转自七月算法班--寒老师
学习笔记
之前实验室是做社交网络的,主要是爬取的一些新浪微博的数据,来做一些社交行为的预测;或者是爬取豆瓣网的一些数据,根据社交网络的一些性质来做书籍电影或者话题等等的推荐。
从研二开始,老师给我的要求是在社交网络上看看能不能想到什么点,可以用条件场的方法去做,我想了很久,其中有一个点是关于迁移学习的,无奈在数据的抓取,以及难度颇高被老师否决了。关于这个方面我大致也看了2个月的paper。后来去弄机器学习应用在数据安全领域也是有契机的,因为实验室是重庆市的重点安全实验室,加上刘老师又是重庆邮电大学安全领域的牵头人,因此每年都需要在安全方面产出一些论文,于是老师让我转入了安全攻防方向。
但是,推荐始终是整个实验室大部分人研究的主题,关于这一块,我必须认真补一补。
个人的准备是:书+paper+视频
书:推荐系统实战
paper:sci+ei+计算机学报+软件学报
视频:七月算法班
-----推荐系统是什么
根据用户的一些信息去判断用户当前的需求/感兴趣的item
1) 历史行为
2) 社交关系(实验室重点研究特征,显示链接 | 隐链接)
3)兴趣点
4)上下文关系
.....
---推荐系统之应用
-----Netflix推荐电影
----Google news能够带来额外的38%的点击
-----亚马逊35%的销售额都来源于它的推荐
-----头条半数以上的新闻和广告点击都来源于推荐
----京东一年推荐和广告有几亿的收益
---推荐系统之系统结构
离线部分---训练模型 [准确度]
在线部分--根据上下文信息给出最后推荐结果 [速度]
准确度+速度
-----推荐系统--评定标准
---1. 评分系统

----2. topN推荐

--覆盖率
表示对物品长尾的挖掘能力,越长可能个性化程度高(推荐系统希望消除马太效应【热门】)
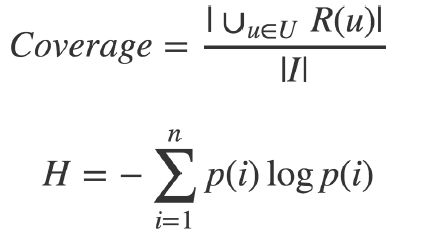
I为商品库的某个子类的全集,分子是从这个里面推荐出去了多少
从信息熵的角度,p为推荐概率=第i个商品推荐的次数 / 总次数
当所有商品被推荐概率为0.5时,H最大。可以更精准地度量覆盖率
---多样性
表示推荐列表中的物品两两之间的不相似性
S(i,j)表示两个物品之间的相似度
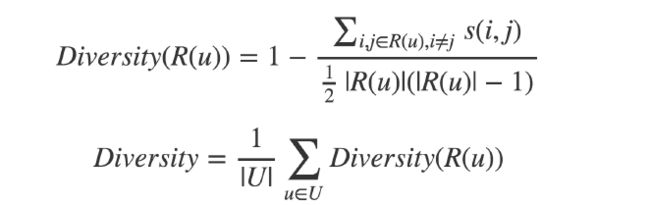
注意:上面的分母表示Cn^2排列组合的展开
--其他标准
-新颖度 -不知道的商品
-惊喜度 -和兴趣不相似,却满意的
-信任度 -可靠的推荐理由
-实时性 - 实时更新程度
举例 --NetFlix的复杂推荐模型
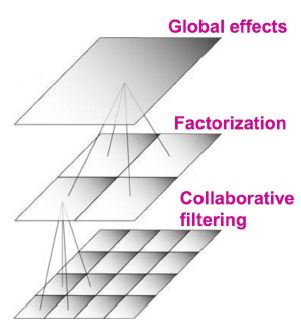
经典算法初步
---基于内容的推荐
---基于用户喜欢的item的属性/内容进行推荐
---需要分析内容,无需考虑行为
---通常在文本相关的产品进行推荐
--item通过内容(关键词)关联
------电影题材:爱情/探险/动作/喜剧
------标志特征:黄晓明/王宝强
------年代:1995,2017
------关键词
--基于比对item内容进行推荐
方法:
----对于每个要推荐的内容,建立一份资料
-------比如词ki在文件dj的权重wij(常用方法:TF-IDF)
----对用户也建立一份资料
-------比如定义一个权重向量(wc1,...,wck)wci表示第ki个词对用户c的重要程度
----计算匹配度
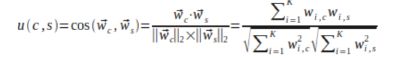
坏处:耗时,每个文本需要建立向量进行挖掘
好处:不需要加入用户行为信息
----协同过滤
----user-based
找到和用户最近的其他用户,找到他们看/买过但是当前用户每一买过的item,根据距离加权打分
找到最高的推荐


