Transfer Learning
Pokemon Dataset
通过网络上收集宝可梦的图片,制作图像分类数据集。我收集了5种宝可梦,分别是皮卡丘,超梦,杰尼龟,小火龙,妙蛙种子
数据集链接:https://pan.baidu.com/s/1Kept7FF88lb8TqPZMD_Yxw提取码:1sdd
一共有1168张宝可梦的图片,其中皮卡丘234张,超梦239张,杰尼龟223张,小火龙238张,妙蛙种子234张
每个目录由神奇宝贝名字命名,对应目录下是该神奇宝贝的图片,图片的格式有jpg,png,jpeg三种
数据集的划分如下(训练集60%,验证集20%,测试集20%)。这个比例不是针对每一类提取,而是针对总体的1168张

Load Data
在PyTorch中定义数据集主要涉及到两个主要的类:Dataset和DataLoder
DataSet类
DataSet类是PyTorch中所有数据集加载类中都应该继承的父类,它的两个私有成员函数__len__()和__getitem__()必须被重载,否则将触发错误提示
其中__len__()应该返回数据集的样本数量,而__getitem__()实现通过索引返回样本数据的功能
首先看一个自定义Dataset的例子
class NumbersDataset(Dataset):
def __init__(self, training=True):
if training:
self.samples = list(range(1, 1001))
else:
self.samples = list(range(1001, 1501))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
return self.samples[idx]
然后需要对图片做Preprocessing
- Image Resize:224*224 for ResNet18
- Data Argumentation:Rotate & Crop
- Normalize:Mean & std
- ToTensor
首先我们在__init__()函数里将name->label,这里的name就是文件夹的名字,然后拆分数据集,按照6:2:2的比例
class Pokemon(Dataset):
def __init__(self, root, resize, model):
super(Pokemon, self).__init__()
self.root = root
self.resize = resize
self.name2label = {} # 将文件夹的名字映射为label(数字)
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root, name)):
continue
self.name2label[name] = len(self.name2label.keys())
# image, label
self.images, self.labels = self.load_csv('images.csv')
if model == 'train': # 60%
self.images = self.images[:int(0.6*len(self.images))]
self.labels = self.labels[:int(0.6*len(self.labels))]
elif model == 'val': # 20%
self.images = self.images[int(0.6*len(self.images)):int(0.8*len(self.images))]
self.labels = self.labels[int(0.6*len(self.labels)):int(0.8*len(self.labels))]
else: # 20%
self.images = self.images[int(0.8*len(self.images)):]
self.labels = self.labels[int(0.8*len(self.labels)):]
其中load_csv()函数的作用是将所有的图片名(名字里包含完整的路径)以及label都存到csv文件里,例如,有一个图片的路径是pokemon\\bulbasaur\\00000000.png,对应的label是0,那么csv就会写入一行pokemon\\bulbasaur\\00000000.png, 0,总共写入了1167行(有一张图片既不是png,也不是jpg和jpeg,找不到,算了)。load_csv()函数具体如下所示
def load_csv(self, filename):
if not os.path.exists(os.path.join(self.root, filename)):
images = []
for name in self.name2label.keys():
images += glob.glob(os.path.join(self.root, name, '*.png'))
images += glob.glob(os.path.join(self.root, name, '*.jpg'))
images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
random.shuffle(images)
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img in images: # pokemon\\bulbasaur\\00000000.png
name = img.split(os.sep)[-2] # bulbasaur
label = self.name2label[name]
# pokemon\\bulbasaur\\00000000.png 0
writer.writerow([img, label])
print('writen into csv file:', filename)
# read csv file
images, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
image, label = row
label = int(label)
images.append(image)
labels.append(label)
assert len(images) == len(labels)
return images, labels
然后是__len__()函数的代码
def __len__(self):
return len(self.images)
最后是__getitem__()函数的代码,这个比较复杂,因为我们现在只有图片的string path(字符串形式的路径),要先转成三通道的image data,这个利用PIL库中的Image.open(path).convert('RGB')函数可以完成。图片读取出来以后,要经过一系列的transforms,具体代码如下
def __getitem__(self, idx):
# idx [0~len(images)]
# self.images, self.labels
# pokemon\\bulbasaur\\00000000.png 0
img, label = self.images[idx], self.labels[idx]
tf = transforms.Compose([
lambda x:Image.open(x).convert('RGB'), # string path => image data
transforms.Resize((int(self.resize*1.25), int(self.resize*1.25))),
