SentiLR:Linguistic Knowledge Enhanced Language Representation for Sentiment Analysis 论文阅读笔记
SentiLR: Linguistic Knowledge Enhanced Language Representation for Sentiment Analysis
SentiLR:用于情感分析的语言知识增强的语言表示
来源:https://arxiv.org/abs/1911.02493 清华团队
Introduction
虽然当前的预训练语言模型已经取得了很好的性能,但是它们的预训练任务(1.masked language model; 2.next sentence prediction )都忽视了语言知识。作者认为语言知识对于一些NLP任务非常重要,特别是情感分析任务。
在情感分析任务中,语言知识例如词性和单词级情感极性经常被用作外部特征。词性通过提高句法分析性能,有助于理解语篇的句法结构。单词级情感极性主要来自情感词典。
语言知识大致反映了单个单词对整个句子的情感的不同影响,有一些充当**“sentiment shifters”**的角色,例如,否定词不断地将情感转变为相反的极性,而程度词会改变文本的情感程度。
然而,句子的情感标签通常是由词语引起的多种情感变化而来的,而对于句子级情感标签和单词级的sentiment shifts之间的复杂关系的建模仍在探索中。
因此,我们的研究目标是充分利用语言知识来获得语言表示,从而建立高级标签(句子级的情感标签)和单词(指sentiment shifters)之间的联系,从而提高情感分析任务的性能。
作者提出一种新型的语言表示模型:“SentiLR”,它引入了单词级的语言知识,包括词性标注和先验情感极性 (来源于SentiWordNet情感词典)。
设计了一个新的预训练任务:label-aware masked language model (LA-MLM)
-
word knowledge recovering given the sentence-level label.
即根据给定的句子级标签来预测被mask的位置上的词、词性、情感极性。
-
sentence-level label prediction with linguistic knowledge enhanced context. 语言知识增强语境下的句子级语言预测。即同时预测句子级标签、masked单词及其它的语言知识(也就是词性、情感极性)。
这两个子任务旨在鼓励模型利用语言知识来建立 high-level 情感标签(也就是句子级的情感标签) 与 low-level sentiment shifts (改变句子情感极性的一些词,如否定词、程度词) 之前的联系。
Model
Task Definition and Model Overview

该模型首先从SentiWordNet中获取每个词对应词性标记的词级情感极性。
在预训练过程中,基于 label-aware masked language model 和 next sentence prediction 这两个任务对模型进行训练。
经过预训练之后,SentiLR可以对不同的情感分析任务(如句子级/方面级的情感分类任务)进行微调。

Linguistic Knowledge Acquisition
这个模块是通过词性标签从SentiWordNet词典中获取每个词的情感极性(得分)。
输入是 X = ( ( x 1 , p o s 1 ) , ( x 2 , p o s 2 ) , . . . , ( x n , p o s n ) ) X=((x_1,pos_1),(x_2,pos_2),...,(x_n,pos_n)) X=((x1,pos1),(x2,pos2),...,(xn,posn)) ,其中 x i x_i xi 是word, p o s i pos_i posi 是词性标签。
假设对于元组 ( x i , p o s i ) (x_i,pos_i) (xi,posi) 我们可以找到m种不同的意思,用 ( S N i ( j ) , P o s S c o r e i ( j ) , N e g S c o r e i ( j ) ) (SN_i^{(j)},PosScore_i^{(j)},NegScore_i^{(j)}) (SNi(j),PosScorei(j),NegScorei(j)) , 1 ⩽ j ⩽ m 1 \leqslant j \leqslant m 1⩽j⩽m .
其中, S N SN SN 是不同意思的索引, P o s S c o r e PosScore PosScore 和 N e g S c o r e NegScore NegScore 分别是word的情感正向得分和负向得分。
由于我们不能准确的去匹配每个词在sequence中的意思,所以我们计算每个词的情感score根据求和平均的方法:
s c o r e ( x i , p o s i ) = ∑ j = 1 m 1 S N i ( j ) ⋅ ( P o s S c o r e i ( j ) − N e g S c o r e i ( j ) ) score_{(x_i,pos_i)}=\sum_{j=1}^m \frac{1}{SN_i^{(j)}} \cdot (PosScore_i^{(j)}-NegScore_i^{(j)}) score(xi,posi)=j=1∑mSNi(j)1⋅(PosScorei(j)−NegScorei(j))
l a b e l ( x i , p o s i ) = { P o s i t i v e s c o r e ( x i , p o s i ) > 0 N e g a t i v e s c o r e ( x i , p o s i ) < 0 N e u t r a l s c o r e ( x i , p o s i ) = 0 label_{(x_i,pos_i)}=\left\{\begin{aligned}Positive & score_{(x_i,pos_i)} > 0 \\Negative & score_{(x_i,pos_i)} < 0 \\Neutral & score_{(x_i,pos_i)} = 0\end{aligned}\right. label(xi,posi)=⎩⎪⎨⎪⎧PositiveNegativeNeutralscore(xi,posi)>0score(xi,posi)<0score(xi,posi)=0
Pre-training Tasks
两个子任务:
- Label-aware masked language model (LA-MLM)
- Next sentence prediction (NSP)
NSP任务和BERT论文中是一致的。
LA-MLM任务是利用语言学知识去获取句子级情感标签与每个单词以及上下文依赖性之间的隐含关系
LA-MLM包含两个独立的子任务:
- Sub-task#1 of label-aware masked language model:

Token Embedding 包含了original word embedding,part-of-speech embedding,word-level sentiment polarity embedding。
给定句子级的情感标签(如negative),我们的模型去预测word(good),part-of-speech tag (JJ) 和 word-level sentiment polarity (positive)。
- Sub-task#2 of label-aware masked language model:
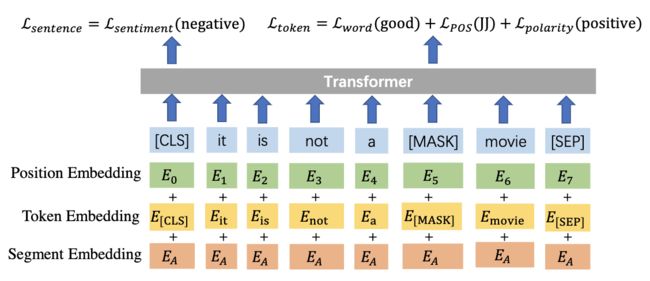
Sub-task#2的任务是去同时预测句子级的情感标签(negative)和被mask掉的位置上的词信息(word: good, part-of-speech tag: JJ, word-level senti-ment polarity: positive)。
由于两个子任务是独立的,我们经验性的给它们分配的预训练数据比例为4:1。
与BERT不同的是,对于masking probability,我们从设置为30%。只对正负情感词进行mask,提升masking probability的原因是情感词的多少影响整个句子的情感转移,通俗的说,就是被masking的情感词如果比较少的话,可能对于句子的情感并没有多大影响。
Fine-tuning Setting

( x 1 , x 2 , . . . , x n ) (x_1,x_2,...,x_n) (x1,x2,...,xn) 表示要进行分类的 text sequence, ( a 1 , a 2 , . . . , a l ) (a_1,a_2,...,a_l) (a1,a2,...,al) 表示 aspect term/aspect category sequence。
Experiment
Sentence-level Sentiment Classification


效果明显比BERT要好,跟XLNet不相上下吧。
Aspect-level Sentiment Classification


General Language Understanding Tasks (GLUE)

Ablation Study
Ablation study 即模型简化测试
顾名思义,就是去掉模型中的部分模块,然后看模型的性能是否发生变化。
