jvm运行时内存是怎么分布的?
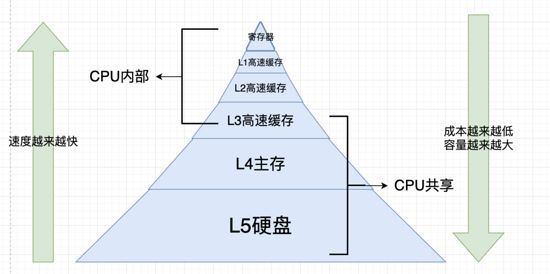
寄存器中的内存最小速度最快,硬盘容量最大,速度最小,cup的第三级缓存是共享内存。
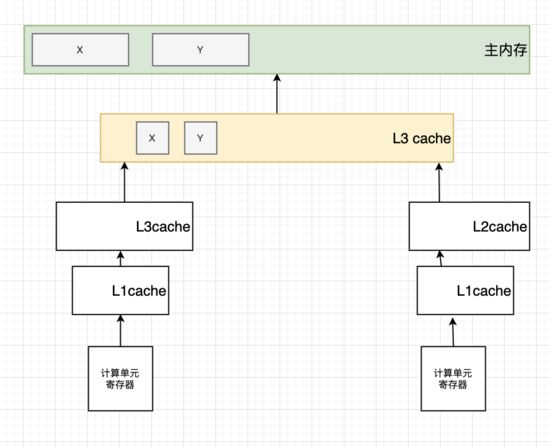
对于一个在同一行的数据XY,会被同时加载进CPU,这个现象叫cache line缓存行对齐, 如果左边的CPU核心加载了X并进行修改,但是此时并没有将数据写回进主内存,或者是第三级缓存,此时右边的CPU核心将X读进,并修改,此时就会产生数据不一致的情况。对于左边修改了数据右边如何才能知道,这是硬件层级需要解决的。 多线程一致性的硬件支持有一下集中方式。
-
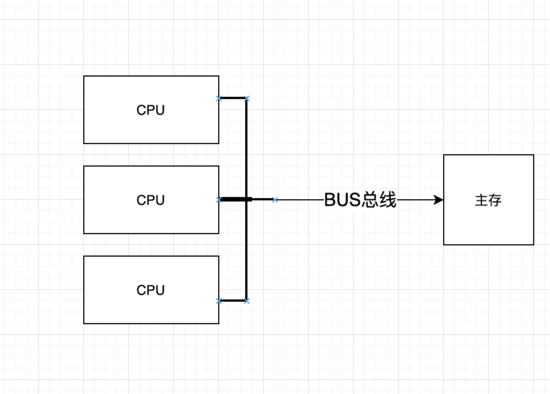
锁总线的方式。总线锁会锁住bus总线,使得其他CPU不能访问内存中的其他地址,因而效率极低。CPU的共享内存都是通过
-
MESI(英特尔CPU) 等等之类的缓存一致性协议,相对于总线锁的方式MESI的性能好很多。
- M: 被修改(Modified) 当一个值被加载到一个CPU内存中,同时这个CPU修改了这个值,则用Modified来表示,以为着在未来某个时刻会将这个值写入进主存。
- E: 独享的(Exclusive) 只有当前的CPU才能加载这个数据,就属于Exclusive独享的值。
- S: 共享的(Shared) 当多个CPU读取了同一个值,则用Shared来表示。
- I: 无效的(Invalid) 当前CPU读取的值已经被修改过了,则这个值是无效的用Invalid表示,以为这未来某个时刻会从主存中读取这个值。
-
在特定情况下CPU会进行指令重排,以保证高效的执行。CPU如何保证特定的情况下不不乱序执行。通过内存屏障来保证指令的有序性。
下面是三种CPU指令内存屏障指令。
-
sfence:在sfence指令前的写操作必须在sfence后写操作完成之前完成操作。即在两次写操作之间加个屏障使其不能被重排。
-
lfence:在lfence指令前的读操作必须在lfence后的读操作完成之前完成操作。即在两次读操作之间加个屏障使其不能被重排。
-
mfence:在mfence指令前的读写操作必须在mfence的读写操作完成之前完成操作。即在一次读一次写和另一次读和一次写之间加一个屏障使其不能被重排。
CPU保证有序执行除了可以使用mfence,还可以使用
jvm内存屏障,对上面的CPU内存屏障进行组合,有如下四种屏障
- loadload屏障,对于这样的语句Load1; LoadLoad; Load2, 在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
- storestore屏障,对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
- loadstore屏障,对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
- storeload屏障,对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
-
Runtime Data Area and Instruction Set
jvms 2.4 2.5
指令集分类
- 基于寄存器的指令集
- 基于栈的指令集 Hotspot中的Local Variable Table = JVM中的寄存器
Runtime Data Area
PC 程序计数器 Program Counter
Each Java Virtual Machine thread has its own pc (program counter) register.
