该文为Momenta Paper Reading 第一季第八期回顾,始发于2017年4月18日。
分享视频回放链接:Momenta Paper Reading 第一季
PPT及论文等资料请见文末,添加小助手微信获取
主讲人
吴子章
纵目科技自动驾驶公司视觉算法工程师,主要研究道路场景下的目标检测、分割及跟踪等,并推进相关算法性能优化与嵌入式移植等。
分享内容
在图像的目标检测任务中,由于目标尺寸变化,需要在不同的尺寸下对目标进行检测,从而演化出许许多多解决目标检测任务中的尺度问题的方法,比如Fast-RCNN,及Faster-RCNN及后面的SSD,YOLO等网络。
那么在场景解析任务中是否存在尺度问题呢?答案是肯定的。
场景解析在这里确切地说是基于图像的像素级别的语义分割,不同尺寸的物体需要在不同的感受野范围内才能相对容易的将其与背景分割开来。那么如何解决不同的场景或分割的目标需要不同尺寸感受野的问题呢?也即是如何解决分割任务中的尺度问题呢?
在图像目标检测任务中,我们知道目前有许多深度学习网络使用基于SPPNET演化而来的多种尺寸的特征进行融合的方式来解决尺度变化的问题。而在图像分割任务中,同样可以采用类似的思想,例如PSPNET中的金字塔解析网络、Refine-NET中图像的多级处理等;
首先,让我们从两方面回顾一下,图像分割任务的发展历程:
1.从使用的数据集看图像分割;
早些时候的场景解析任务是对2668张图片分出33个场景,以LMO dataset为代表; 稍微近一些的是PASCAL VOC数据集上,在相似的物体上提供了更加详细的标签;比如椅子和沙发,马和牛等;之后出现的KITTI与CityScapes上都有语义分割任务,比如道路可通行区域等。最近的ADE20K dataset是最有挑战性的一个数据集,提供了尺度变化更大、词汇内容丰富且类别更多的数据。
从使用的数据集发展由易到难上能够看出图像语义分割的逐步发展,这些进步与软硬件设备尤其是软件算法的长足进步是牢不可分的。


2.从算法的发展演化看图像分割:
1)FCN
在2015年之前,CNN能够对图片进行分类,但是怎样才能识别图像中特定部分的物体还是一个世界性的难题。于是图像语义分割的一个标志性的发展事件就是神经网络大神Jonathan Long 发表《Fully Convolutional Networks for Semantic Segmentation》,即FCN全卷积网络的诞生,它的贡献主要有两点:
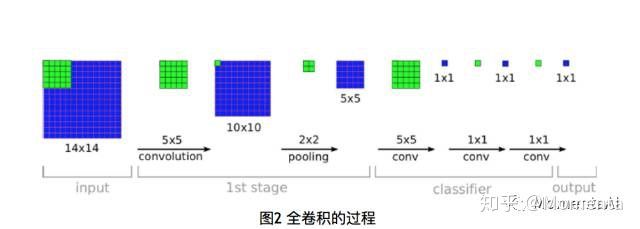
a)使用全卷积替换全连接。不但去除了全连接层对网络结构的限制,还大量减少参数与计算量,提高网络的性能。然后使用反卷积层来上采样得到与原图同样大小的分割图。这里使用的全卷积的概念如下图所示,最开始是在《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks》文章中提出。
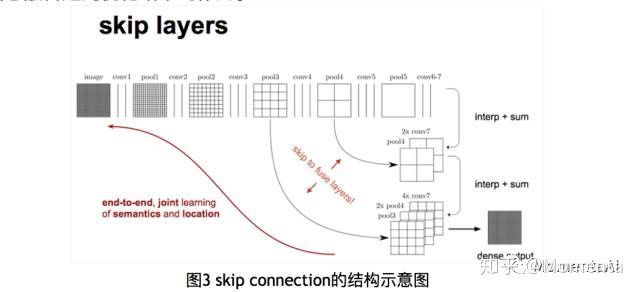
b)使用跳跃结构将不同尺度与不同感受野情况下的特征图结合起来。因为在32倍下采样后直接上采样得到的效果是十分模糊的。所以使用上述方式将不同池化层的结果进行上采样后来优化输出。我们知道在高层特征中保留了更多的语义信息,但丢失了较多的空间位置信息;而低层特征保留了更多的细节信息与位置信息,但上下文信息相对较少。此处的信息融合起到优化结果的作用。
但是FCN得到的结果不够精细,对细节不敏感,且没有充分考虑像素与像素直接的关系,缺乏空间一致性。
2)SegNet