transforms.RandomRotation(15),
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
img = tf(img)
label = torch.tensor(label)
return img, label
Normalize的参数是PyTorch推荐的,直接写上就可以了
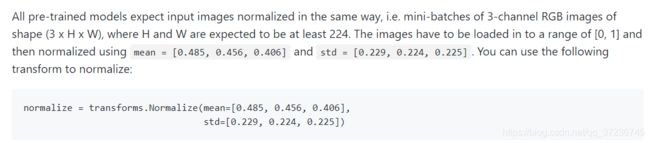
DataLoader类
Dataset类是读入数据集并对读入的数据进行了索引,但是光有这个功能是不够的,在实际加载数据集的过程中,我们的数据量往往都很大,因此还需要以下几个功能:
- 每次读入一些批次:batch_size
- 可以对数据进行随机读取,打乱数据的顺序(shuffling)
- 可以并行加载数据集(利用多核处理器加快载入数据的效率)
为此,就需要DataLoader类了,它里面常用的参数有:
- batch_size:每个batch的大小
- shuffle:是否进行shuffle操作
- num_works:加载数据的时候使用几个进程
DataLoader这个类并不需要我们自己设计代码,只需要利用它读取我们设计好的Dataset的子类即可
db = Pokemon('pokemon', 224, 'train')
lodder = DataLoader(db, batch_size=32, shuffle=True, num_workers=4)
完整代码如下:
import torch
import os, glob
import random, csv
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
class Pokemon(Dataset):
def __init__(self, root, resize, model):
super(Pokemon, self).__init__()
self.root = root
self.resize = resize
self.name2label = {} # 将文件夹的名字映射为label(数字)
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root, name)):
continue
self.name2label[name] = len(self.name2label.keys())
# image, label
self.images, self.labels = self.load_csv('images.csv')
if model == 'train': # 60%
self.images = self.images[:int(0.6*len(self.images))]
self.labels = self.labels[:int(0.6*len(self.labels))]
elif model == 'val': # 20%
self.images = self.images[int(0.6*len(self.images)):int(0.8*len(self.images))]
self.labels = self.labels[int(0.6*len(self.labels)):int(0.8*len(self.labels))]
else: # 20%
self.images = self.images[int(0.8*len(self.images)):]
self.labels = self.labels[int(0.8*len(self.labels)):]
def load_csv(self, filename):
if not os.path.exists(os.path.join(self.root, filename)):
images = []
for name in self.name2label.keys():
images += glob.glob(os.path.join(self.root, name, '*.png'))
images += glob.glob(os.path.join(self.root, name, '*.jpg'))
images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
random.shuffle(images)
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img in images: # pokemon\\bulbasaur\\00000000.png
name = img.split(os.sep)[-2] # bulbasaur
label = self.name2label[name]
# pokemon\\bulbasaur\\00000000.png 0
writer.writerow([img, label])
print('writen into csv file:', filename)
# read csv file
images, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
image, label = row
label = int(label)
images.append(image)
labels.append(label)
assert len(images) == len(labels)
return images, labels
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
# idx [0~len(images)]
# self.images, self.labels
# pokemon\\bulbasaur\\00000000.png 0
img, label = self.images[idx], self.labels[idx]
tf = transforms.Compose([
lambda x:Image.open(x).convert('RGB'), # string path => image data
transforms.Resize((int(self.resize*1.25), int(self.resize*1.25))),
transforms.RandomRotation(15),
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
img = tf(img)
label = torch.tensor(label)
return img, label
db = Pokemon('pokemon', 224, 'train')
lodder = DataLoader(db, batch_size=32, shuffle=True, num_workers=8)
Build Model
用PyTorch搭建ResNet其实在我之前的文章已经讲过了,这里直接拿来用,修改一下里面的参数就行了
import torch
import torch.nn as nn
import torch.nn.functional as F
class ResBlk(nn.Module):
def __init__(self, ch_in, ch_out, stride=1):
super(ResBlk, self).__init__()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out != ch_in:
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out),