根据用户对商品/内容的行为,计算item和item的相似度,找到和当前item最接近的进行推荐
--相似度和距离度量

Jaccard相似度适合0-1的值
Person和余弦相似度的区别在于Pearson会对每个向量减去均值

Pearson向量之所以要减去均值是因为用户存在偏好,Pearson可以做相对的归一再来计算相似度
----基于用户的协同过滤

----推荐系统之--冷启动问题
--对于新用户
1. 所有推荐系统对于新用户都有这个问题
2. 推荐非常热门的商品,收集一些信息
3. 在用户注册的时候收集一些信息
4. 在用户注册完之后,用一些互动游戏确定喜欢与不喜欢
--对于新商品
1. 根据商品本身属性,求与原来商品的相似度
2. item-based协同过滤可以推荐出去
----隐语义模型(区别于协同过滤)

隐因子分析

分别对两个维度进行factor分析
对用户和电影的因子进行计算
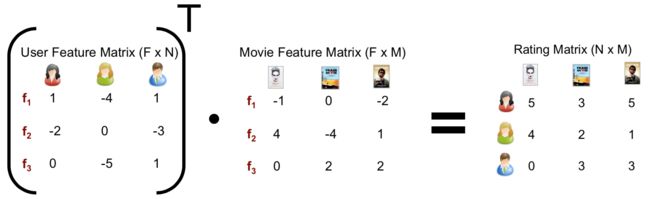
隐语义模型包括:pLSA,LDA,Topic model,Matrix factorization,factorized model
----隐语义模型
----需要矩阵分解,首先想到SVD,但是SVD的时间复杂度是O(m^3),同时原矩阵的缺省值太多。
隐语义模型
--最简单的办法是直接矩阵分解
--CF简单直接可解释性强【缺点:数据稀疏关联不上】,但隐语义模型能更好地挖掘用户和item关联中的隐藏因子
举例:
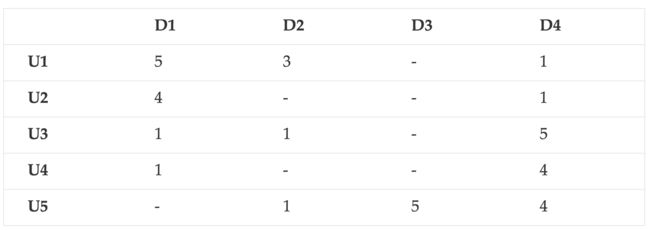
解法:

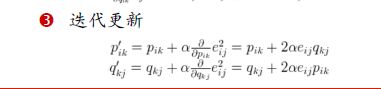
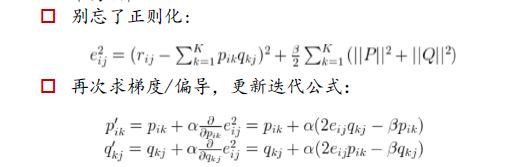
再还原回矩阵乘积,即可补充未打分项
通常情况下,我们会限定分解得到的P和Q中的元素都非负,这样得到的结果是一定程度上可解释的
因为不存在减法操作,因此可以看作对隐变量特征的线性加权拟合
LibMF,LibSVD
---加Bias的隐语义模型
评价系统均值,用户的bias,电影的bias
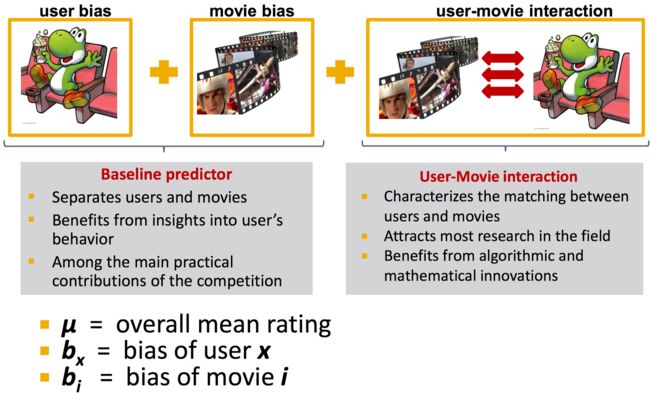


Netflix推荐优化过程

0.85这个应该还叠加了其他的tricks在里面
-----------Word2vec与用户行为序列
1.我们给定中文分词后的文本,使用word2vec能得到每个词(phrase)在高维空间的特征向量。
2.向量和向量之间的距离远近,表示2个词的关联度高低。
3.和“北京”最近的词为“东京”“柏林”“巴黎”“伦敦”
----在推荐里怎么用?
1. 把用户的行为序列当做分词过后的phrase
2. 送给word2vec学习
3.根据商品映射得到的特征向量去找相似的商品
本质上也是体现商品关联,但是比协同过滤覆盖度高
--个性化结果展出方式
----按照不同维度(比如题材展出)
----排序的结果使用上下文信息重排
----对于结果都提供解释(解释理由)
---如何得到数据?
---隐性反馈:
最近观看,打分情况,浏览,停留时间
---显性数据:
用户偏好
标准:准确度RMSE,MSE,丰富度(覆盖率),新鲜度(怎么做?)
CF+MF+Word2vec+Learningtorank(比如PageRank)