R语言文本挖掘和词云可视化实践
互联网时代,大量的新闻信息、网络交互、舆情信息以文本形式存储在数据库中,如何利用数据分析和文本挖掘的算法,将海量文本的价值挖掘出来,成为我们团队近期的一个研究方向,本案例就是我们的一个初步尝试。飞信群是我们在工作、生活中交流的重要平台,在将近一年的时间里共产生了几万条的聊天记录,展现了我们这个团队的方方面面。
本文将通过KNIME、R语言和tagxedo三个工具来实现文本挖掘和词云可视化技术,体验一下舆情分析的魅力。
一、数据导入
数据源:2014年10月—2015年7月的飞信群全部聊天记录:

图一 原数据示例
通过KNIME进行原始聊天记录文件的结构化转换,提取文件中发言人、发言时间和发言内容三个字段,并保存为csv文件。
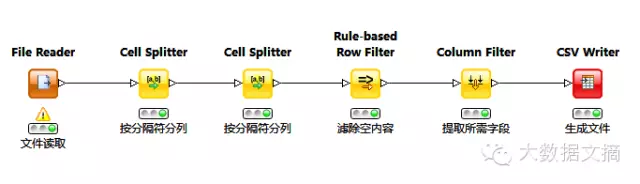
图二 KNIME的流程
R语言的语句:
log <- read.csv('feixin.csv', sep=",", header=FALSE) #数据导入并保存为log对象
二、发言热度分布
通过热力图,我们可以看到大家聊天的热情在2014年12月最为高涨,而2015年的2月由于春节原因,群里冷冷清清了好久。周末2天的空档期也展现的很清晰哦。
R语言的语句:
require(plyr)
time <- as.POSIXlt(log$V3,origin = '1970-1-1 00:00:00' ,format="%Y-%m-%d %H:%M:%S") #设置日期格式
cbind(format(time,"%Y-%m"),format(time,"%d"))->day_table #生成发言时间分布表
as.data.frame(day_table)->day_table #转换数据框格式
table(day_table)->day_m #生成日期列联表
heatmap(day_m,Rowv=NA,Colv=NA,scale = "column",col=brewer.pal(4,"Blues"),revC = TRUE)
#绘制按日发言量的热力图,蓝色越深代表发言热度越高。
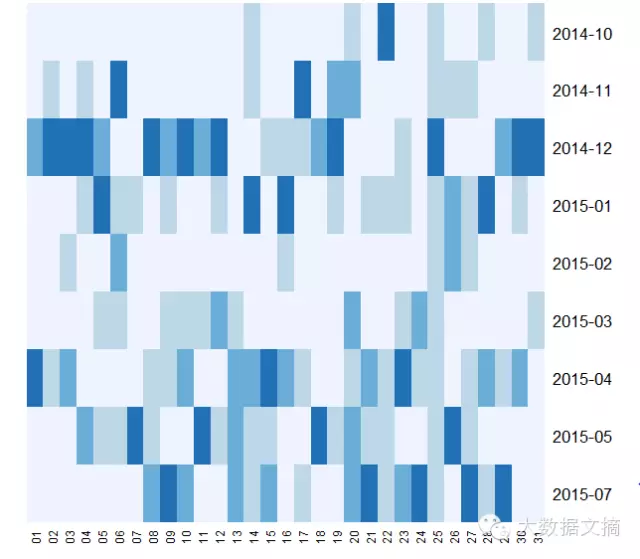
图三 热度分析
三、个人发言习惯分析
谁最能说?通过条形图可以清晰的看到大家发言的频率对比,一目了然。
R语言的语句:
require(plyr)
require(ggplot2)
name=log$V2 #获取发言人姓名字段
table(name)->t_name #生成按姓名出现频率的列联表
as.data.frame(t_name)->t_name #转换为数据框格式
gg = ggplot(t_name)
gg+geom_bar(aes(x=reorder(name,Freq),y=Freq,fill=name),stat="identity",position="dodge")+coord_flip()+theme(axis.title=element_text(size=18,color="blue"),axis.text=element_text(family='A',size=22,color="black")) 用ggplot扩展包绘制条形图