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# short cut
out = self.extra(x) + out
out = F.relu(out)
return out
class ResNet18(nn.Module):
def __init__(self, num_class):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(16),
)
# followed 4 blocks
# [b, 16, h, w] => [b, 32, h, w]
self.blk1 = ResBlk(16, 32, stride=3)
# [b, 32, h, w] => [b, 64, h, w]
self.blk2 = ResBlk(32, 64, stride=3)
# [b, 64, h, w] => [b, 128, h, w]
self.blk3 = ResBlk(64, 128, stride=2)
# [b, 128, h, w] => [b, 256, h, w]
self.blk4 = ResBlk(128, 256, stride=2)
self.outlayer = nn.Linear(256*3*3, num_class)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
x = x.view(x.size(0), -1)
x = self.outlayer(x)
return x
Train and Test
训练的时候,严格按照Training和Test的逻辑,就是在训练epoch的过程中,间断的做一次validation,然后看一下当前的validation accuracy是不是最高的,如果是最高的,就把当前的模型参数保存起来。training完以后,加载最好的模型,再做testing。这就是非常严格的训练逻辑。代码如下:
batchsz = 32
lr = 1e-3
epochs = 10
device = torch.device('cuda')
torch.manual_seed(1234)
train_db = Pokemon('pokemon', 224, model='train')
val_db = Pokemon('pokemon', 224, model='val')
test_db = Pokemon('pokemon', 224, model='test')
train_loader = DataLoader(train_db, batch_size=batchsz, shuffle=True, num_workers=2)
val_loader = DataLoader(val_db, batch_size=batchsz, num_workers=2)
test_loader = DataLoader(test_db, batch_size=batchsz, num_workers=2)
def evalute(model, loader):
correct = 0
total = len(loader.dataset)
for x,y in loader:
with torch.no_grad():
logits = model(x)
pred = logits.argmax(dim=1)
correct += torch.eq(pred, y).sum().float().item()
return correct / total
def main():
model = ResNet18(5)
optimizer = optim.Adam(model.parameters(), lr=lr)
criteon = nn.CrossEntropyLoss()
best_acc, best_epoch = 0, 0
for epoch in range(epochs):
for step, (x, y) in enumerate(train_loader):
# x:[b, 3, 224, 224], y:[b]
logits = model(x)
loss = criteon(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 2 == 0:
val_acc = evalute(model, val_loader)
if val_acc > best_acc:
best_epoch = epoch
best_acc = val_acc
torch.save(model.state_dict(), 'best.mdl')
print('best acc:', best_acc, 'best_epoch', best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckt!')
test_acc = evalute(model, test_loader)
print('test_acc:', test_acc)
截至到目前为止,能完整运行的代码如下:
import torch
import os, glob
import warnings
import random, csv
from PIL import Image
from torch import optim, nn
import torch.nn.functional as F
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
warnings.filterwarnings('ignore')
class Pokemon(Dataset):
def __init__(self, root, resize, model):
super(Pokemon, self).__init__()
self.root = root
self.resize = resize
self.name2label = {} # 将文件夹的名字映射为label(数字)
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root, name)):
continue
self.name2label[name] = len(self.name2label.keys())
# image, label
self.images, self.labels = self.load_csv('images.csv')
if model == 'train': # 60%
self.images = self.images[:int(0.6*len(self.images))]
self.labels = self.labels[:int(0.6*len(self.labels))]
elif model == 'val': # 20%
self.images = self.images[int(0.6*len(self.images)):int(0.8*len(self.images))]
self.labels = self.labels[int(0.6*len(self.labels)):int(0.8*len(self.labels))]
else: # 20%
self.images = self.images[int(0.8*len(self.images)):]
self.labels = self.labels[int(0.8*len(self.labels)):]
def load_csv(self, filename):
if not os.path.exists(os.path.join(self.root, filename)):
images = []
for name in self.name2label.keys():
