ti=%d, bs=%d, acc=%f' % (LR, train_steps,batch_size, test_acc))
plt.tight_layout()
plt.savefig('cnn-tf-cifar10-%s.png' % test_acc, dpi=200)
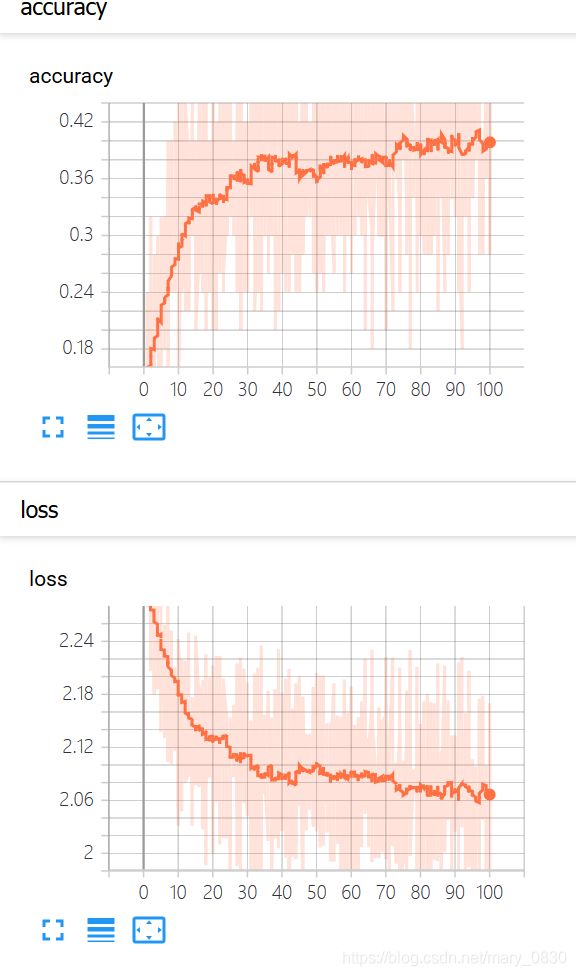
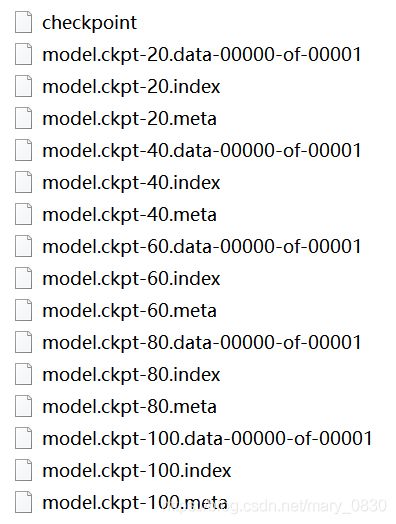
实验结果
(1)日志打印:
![]()
(2)模型保存:
(3)部分实验结果展示:
(4)tensorboard展示:(输入tensorboard logdir “log”)