【机器学习实例】Titanic生存预测
数据集及代码链接:https://github.com/CCH21/Lab_MLGroup_Tasks/tree/master/Task_Titanic
数据集概述
如下图所示,Titanic数据集共包含有三个csv文件,其中train.csv是训练集,test.csv是待预测的测试集,gender_submission.csv是测试集的真实结果。




数据描述
import pandas as pd
from IPython.display import display
# 查看训练集和测试集
training_set = pd.read_csv('train.csv')
test_set = pd.read_csv('test.csv')
display(training_set)
display(test_set)


特征选择与数据预处理
首先,我们需要查看一下训练集和测试集的特征值缺失情况。
# 查看训练集各特征的缺失情况
for column in training_set.columns:
print('%-15s%-10.4f%-3d' % (column, training_set[column].count() / len(training_set), training_set[column].count()))

# 查看测试集各特征的缺失情况
for column in test_set.columns:
print('%-15s%-10.4f%-3d' % (column, test_set[column].count() / len(test_set), test_set[column].count()))
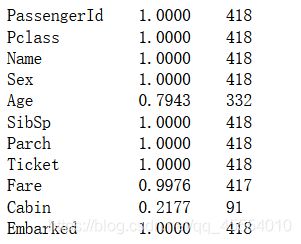
可以看出,在训练集中,Age, Cabin和Embarked特征是有缺失值的,其中Cabin的缺失值占到了超过77%的比例。在测试集中,Age, Fare和Cabin特征有缺失值。
观察数据。Cabin的缺失值过多,这时有两种解决方案,一是给所有的缺失值标记上Unknown,二是直接删除这一特征。由于船舱号比较复杂,难以进行分析,因此选择直接删除这一特征列。PassengerID肯定与最终的预测结果无关,因此删除此列。Ticket特征同样难以分析,因此删掉。比较特殊的是Name一列,它其实包含了一些人物的性别、社会地位等信息,可以保留但不易分析。其实,性别与社会地位这方面的信息,我们可以从Sex和Fare等特征中得知,故删除Name列。
# 删除PassengerId, Name, Ticket, Cabin特征
training_set = training_set.drop(columns=['PassengerId', 'Name', 'Ticket', 'Cabin'])
test_set = test_set.drop(columns=['PassengerId', 'Name', 'Ticket', 'Cabin'])
display(training_set)
display(test_set)


接下来是对缺失值的处理。目前训练集还有两个特征值有缺失值,分别是Age和Embarked。对于Age特征,我们可以用训练集中Age一列的平均值来填补完整。对于Embarked特征,由于只有两个样本有缺失值,因此可以直接删除这两个样本。
# 用训练集Age一列的平均数填补Age缺失值
training_set['Age'] = training_set['Age'].fillna(training_set['Age'].mean())
# 去除训练集中有缺失值的样本
training_set.dropna(axis=0,inplace=True)
display(training_set)

再次检查训练集,可以发现所有的样本的特征值都是完整无空缺的。
# 检查训练集的缺失情况
for column in training_set.columns:
print('%-15s%-10.4f%-3d' % (column, training_set[column].count() / len(training_set), training_set[column].count()))

对于测试集的空缺值,我们不能选择删除样本的方式。通过观察数据集可以发现,Fare一列有一个频繁出现的8.05。由于Fare一列缺失值不多,因此选择用众数填补。Age一列的缺失值仍然选择使用平均值填补。
# 处理测试集的缺失值
# 用测试集Fare一列的众数填补Fare缺失值
test_set['Fare'] = test_set['Fare'].fillna(test_set['Fare'].dropna().mode()[0])
# 用测试集Age一列的平均数填补Age缺失值
test_set['Age'] = test_set['Age'].fillna(test_set['Age'].mean())
display(test_set)

# 检查测试集的缺失情况
for column in test_set.columns:
print('%-15s%-10.4f%-3d' % (column, test_set[column].count() / len(test_set), test_set[column].count()))

接下来我们加载存活结果数据集,并且指定X_train, X_test, y_train, y_test。
# 加载存活结果数据集
result_set = pd.read_csv('gender_submission.csv')
display(result_set)

X_train = training_set.drop(columns=['Survived'])
y_train = training_set['Survived']
X_test = test_set
y_test = result_set.drop(columns=['PassengerId'])
display(X_train)
display(y_train)
display(X_test)
display(y_test)



下面我们利用sklearn.feature_extraction中的DictVectorizer特征转换器,将不为数值型的特征进行转换。转换特征后,类别型特征都单独剥离出来,独成一列特征,数值型特征则保持不变。
# 使用特征转换器
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer(sparse=False)
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
print(vec.feature_names_)
X_test = vec.transform(X_test.to_dict(orient='record'))
print(vec.feature_names_)
![]()
使用机器学习模型预测并且进行模型评估
这里我选择了两个模型,分别是k-NN分类器和决策树分类器。
# 使用决策树分类器模型
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc.fit(X_train, y_train)
y_predict = dtc.predict(X_test)
print(y_predict)

from sklearn.metrics import classification_report
print('Training set score: {:.2f}'.format(dtc.score(X_train, y_train)))
print('Test set score: {:.2f}'.format(dtc.score(X_test, y_test)))
# 输出更加详细的分类性能
print(classification_report(y_predict, y_test, target_names=['died', 'survived']))

决策树分类器的预测准确度在77%左右,并且识别遇难者的准确率要优于识别幸存者。
# 使用k-NN分类器模型
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
training_accuracy = []
test_accuracy = []
neighbors_settings = range(1, 11)
for n_neighbors in neighbors_settings:
knn = KNeighborsClassifier(n_neighbors=n_neighbors)
knn.fit(X_train, y_train)
# 记录训练集精度
training_accuracy.append(knn.score(X_train, y_train))
# 记录泛化精度
test_accuracy.append(knn.score(X_test, y_test))
plt.plot(neighbors_settings, training_accuracy, label='training accuracy')
plt.plot(neighbors_settings, test_accuracy, label='test accuracy')
plt.ylabel('Accuracy')
plt.xlabel('n_neighbors')
plt.legend()

通过改变n_neighbors的值(范围为区间[1, 10])建立不同的k-NN分类器,并且记录其训练集精度和泛化精度,绘制出折线图。从折线图中可以看出,当n_neighbors = 5时,泛化精度最高。
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
y_predict = knn.predict(X_test)
print(y_predict)
print('Training set score: {:.2f}'.format(knn.score(X_train, y_train)))
print('Test set score: {:.2f}'.format(knn.score(X_test, y_test)))

k-NN分类器的预测准确率大概在72%左右,稍逊于决策树分类器。