images += glob.glob(os.path.join(self.root, name, '*.png'))
images += glob.glob(os.path.join(self.root, name, '*.jpg'))
images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
random.shuffle(images)
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img in images: # pokemon\\bulbasaur\\00000000.png
name = img.split(os.sep)[-2] # bulbasaur
label = self.name2label[name]
# pokemon\\bulbasaur\\00000000.png 0
writer.writerow([img, label])
print('writen into csv file:', filename)
# read csv file
images, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
image, label = row
label = int(label)
images.append(image)
labels.append(label)
assert len(images) == len(labels)
return images, labels
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
# idx [0~len(images)]
# self.images, self.labels
# pokemon\\bulbasaur\\00000000.png 0
img, label = self.images[idx], self.labels[idx]
tf = transforms.Compose([
lambda x:Image.open(x).convert('RGB'), # string path => image data
transforms.Resize((int(self.resize*1.25), int(self.resize*1.25))),
transforms.RandomRotation(15),
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
img = tf(img)
label = torch.tensor(label)
return img, label
class ResBlk(nn.Module):
def __init__(self, ch_in, ch_out, stride=1):
super(ResBlk, self).__init__()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out != ch_in:
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out),
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# short cut
out = self.extra(x) + out
out = F.relu(out)
return out
class ResNet18(nn.Module):
def __init__(self, num_class):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(16),
)
# followed 4 blocks
# [b, 16, h, w] => [b, 32, h, w]
self.blk1 = ResBlk(16, 32, stride=3)
# [b, 32, h, w] => [b, 64, h, w]
self.blk2 = ResBlk(32, 64, stride=3)
# [b, 64, h, w] => [b, 128, h, w]
self.blk3 = ResBlk(64, 128, stride=2)
# [b, 128, h, w] => [b, 256, h, w]
self.blk4 = ResBlk(128, 256, stride=2)
self.outlayer = nn.Linear(256*3*3, num_class)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
x = x.view(x.size(0), -1)
x = self.outlayer(x)
return x
batchsz = 32
lr = 1e-3
epochs = 10
device = torch.device('cuda')
torch.manual_seed(1234)
train_db = Pokemon('pokemon', 224, model='train')
val_db = Pokemon('pokemon', 224, model='val')
test_db = Pokemon('pokemon', 224, model='test')
train_loader = DataLoader(train_db, batch_size=batchsz, shuffle=True, num_workers=2)
val_loader = DataLoader(val_db, batch_size=batchsz, num_workers=2)
test_loader = DataLoader(test_db, batch_size=batchsz, num_workers=2)
def evalute(model, loader):
correct = 0
total = len(loader.dataset)
for x,y in loader:
with torch.no_grad():
logits = model(x)
pred = logits.argmax(dim=1)
correct += torch.eq(pred, y).sum().float().item()
return correct / total
def main():
model = ResNet18(5)
optimizer = optim.Adam(model.parameters(), lr=lr)
criteon = nn.CrossEntropyLoss()
best_acc, best_epoch = 0, 0
for epoch in range(epochs):
for step, (x, y) in enumerate(train_loader):
# x:[b, 3, 224, 224], y:[b]
logits = model(x)
loss = criteon(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 2 == 0:
val_acc = evalute(model, val_loader)
if val_acc > best_acc:
best_epoch = epoch
best_acc = val_acc
torch.save(model.state_dict(), 'best.mdl')
print('best acc:', best_acc, 'best_epoch', best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckt!')
