【创新实训 第二周】 CTPN 实战 2019.3.31
本周工作进展
CTPN 模型搭建完成,loss 函数设计完成,数据输入格式调整方法完成。(但都还没测试)
本周主要还是熟悉 Keras 的操作方法,不断挑战出现的各种输出与想象结果不一致的情况,并最终被困难所战胜。
2019.4.8 注意,这个模型依旧跑不起来,且回归部分有误
详细工作内容
CTPN 模型搭建

如图,模型由以下部分组成:
- VGG16 网络,取到 conv5 的第三层;
- 在 Conv5 的每个 feature map 像素上取3*3*C的窗口的特征,分别输入双向 LSTM;
- 针对每个 feature map 像素的全连接层;
- 最后输出三个分支,分别是 anchor 的纵坐标与高度,anchor 是否为文字的分数,以及边缘提纯的偏移量。同样,这里的全连接层也是针对每个 feature map 像素。
相对与上周的报告,我有新的理解的部分都用黑体标出。针对每个 feature map 像素的全连接,也就是针对 w*h*c 的矩阵的每个 c 做全连接。所以并不能直接使用 Dense 层,而是用 1*1 的卷积来实现。但 bi-lstm 无法用类似方法处理,需要 reshape 操作。
注:边缘提纯的操作暂时被省略了
# 去掉全连接的 vgg16 网络
def vgg16_no_tail(input_shape=(600, 900, 3)):
# 注意一定要把 include_top 设为 false,
# 否则 input_shape 默认为 224*224,会出错
vgg = keras.applications.VGG16(include_top=False, weights=None,
input_shape=input_shape)
vgg_no_tail = keras.Model(
inputs=vgg.input,
outputs=vgg.get_layer("block5_conv3").output)
return vgg_no_tail
# 生成训练模型
def ctpn_model__():
input_layer = vgg16_no_tail(None)
layer = input_layer.output
# 取临近 feature map 的操作暂时用卷积代替
layer = keras.layers.Convolution2D(
512 * 9, (3, 3),
activation='relu',
padding='same',
name='cnn2rnn')(layer)
# 变形
layer = keras.layers.Reshape((-1, 512 * 9))(layer)
# bi-lstm
layer = keras.layers.Bidirectional(
keras.layers.LSTM(128, return_sequences=True))(layer)
# 恢复形状
layer = keras.layers.Reshape((37, 56, 256), input_shape=(37 * 56, 256))(layer)
# FC
layer = keras.layers.Convolution2D(512, (1, 1), activation='relu')(layer)
# vertical_coordinate, score
vc_layer = keras.layers.Convolution2D(20, (1, 1))(layer)
sc_layer = keras.layers.Convolution2D(20, (1, 1))(layer)
# 将最后的维度两两组合
vc_layer = keras.layers.Reshape((37, 56, 10, 2))(vc_layer)
sc_layer = keras.layers.Reshape((37, 56, 10, 2))(sc_layer)
# score 要一个 sofgmax 输出
sc_layer = keras.layers.Softmax()(sc_layer)
# 两个层合并,方便损失函数的使用
output_layer = keras.layers.Concatenate(4)([vc_layer, sc_layer])
model = keras.Model(inputs=input_layer.input, outputs=output_layer)
model.compile(optimizer=tf.train.AdamOptimizer(0.001),
loss=ctpn_loss,
metrics=['accuracy'])
return model
Loss 函数
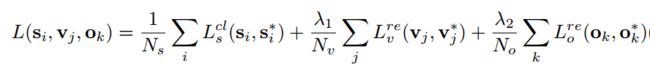
def smooth_l1_loss(y_true, y_pred):
"""Implements Smooth-L1 loss.
y_true and y_pred are typically: [N, 4], but could be any shape.
"""
diff = tf.abs(y_true - y_pred)
less_than_one = tf.cast(tf.less(diff, 1.0), "float32")
loss = (less_than_one * 0.5 * diff ** 2) + (1 - less_than_one) * (diff - 0.5)
return tf.reduce_sum(loss, 4)
def ctpn_loss__(y_true, y_pred):
# 输入数据由于分数和定位是连在一起的,需要且分开来
# 切分出的 shape 都应该长这样 (batch, h, w, 10, 2)
true_vertical_coordinate, true_score = tf.split(y_true, 2, 4)
pred_vertical_coordinate, pred_score = tf.split(y_pred, 2, 4)
# 用到的参数
lambda1 = 1.0
# 用到两个不同的损失函数
loss_vc = smooth_l1_loss
loss_sc = keras.losses.binary_crossentropy
# 先预测分数
sc_loss = loss_sc(true_score, pred_score)
# 忽略背景,由于背景的 positive score 为0,可以直接相乘消除
valid_placeholder = true_score[:, :, :, :, :1]
pred_vertical_coordinate_alter = tf.multiply(valid_placeholder,
pred_vertical_coordinate)
# 处理完预测 vc 后再计算损失
vc_loss = loss_vc(true_vertical_coordinate, pred_vertical_coordinate_alter)
# 总损失函数,和列出的公式有些差别了,不要介意
return sc_loss + vc_loss * lambda1
数据预处理
首先参考这篇,将 box 切成 16 像素等宽的 Anchor


到这一步,Anchor 输出格式是 (x_position, y, h) 的列表 :

但是,我们需要处理成和模型输出相同的格式 [batch, h, w, k=10, 4],其中的“4”分别是文字分数、背景分数、纵坐标 y 和高度 h。每16*16像素都需要生成10个 Anchor,高度分别是 [11, 16, 23, 33, 46, 66, 94, 134, 191, 273]。这些 Anchor 中,只有与上图找出的 Anchor 中,横坐标相同且面积交并比大于 0.7 的才能被判定为文字区域。
def overlap_anchors(img, box, anchor_width=16):
iou_threshold = 0.7
anchor_sizes = [11, 16, 23, 33, 46, 66, 94, 134, 191, 273]
anchors = generate_gt_anchor(img, box, anchor_width)
anchors = {x[0]: (x[1], x[2]) for x in anchors}
# print(anchors)
total_anchors = []
for h in range(imgg.shape[0] // anchor_width):
curH = []
total_anchors.append(curH)
for w in range(imgg.shape[1] // anchor_width):
curW = []
curH.append(curW)
for k in range(len(anchor_sizes)):
if w not in anchors:
curW.append([0, 1, 0, 1])
else:
cy, ch = anchors[w]
ty, th = h * anchor_width + anchor_width / 2, anchor_sizes[k]
if iou(cy, ch, ty, th) > iou_threshold:
curW.append([1, 0, ty, th])
else:
curW.append([0, 1, 0, 0])
return total_anchors
def iou(y1, h1, y2, h2):
b1, u1 = y1 - h1 / 2, y1 + h1 / 2
b2, u2 = y2 - h2 / 2, y2 + h2 / 2
if u2 > u1:
b1, u1, b2, u2 = b2, u2, b1, u1
if b1 >= u2:
return 0
else:
if b2 > b1:
return (u2 - b2) / (u1 - b1)
else:
return (u2 - b1) / (u1 - b2)最终输出的效果:

下一步计划
- 找到能跑得动模型的设备测试一下。