机器学习:Logisitic回归
机器学习 深度学习 NLP 搜索推荐 等 索引目录
Logistic回归(logistic regression)是统计学习中经典的分类方法,其模型属于对数线性模型。
1.Logistic分布(logistic distribution)
什么是logistic分布?
我们假设有一组变量 X X X是连续随机变量,当 X X X具有下列分布函数和密度函数时,我们就说 X X X服从Logistic分布,
分布函数:
F ( x ) = P ( x ≤ x ) = 1 1 + e − ( x − μ ) / γ F(x)=P(x\leq x) = \frac{1}{1+e^{-(x-\mu)/\gamma}} F(x)=P(x≤x)=1+e−(x−μ)/γ1
密度函数:
f ( x ) = F ′ ( x ) = e − ( x − μ ) / γ γ ( 1 + e − ( x − μ ) / γ ) 2 f(x)=F'(x)=\frac{e^{-(x-\mu)/\gamma}}{\gamma(1+e^{-(x-\mu)/\gamma})^2} f(x)=F′(x)=γ(1+e−(x−μ)/γ)2e−(x−μ)/γ
式中, μ \mu μ位置参数, γ > 0 \gamma > 0 γ>0为形状参数。
logistic分的密度函数 F ( x ) F(x) F(x)和分布函数 F ( x ) F(x) F(x)的图形如下所示:

分布函数属于logistic函数,是一条S曲线(Sigmoid),可以看出,曲线在中心附近增长速度较快,在两端增长速度较慢,形状参数 γ \gamma γ的值越小,曲线在中心附近增长得越快。
2.二项logistic回归模型
什么是二项logistic回归模型?
二项logistic回归模型是一种分类模型,其模型是如下的条件概率分布:
P ( Y = 1 ∣ x ) = e x p ( w ⋅ x + b ) 1 + e x p ( w ⋅ x + b ) P(Y=1|x)=\frac{exp(w\cdot x + b)}{1+exp(w\cdot x +b)} P(Y=1∣x)=1+exp(w⋅x+b)exp(w⋅x+b)
P ( Y = 0 ∣ x ) = 1 1 + e x p ( w ⋅ x + b ) P(Y=0|x)=\frac{1}{1+exp(w\cdot x +b)} P(Y=0∣x)=1+exp(w⋅x+b)1
其中x是输入, Y ∈ { 0 , 1 } Y\in \{0, 1\} Y∈{0,1} 是输出, w w w和 b b b是参数, w w w为权重向量, b b b为偏置。
上述两式即求出了实例 x x x的条件概率,logistic回归通过比较这两个条件概率的大小,将实例 x x x分到概率值较大的那一类。
3.模型参数估计
对于给定的训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1, y_1), (x_2, y_2), ...,(x_N, y_N)\} T={(x1,y1),(x2,y2),...,(xN,yN)},其中 y i ∈ { 0 , 1 } y_i\in\{0,1\} yi∈{0,1},这里应用极大似然法来估计模型参数。
假定:
P ( y = 1 ∣ x ; w ) = h w ( x ) P ( y = 0 ∣ x ; w ) = 1 − h w ( x ) P(y=1|x;w)=h_w(x) \\ P(y=0|x;w)=1-h_w(x) P(y=1∣x;w)=hw(x)P(y=0∣x;w)=1−hw(x)
则
P ( y ∣ x ; w ) = h w ( x ) y ( 1 − h w ( x ) ) ( 1 − y ) P(y|x;w)=h_w(x)^y(1-h_w(x))^{(1-y)} P(y∣x;w)=hw(x)y(1−hw(x))(1−y)
似然函数为
L ( w ) = p ( Y ∣ X ; w ) = ∏ i = 1 N p ( y ( i ) ∣ x ( i ) ; w ) = ∏ i = 1 N ( h w ( x ( i ) ) ) y ( 1 − h w ( x ( i ) ) ) ( 1 − y ( i ) ) \begin{aligned} L(w)&=p(Y|X;w) \\ &=\prod_{i=1}^{N}{p(y^{(i)}|x^{(i)};w)} \\ &=\prod_{i=1}^{N}{ (h_w(x^{(i)}))^y(1-h_w(x^{(i)}))^{(1-y^{(i)})} } \end{aligned} L(w)=p(Y∣X;w)=i=1∏Np(y(i)∣x(i);w)=i=1∏N(hw(x(i)))y(1−hw(x(i)))(1−y(i))
接下来就是取对数似然函数,对 对数似然函数取极大值,即得到w的估计值。
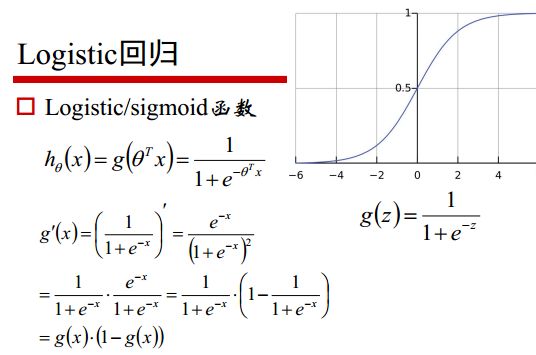
对对数函数求导的求导公式略繁琐,就以下面几张图片做展示(来自邹博老师的课件),这里的 θ \theta θ即为我们上面所描述的 w w w。