每个Java虚拟机线程都有自己的程序计数器的存储空间。
At any point, each Java Virtual Machine thread is executing the code of a single method, namely the current method for that thread.
在任何时候,每个Java虚拟机线程都在执行单个方法的代码,即该线程的当前方法。
If that method is not native , the pc register contains the address of the Java Virtual Machine instruction currently being executed.
如果该方法不是本机方法,则pc寄存器包含当前正在执行的Java虚拟机指令的地址。
存放指令位置
虚拟机的运行,类似于这样的循环:
取PC中的位置,找到对应位置的指令;
执行该指令;
PC ++;
复制代码
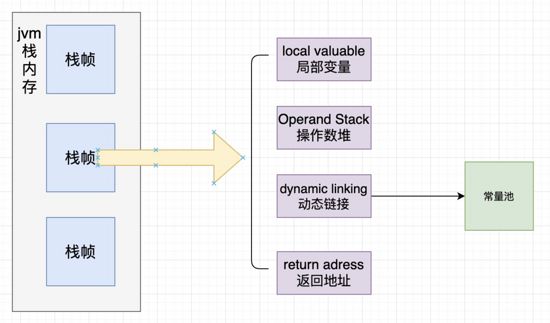
JVM Stack
Each Java Virtual Machine thread has a private Java Virtual Machine stack, created at the same time as the thread.
每个Java虚拟机线程都有一个私有Java虚拟机堆栈,与该线程同时创建。
A Java Virtual Machine stack stores frames
每个Java虚拟机存储的都是栈帧
- Frame - 每个方法对应一个栈帧
- Local Variable Table 局部变量
- Operand Stack 操作数堆 当一个方法刚刚开始执行时,其操作数栈是空的,随着方法执行和字节码指令的执行,会从局部变量表或对象实例的字段中复制常量或变量写入到操作数栈,再随着计算的进行将栈中元素出栈到局部变量表或者返回给方法调用者,也就是出栈/入栈操作。一个完整的方法执行期间往往包含多个这样出栈/入栈的过程。
- Dynamic Linking 动态链接 所谓动态链接就是指向运行时常量池的那个链接,然后看看指向的那个链接有没有解析,如果已经解析直接拿过来使用,没有解析尝试进行解析。表明这个方式叫什么,什么类型等等信息。比如在a()方法中调用了一个b()方法,在a的应用肯定有个b()但是b的具体内容在哪里是dynamic linking去获取。
- return address a() -> b(),方法a调用了方法b, b方法的返回值放在什么地方
Heap
The Java Virtual Machine has a heap that is shared among all Java Virtual Machine threads.
java 虚拟机有个所有线程共享的堆内存。
The heap is the run-time data area from which memory for all class instances and arrays is allocated.
堆是运行时数据区,从中分配所有类实例和数组的内存。
Method Area
The Java Virtual Machine has a method area that is shared among all Java Virtual Machine threads.