test_acc = evalute(model, test_loader)
print('test_acc:', test_acc)
if __name__ == '__main__':
main()
Transfer Learning
运行上面的代码,基本上最终test accuracy可以达到0.88左右。如果想要提升的话,就需要使用更多工程上的tricks或者调参
当然还有一种方法,就是迁移学习,我们先看下面这张图,这张图展示的问题在于,当数据很少的情况下(第一张图),模型训练的结果可能会有很多情况(第二张图),当然最终输出就一个结果。然而这个结果可能test accuracy并不高。就比方说我们的pokemon图片,只有1000多张,算是一个比较少的数据集了,但是由于pokemon和ImageNet都是图片,它们可能存在某些共性。那我们能不能用ImageNet的一些train好的模型,拿来帮助我们解决一下特定的图片分类任务,这就是Transfer Learning,也就是在A任务上train好一个分类器,再transfer到B上去
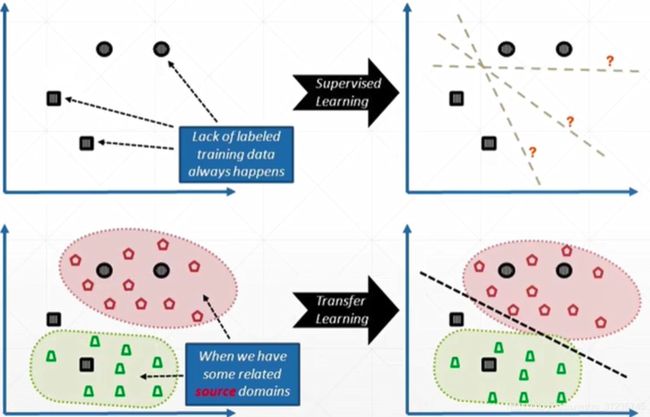
我个人理解Transfer Learning的作用是这样的,我们都知道神经网络初始化参数非常重要,有时候初始化不好,可能就会导致最终效果非常差。现在我们用一个在A任务上已经训练好了的网络,相当于帮你做了一个很好的初始化,你在这个网络的基础上,去做B任务,如果这两个任务比较接近的话,夸张一点说,这个网络的训练可能就只需要微调一下,就能在B任务上显示出非常好的效果
下图展示的是一个真实的Transfer Learning的过程,左边是已经training好的网络,我们利用这个网络的公有部分,吸取它的common knowledge, 然后把最后一层去掉,换成我们需要的
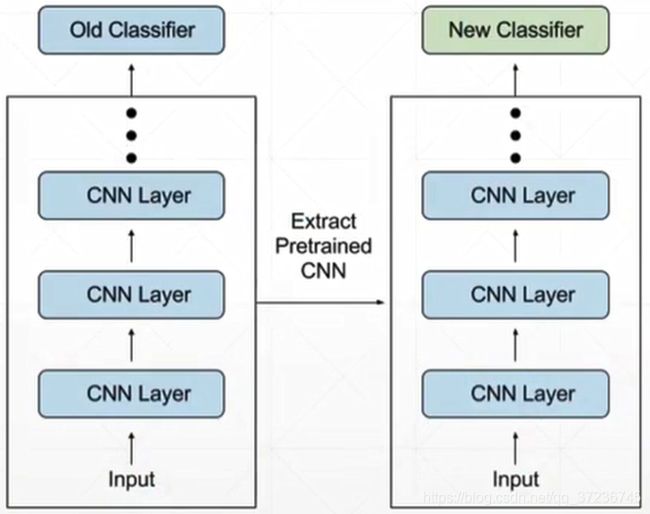
先上核心代码
import torch.nn as nn
from torchvision.models import resnet18
class Flatten(nn.Module):
def __init__(self):
super(Flatten, self).__init__()
def forward(self, x):
shape = torch.prod(torch.tensor(x.shape[1:])).item()
return x.view(-1, shape)
trained_model = resnet18(pretrained=True)
model = nn.Sequential(*list(trained_model.children())[:-1],# [b, 512, 1, 1]
Flatten(), # [b, 512, 1, 1] => [b, 512]
nn.Linear(512, 5) # [b, 512] => [b, 5]
)
PyTorch中有已经训练好的各种规格的resnet,第一次使用需要下载。我们不要resnet18的最后一层,所以要用list(trained_model.children())[:-1]把除了最后一层以外的所有层都取出来,保存在list中,然后用*将其list展开,之后接一个我们自定义的Flatten层,作用是将output打平,打平以后才能送到Linear层去
上面几行代码就实现了Transfer Learning,而且不需要我们自己实现resnet,完整代码如下
import torch
import os, glob
import warnings
import random, csv
from PIL import Image
from torch import optim, nn
import torch.nn.functional as F
from torchvision import transforms
from torchvision.models import resnet18
from torch.utils.data import Dataset, DataLoader
warnings.filterwarnings('ignore')
from matplotlib import pyplot as plt
class Pokemon(Dataset):
def __init__(self, root, resize, model):
super(Pokemon, self).__init__()
self.root = root
self.resize = resize
self.name2label = {} # 将文件夹的名字映射为label(数字)
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root, name)):
continue
self.name2label[name] = len(self.name2label.keys())
# image, label
self.images, self.labels = self.load_csv('images.csv')
if model == 'train': # 60%
self.images = self.images[:int(0.6*len(self.images))]
self.labels = self.labels[:int(0.6*len(self.labels))]
elif model == 'val': # 20%
self.images = self.images[int(0.6*len(self.images)):int(0.8*len(self.images))]
self.labels = self.labels[int(0.6*len(self.labels)):int(0.8*len(self.labels))]
else: # 20%
self.images = self.images[int(0.8*len(self.images)):]
self.labels = self.labels[int(0.8*len(self.labels)):]
def load_csv(self, filename):
if not os.path.exists(os.path.join(self.root, filename)):
images = []
for name in self.name2label.keys():
images += glob.glob(os.path.join(self.root, name, '*.png'))