图四 发言量分析
注:因为涉及个人隐私所以把图上10个人的名字都隐去了
有趣的来了,看看我们每个人喜欢在什么时间说话吧。大家都是有两个发言高峰,一个是上午10点,一个是下午4点左右,而中午12点是一个明显的午休静默期。另外可以看到,有些童鞋在上午说话的频率高于下午,有些则正相反。
R语言的语句:
require(plyr)
time <- as.POSIXlt(log$V3,origin = '1970-1-1 00:00:00' ,format="%Y-%m-%d %H:%M:%S")
#设置日期格式
hour <- format(time,'%H') #提取日期值中的“小时”数
hour_name <- as.data.frame(cbind(log$V2,hour))
count(hour_name,V1,hour)->hour_table #计算每人按小时发言的频次
as.character(hour_name$hour)->hour_name$hour
as.numeric(hour_name$hour)->hour_name$hour #将“小时”字段转换为数字格式
gg=ggplot(hour_name)
gg+ geom_density(aes(x=hour,fill=V1))+facet_wrap(~V1) +theme( strip.text=element_text(family='A',size=18,color="black"),axis.text=element_text(family='A',size=16,color="black")) #通过ggplot扩展包绘制基于发言时间段分布的面积图
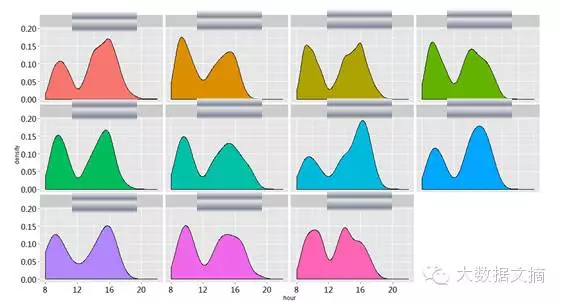
图五 发言时间分布
注:因为涉及个人隐私所以把图上10个人的名字都隐去了
四、词云可视化
震撼的来了,看看这一年大家最关心什么?讨论最多的是什么?有什么有趣的话题呢?为了和团队的LOGO呼应,选用大象轮廓的词云图,效果棒棒哒。
R语言的语句:
require(tm)
require(Rwordseg)
gsub("[0-9,a-z,A-Z]", "", log$V1)->t #去除英文和数字
segmentCN(t)->t_seg #中文分词
removeWords(unlist(t_seg),mystopword)->word #去除停用词
word = lapply(X = word, FUN = strsplit, " ") #将分词结果按空格分隔整理
v = table(unlist(word)) #计算每个单词的词频
v = sort(v, decreasing = T) #按降序排列
d = data.frame(word = names(v), freq = v) #将词频矩阵转换为数据框格式
d$word=as.character(d$word) #将单词字段规整为字符串格式
rbind(d[nchar(d$word)==1,][1:10,],d[nchar(d$word)==2,][1:20,],d[nchar(d$word)>3,][1:20,])->result_r #提取不同字数的单词中词频最高的TOP50单词,作为词云绘制的素材
write.table(result_r,"result.csv",sep=",",row.names = FALSE) #保存结果为csv文件
通过一款开源的词云可视化工具tagxedo,将导出的词频矩阵绘制为各种形状的词云图。

图六 团队词云
看看,除了对“数据”、“互联网”的关心是天经地义的,我们说的最多的竟然是“吃”,名副其实的“吃货”团队,民以食为天嘛。“周报”赫然醒目也是醉了,其它的高频词都和工作息息相关,“实验室”、“工程师”,还有“平台”、“服务器”、“数据库”,真心是学习型聊天群啊。最开心的要数“哈哈哈”,证明我们的工作也是欢笑多多,其乐无穷的。
想看到每位童鞋的词云有什么不同么?

图七 个体词云一
爽朗的“哈哈哈”,愤怒的“啊啊啊”,最擅用“[图片]”在群里展现心情。致我们的美女数据分析师,也是团队大象logo的设计者。
下面重磅推出我们的首席数据科学家,瞧瞧科学家的世界与我们是多么的不同。竟然……基本都是英文术语。

图八个体词云二
五、建模流程
下面用一张图简单回顾一下本文实现的建模过程:
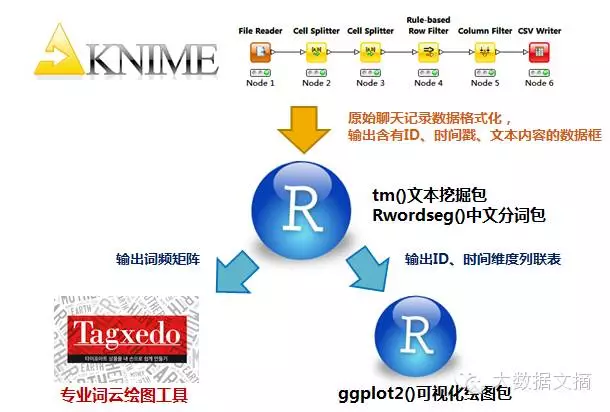
图九 整体分析思路
希望上面的案例分析能帮助大家更好的理解文本挖掘和舆情分析可视化的一些分析思路和呈现方式,我们也会尽力挖掘更多的创意,制作更好的产品呈现给大家,谢谢!。
转载自:http://mp.weixin.qq.com/s?__biz=MjM5MTQzNzU2NA==&mid=209424027&idx=1&sn=5858f6171df8a498ae8e40b3f09e2d1b&scene=0#rd