Java虚拟机具有一个在所有Java虚拟机线程之间共享的方法区域。
It stores per-class structures
存储每个类的结构
- Perm Space (<1.8) 字符串常量位于PermSpace FGC不会清理 大小启动的时候指定,不能变
- Meta Space (>=1.8) 字符串常量位于堆 会触发FGC清理 不设定的话,最大就是物理内存
Runtime Constant Pool
A run-time constant pool is a per-class or per-interface run-time representation of the constant_ pool table ina class file
Native Method Stack
An implementation of the Java Virtual Machine may use conventional stacks called native method stacks
Direct Memory
JVM可以直接访问的内核空间的内存 (OS 管理的内存)
NIO , 提高效率,实现zero copy
上面的内容总结起来就是下面这张图
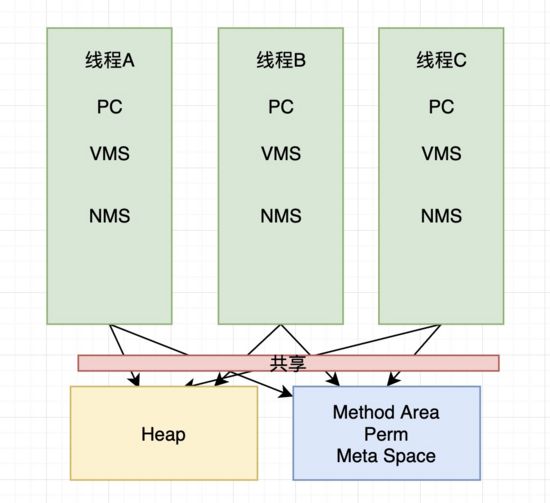
每个线程都有自己的栈内存,里面存放的是栈帧,如果有调用native方法就还存在native method stack,还有自己program counter程序计数器,用来记录每条指令的执行,当CPU切换线程的时候方便知道之前线程执行到哪条指令,所有线程共享堆内存和方法区,方法区有两种实现,在jdk8之前方法区叫PermGen永久代,jdk8及其以后的版本都叫Meta Space 元数据区。
栈帧:A frame is used to store data and partial results, as well as to perform dynamic linking, return values for methods, and dispatch exceptions.
栈帧是用来存储数据部分结果,和执行动态链接,返回方法的值和处理异常调度。
我们看一下一个简单的方法的执行过程的栈帧是怎么样的。
pubilc class Test1{
pubilc static void main(String [] args){
Test h = new Test();
h.m1();
}
}
pubilc class Test{
public void m1(){
int i = 200;
}
}
复制代码
编译后的Test1字节码为:
0 new #2
3 dup
4 invokespcial #3
7 istore_1
8 iload_1
9 invokespcial #3
12 return
复制代码
对应Test字节码为:
0 ipush 200
3 istore_1
4 return
复制代码
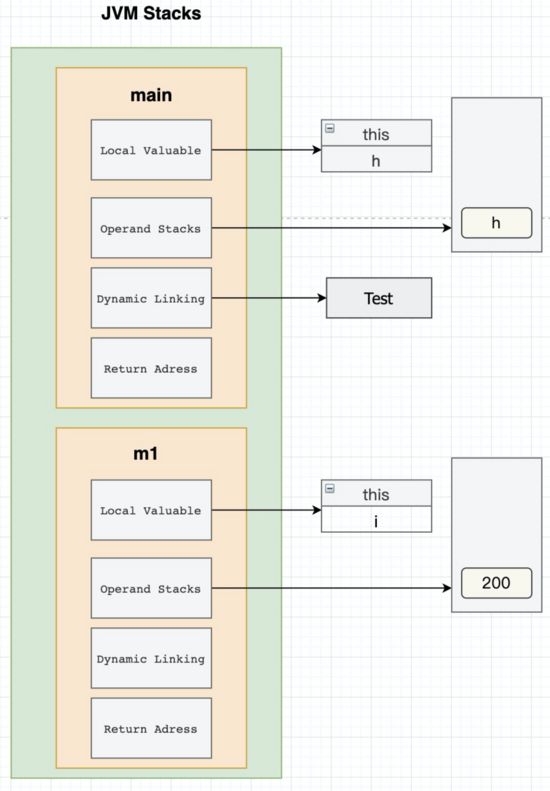
我我们看一下执行过程,在含有主方法的字节码中,首先执行一个new指令。new一个对象的话,包括三个操作:
- 首先开辟一个内存空间放在栈帧中,此时就包含了一个Dynamic Linking 动态链接的过程要把 Test h = new Test()中的Test类对应成这个类内存地址;
- 然后给这个对象的成员变量付出初始值(不是默认值);
- 最后初始化给成员变量一个默认值(init)。
我们看上面指令,在这条 invokespcial #3