《Dynamic Residual Dense Network for Image Denoising》阅读笔记
一、论文
《Dynamic Residual Dense Network for Image Denoising》
摘要:深卷积神经网络在各种图像恢复任务上均取得了卓越的性能。 具体而言,通过密集级联多个残差密集块(RDB)以充分利用分层功能,残差密集网络(RDN)在减少图像噪声方面取得了出色的成果。 但是,RDN仅在单个噪声级别上的去噪性能良好,并且RDN的计算成本随着RDB数量的增加而显着增加,并且这仅会稍微改善去噪效果。 为了克服这个问题,我们提出了动态残差密集网络(DRDN),它是一种动态网络,可以根据输入图像的噪声量有选择地跳过某些RDB。 此外,DRDN允许修改降噪强度以手动获得最佳输出,这可以使网络对实际降噪更加有效。 我们提出的DRDN可以比RDN更好地执行,并将计算成本降低40-50%。 此外,在实际噪声基准上,我们比最新的CBDNet高出1.34 dB。
介绍:RDN级联数十个RDB,每个RDB通过密集的连接卷积层提取局部特征,这在推理时会消耗大量内存和计算成本。因此,我们将级联块视为一个序列,并使用包含RNN的门模块预测下一个块对处理当前特征图的重要性。 如果预测的重要性低于阈值,则跳过下一个块,并将该块退化为恒等函数。 此外,由于RDN没有用于估算实际噪声水平的模块,因此RDN仅在单个噪声水平上具有出色的降噪性能。 门模块将RDN从噪声电平估计中释放出来。 此外,它使RDN达到可调节的降噪强度水平,从而更好地满足了人类的感知。 我们提出的网络可以根据噪声量动态调整RDN中使用的块数,因此我们将其称为动态残差密集网络。
二、网络结构
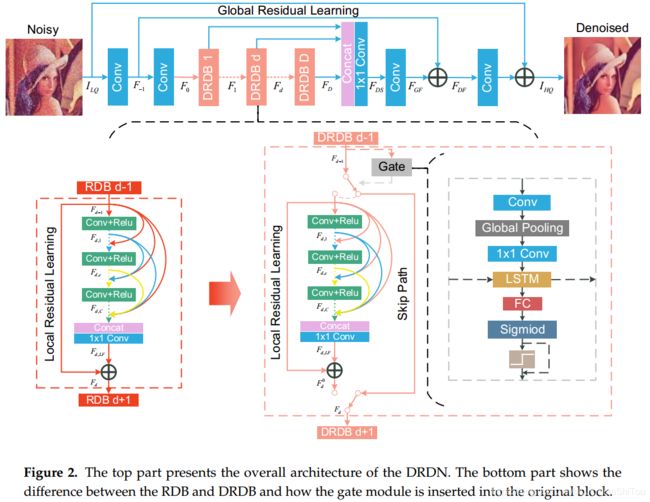
如图2的顶部所示,我们提出的DRDN主要包括四个部分:特征提取模块,动态残差密集块(DRDB),特征融合和重建模块。 具体来说,特征提取模块使用两个卷积层来提取浅层特征:
 与RDN不同,DRDN使用DRDB提取局部特征,可以通过以下方式获得:
与RDN不同,DRDN使用DRDB提取局部特征,可以通过以下方式获得:

然后,我们在提取局部特征后使用特征融合来充分利用多尺度信息。 如前所述,特征融合还是一个深度监管模块。 全局特征融合可以通过:
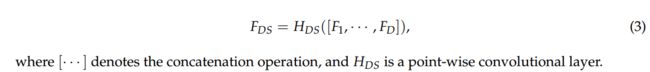
与特征提取模块一样,重构模块也使用两个卷积层来重构图像,并使用全局残差学习来更轻松地获得高频特征: 1、Dynamic Residual Dense Block
1、Dynamic Residual Dense Block
图2的底部展示了我们提出的动态残差密集块(DRDB)的细节。 每个DRDB包含两条路径,并使用Gate模块做出二进制决策来确定选择哪条路径。 路径之一是身份函数,另一路径包括三个部分:密集块,局部特征融合和局部残差学习。 这与RDB中的相同。DRDB中的密集块包含C个卷积层,第c个卷积层可以通过以下方式获得:
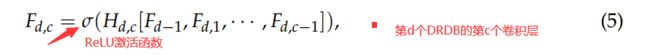
局部特征融合与全局特征融合相似,第d个DRDB的输出可以表示为:
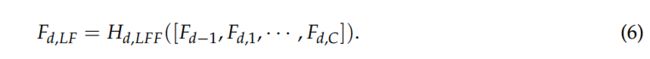
局部残差学习类似于全局残差学习,可以通过以下方法获得:

如图2所示,门模块包含一个卷积层以提取决策特征,然后是全局平均池[32]和一个点状卷积层以减少张量。 卷积层,全局平均池和逐点卷积层处理先前的特征图,仅保留对于二进制决定是否跳过后面的块有用的信息。 保留的信息可能包括噪音水平和其他重要特征。 该过程可以视为瓶颈层,可以通过以下方法获得
![]()
其中Dd表示瓶颈层输出的第d,而HC,PGA和HP表示卷积层,全局平均池和逐点卷积层。
然后,我们使用LSTM [33]使决策信息在块之间流动。 由于门模块实际上是为了解决顺序决策任务,因此LSTM在决策中起着重要作用。 LSTM允许当前的门模块记住以前的门模块的选择。 当先前的门模块选择跳过后面的块时,当前的门模块将适当降低跳过的可能性。 最后,我们应用一个完全连接的层和一个S型函数,再加上一个二元阶跃函数来做出二元决策。
由于梯度不能在二进制步长函数中有效地流动,因此我们仅将二进制步长函数应用于前向传播,而在后向传播中跳过它。 该程序可以通过以下方式获得
 最后,每个DRDB的输出由gate模块确定。 当门模块的输出为0时,第d个DRDB的输出与第(d-1)个DRDB的输出相同。 门模块的输出为1时,我们将剩余密集块的输出作为输出。 更确切地说,这可以表述为
最后,每个DRDB的输出由gate模块确定。 当门模块的输出为0时,第d个DRDB的输出与第(d-1)个DRDB的输出相同。 门模块的输出为1时,我们将剩余密集块的输出作为输出。 更确切地说,这可以表述为
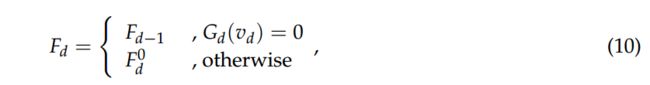
其中vd表示第d个门模块中完全连接层的输出矢量。
训练时,门控模块的决定会影响DRDB中的梯度传播。 当门模块的输出为0时,门模块将跟随的块退化为标识函数。 这意味着将不计算跟随块的梯度。当门模块的输出为1时,后面的块将进一步处理先前的特征图,并将计算其梯度。 无论门模块的决定是什么,门模块中的梯度将始终传播。
进行推断时,由于网络仅执行前向传播,因此如果门模块的输出为0,则无需获取残差密集块的输出。我们可以收集所有门模块的输出以计算残差的数量 跳过块。 我们计算被跳过的块与总块的比率,这称为跳过比率。 同时,可以通过修改阈值t来改变跳过率和网络的去噪强度。 但是,由于阈值和跳过率不一致,因此我们使用简单的线性变换将阈值映射到跳过率:
![]()
其中 表示跳跃比,
表示跳跃比, 和
和 是根据训练模型调整的参数。 我们使用固定参数(= 0.1,= 0.49)进行概括。
是根据训练模型调整的参数。 我们使用固定参数(= 0.1,= 0.49)进行概括。
2、训练算法
培训过程分为三个阶段。 我们在每个阶段使用相同的损失函数,但是每个阶段的参数都不同。 损耗函数由L1损耗和门模块的平均输出概率组成。 损失函数可以表述为:

其中y和yˆ分别表示输出图像和地面真实图像,a用于平衡效果和计算成本。
阶段1:由于门控模块的决定会影响DRDB中的梯度传播,因此必须进行简单的预训练才能确保每个DRDB都具有去噪能力。我们将所有门模块的输出固定为1,即DRDN不会跳过任何密集的残差块)。 接下来,我们使用正交矩阵[34]来初始化卷积层的参数。 在此阶段,由于我们正在训练RDN且不需要考虑门模块,因此将0设置为in训练。 由于门模块不参与顺序决策,因此不会计算其梯度。
阶段2:我们还在训练中将0设置为a,但不再固定门模块的输出。 我们将门模块的参数初始化为较小的值,以使输出在开始时接近于0。 经过第一阶段的培训,DRDB已获得了基本的降噪能力。 在此阶段(包括此阶段)之后,门模块将参与梯度传播。 这使门模块学习了提取有用信息的能力。 最后,DRDN将为二进制决策获取适当的参数。
阶段3。我们将a设置为10−4以引导门模块跳过更多不重要的块。 在训练了第1阶段和第2阶段之后,所有块都学习了去噪能力,并且彼此之间几乎没有依赖。但是,我们没有有效指导门模块的决策。 因此,我们激活损耗函数的正则项并直接限制门模块的输出。 对于此阶段,需要在跳过率稳定后使学习率变小。 这样可以使DRDN获得更好的去噪能力。
可选的: 我们还将强化学习作为第四阶段来训练门模块,以进一步提高跳过率。 但是,在我们的实验中,强化学习可能会稍微恶化结果,并通过调整阈值来限制网络更改降噪强度的能力。 相反,DRDN可以通过强化学习获得更高的跳过率。 因此,我们将此阶段视为可选的培训阶段。 具体而言,第d DRDB的奖励可以表示如下:
![]()

三、代码
代码未开源
四、参考资料
Paper | Dynamic Residual Dense Network for Image Denoising
DRDN 阅读笔记
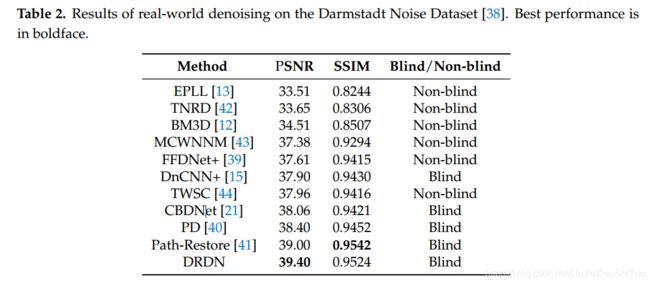
在本文中,我们提出了一种DRDN模型来减少真实世界图像的噪声。 我们提出的DRDN充分利用了残余连接和深度监控的特性。 我们提出了一种对具有不同噪声量的图像进行降噪的方法,同时降低了平均计算成本。 我们方法的核心思想是动态改变去噪中涉及的块数,以通过顺序决策来改变去噪强度。 此外,我们的方法可以手动调整模型的去噪强度,而无需微调参数。