images += glob.glob(os.path.join(self.root, name, '*.jpg'))
images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
random.shuffle(images)
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img in images: # pokemon\\bulbasaur\\00000000.png
name = img.split(os.sep)[-2] # bulbasaur
label = self.name2label[name]
# pokemon\\bulbasaur\\00000000.png 0
writer.writerow([img, label])
print('writen into csv file:', filename)
# read csv file
images, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
image, label = row
label = int(label)
images.append(image)
labels.append(label)
assert len(images) == len(labels)
return images, labels
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
# idx [0~len(images)]
# self.images, self.labels
# pokemon\\bulbasaur\\00000000.png 0
img, label = self.images[idx], self.labels[idx]
tf = transforms.Compose([
lambda x:Image.open(x).convert('RGB'), # string path => image data
transforms.Resize((int(self.resize*1.25), int(self.resize*1.25))),
transforms.RandomRotation(15),
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
img = tf(img)
label = torch.tensor(label)
return img, label
class Flatten(nn.Module):
def __init__(self):
super(Flatten, self).__init__()
def forward(self, x):
shape = torch.prod(torch.tensor(x.shape[1:])).item()
return x.view(-1, shape)
batchsz = 32
lr = 1e-3
epochs = 10
device = torch.device('cuda')
torch.manual_seed(1234)
train_db = Pokemon('pokemon', 224, model='train')
val_db = Pokemon('pokemon', 224, model='val')
test_db = Pokemon('pokemon', 224, model='test')
train_loader = DataLoader(train_db, batch_size=batchsz, shuffle=True, num_workers=2)
val_loader = DataLoader(val_db, batch_size=batchsz, num_workers=2)
test_loader = DataLoader(test_db, batch_size=batchsz, num_workers=2)
def evalute(model, loader):
correct = 0
total = len(loader.dataset)
for x,y in loader:
with torch.no_grad():
logits = model(x)
pred = logits.argmax(dim=1)
correct += torch.eq(pred, y).sum().float().item()
return correct / total
def main():
trained_model = resnet18(pretrained=True)
model = nn.Sequential(*list(trained_model.children())[:-1],# [b, 512, 1, 1]
Flatten(), # [b, 512, 1, 1] => [b, 512]
nn.Linear(512, 5)
)
optimizer = optim.Adam(model.parameters(), lr=lr)
criteon = nn.CrossEntropyLoss()
best_acc, best_epoch = 0, 0
for epoch in range(epochs):
for step, (x, y) in enumerate(train_loader):
# x:[b, 3, 224, 224], y:[b]
logits = model(x)
loss = criteon(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 2 == 0:
val_acc = evalute(model, val_loader)
if val_acc > best_acc:
best_epoch = epoch
best_acc = val_acc
torch.save(model.state_dict(), 'best.mdl')
print('best acc:', best_acc, 'best_epoch', best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckt!')
test_acc = evalute(model, test_loader)
print('test_acc:', test_acc)
if __name__ == '__main__':
main()
最终test accuracy在0.94左右,比我们自己从0开始训练效果好了很多