《统计学习方法,李航》:3、k临近法与kd树
以后文章就不再强调三要素(模型、策略、算法),而是直接上最新鲜的部分。
1)k的选择
2)距离的度量
3)k临近法的实现:kd树
3.1)kd树的构造
3.2)kd树的搜索
1)k的选择
一般初始化为比较小的值,用交叉验证判断哪一个值更好。
2)距离的度量

我们更常用的是欧氏距离,即p=2。
3)k临近法的实现:kd树
k临近法的实现主要考虑如何快速地进行k临近搜索。最简单的注意扫描计算距离并找到最小的k个距离点太耗时,此处给出kd树方法。
k-d树(k-dimensional树的简称),是一种对k维空间(注意,k不是k个邻居的意思)中的实例点进行存储以便对其进行快速搜索的二叉树结构。
假设有6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},数据点位于二维空间内,如图2:
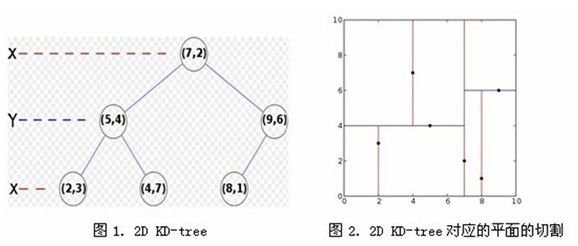
3.1)kd树的构造
a)分别计算k维(上图中只有x,y两维)数据中方差最大的一维(也可以依次分割每一维度),是x轴方向,所以先分割x轴;
b)根据x轴方向的值2,5,9,4,8,7排序选出中值为7,所以以(7,2)为分割点。这样,该节点的分割超平面就是通过(7,2)并垂直于x轴的直线x = 7;
c)确定左子空间(x <= 7的部分)和右子空间(x > 7的部分)进行上面两步递归操作直到空间中只包含一个数据点。最后生成的k-d树如图1。
3.2)kd树的搜索


这里描述最邻近点查找的基本思路。
例一:星号表示要查询的点(2.1,3.1)。
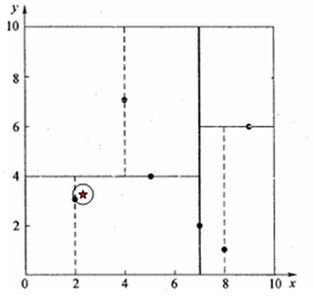
通过二叉搜索,顺着搜索路径很快就能找到最邻近的叶子节点(2,3),首先假设(2,3)为“当前最近邻点”。
最邻近点肯定位于以查询点为圆心且通过叶子节点的圆域内。为了找到真正的最近邻,还需要进行“回溯”操作:算法沿搜索路径反向查找是否有距离查询点更近的数据点。此例中是由点(2,3)回溯到其父节点(5,4),并判断在该父节点的其他子节点空间中是否有距离查询点更近的数据点,发现该圆并不和超平面y = 4交割,因此不用进入(5,4)节点右子空间中去搜索。
再回溯到(7,2),以(2.1,3.1)为圆心,以0.1414为半径的圆更不会与x = 7超平面交割,因此不用进入(7,2)右子空间进行查找。
至此,搜索路径中的节点已经全部回溯完,结束整个搜索,返回最近邻点(2,3),最近距离为0.1414。
例二:星号表示要查询的点(2,4.5)。
通过二叉搜索,顺着搜索路径很快就能找到最邻近的叶子节点(4,7),首先假设(4,7)为当前最近邻点,计算其与目标查找点的距离为3.202。
回溯到(5,4),计算其与查找点之间的距离为3.041,小于3.202,所以“当前最近邻点”变成(5,4)。以目标点(2,4.5)为圆心,以目标点(2,4.5)到“当前最近邻点”(5,4)的距离(即3.041)为半径作圆,如下图左所示。可见该圆和y = 4超平面相交,所以需要进入(5,4)左子空间进行查找,即回溯至(2,3)叶子节点,(2,3)距离(2,4.5)比(5,4)要近,所以“当前最近邻点”更新为(2,3),最近距离更新为1.5。回溯至(7,2),以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,如下图右所示。至此,搜索路径回溯完。返回最近邻点(2,3),最近距离1.5。

参考:http://blog.csdn.net/qll125596718/article/details/8426458