2016年剑桥大学提出的SegNet,使用不到1000张图训练出城市道路分割网络,对很多场景都有很好的泛化性。其对称结构有种自编码器的感觉在里面,先编码再解码,逐步的编码解码使得其能够较多地保留细节信息,得到的效果总体不错。
3)DeepLab
2016年在FCN的基础上,提出优雅的池化与带孔的卷积,其贡献主要如下:
a)对于repeated convolution导致分辨率丢失的问题。作者采用了一个叫做atrous convolution 的卷积操作,同时添加了一个rate 来跳过若干个相邻的卷积核,起到了maxpooling+ convolution的作用。
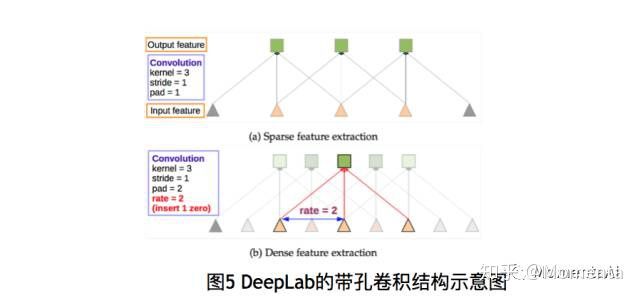
b)对于传统的强行将图像转换为相同尺寸的方法容易导致某些特征扭曲或消失,使用了ASPP (atrous SPP)来解决这个问题。通过不同的A convolution 来对图像进行不同程度的缩放,得到不同大小的input feature map,(可以理解成SPP中使用不同大小的proposal),这样ASPP 就保证了deeplabNet 可以处理不同尺寸的图片。

这里介绍了FCN, SegNet/DeconvNet,DeepLab,当然还有一些其他的结构方法,比如有用RNN来做的,还有更有实际意义的weakly-supervised方法等等。总体来说,目前比较通用或常用的框架如图7所示,这里的FCN可以替换为其他分割网络。

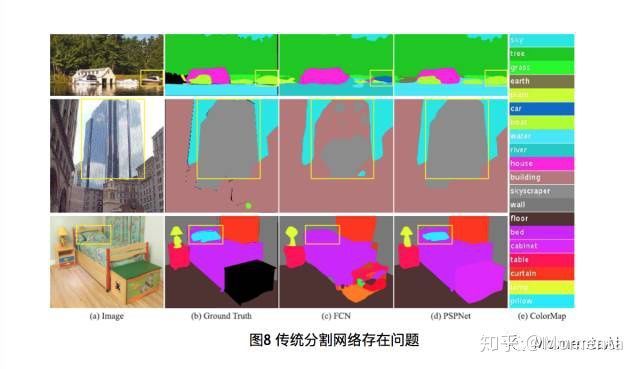
由于目前的分割网络存在如下三类问题:错误的上下文信息(感受野不合适或不够大)、易分错的类别(感受野不够大)、易忽略的物体分类(感受野不够小或不合适);于是提出金字塔场景解析网络,如图9所示:

与SPPnet结构类似,这里为了去除不同子区域之间的上下文信息损失,采用层级的全局先验知识,包含不同尺度不同区域的信息,这个结构就叫金字塔池化模块Pyramid Pooling Module。如图9所示,从输入图像使用基础网络得到一定尺寸的特征图(这里90*90),然后对特征图使用多个不同尺度的池化,得到不同级别的池化后的特征图,之后再将各个不同尺寸的特征图上采样得到同样尺寸的特征图(90*90),之后在concate起来,再使用卷积等操作。
这里最上面的池化后的特征的感受野是整张图像,下面跟着的2*2的特征图其感受野是1/2张图像,再下面的特征图的感受野依次减小。目前的池化结构保持了一定的差距,使用concate进行融合,如图10所示。

该结构使用金字塔池化实现不同尺度的感受野,有两层作用:1,将局部区域上下文信息与全局上下文信息结合;2,将整体轮廓信息与细节纹理结合。因此,在一定程度上解决了分割任务中的多尺度问题。
另外一方面,训练基础网络过程中使用了辅助loss,来将复杂的优化问题分阶段解决,降低了优化与训练的难度。
文章给出了在AED20K数据集上的实验效果,如图11。另外,主讲人也使用原文作者公开的模型和代码,在自有数据上进行finetune,进行道路和非道路预测,图12是一个结果示例。

综上可知,分割网络的尺度问题可以通过特征图的多尺度池化来解决,同时使用不同尺度池化后的特征融合来实现不同感受野的上下文信息融合,与整体轮廓与纹理细节的融合。从而在大尺度物体的分割与小尺度问题的分割上都能有效地结合上下文信息,同时尽量少的丢失细节信息,实现高质量的像素级别的语义分割。
