
版权声明:本文为 cdeveloper 原创文章,可以随意转载,但必须在明确位置注明出处!
前言
这篇文章主要介绍 Linux 系统中进程控制相关的 API,包括创建,执行,终止等操作。基本的进程相关的概念在上一篇文章中已经介绍过了,不太熟悉的可以再回去了解了解。
进程标识
每个进程都有一个非负整数表示的唯一的进程 ID,因为进程 ID 标识符总是唯一的,所以常常把 ID 作为其他标识符的一部分用来保证唯一性,并且进程的 ID 也是可以复用的,当一个进程终止后,其进程 ID 就可能被其他刚创建的进程所使用。
Linux 系统提供了一些获取进程 ID 的函数:
#include
#include
// 得到当前进程 ID
pid_t getpid(void);
// 得到父进程 ID
pid_t getppid(void);
这两个函数比较简单,就是直接调用然后输出即可,可以自己尝试输出试试。
进程的 system 接口
我们在 Windows 下有 system 接口可以使用,例如打开记事本:
system("notepad");
同样在 Linux 下也有这个接口,可以执行相关的程序:
#include
// 调用 fork 函数执行 command 命令
int system(const char *command);
例如,使用 system 接口来执行 ls 命令:
#include
#include
int main() {
// 调用 ls
system("ls");
return 0;
}
system 接口底层其实还是使用系统调用 fork,exec,waitpid 来执行程序,只是在上层又封装了一次。
创建进程 fork
fork 的定义
在 Linux 中,我们使用 fork 来创建一个子进程:
#include
pid_t fork(void);
fork 的返回值
fork 函数有些特殊,成功它返回 2 次,失败返回 -1,利用这个特性可以判断当前的进程是子进程还是父进程:
- 在子进程中返回 0
- 在父进程中返回子进程的进程 ID
// test_fork1.c
#include
#include
int main() {
pid_t pid = fork();
if (-1 == pid)
perror("fork fail");
else if (0 == pid) // 子进程返回 0
printf("I'm child process: %d\n", getpid());
else // 父进程返回子进程 PID
printf("I'm parent process,fork return is: %d\n", pid);
return 0;
}
我们编译运行看看效果:
# 编译
gcc test_fork1.c -o test_fork1
# 运行
./test_fork1
I'm parent process,fork return is: 12557
I'm child process: 12557
可以看到父进程的返回值是子进程的 PID:12557,子进程的 PID 正是 12557,这也验证了 fork 的返回值的特点。
fork 的写时复制技术
通过执行 fork,子进程得到父进程的一个副本,例如子进程获得父进程的数据空间,堆和栈的副本,但是它们并不共享存储空间,它们只共享代码段。但是在现在的系统实现中,并不执行拷贝父进程的副本,作为替代方案,而是使用写时复制(Copy - On - Write)技术。
写时复制:在 fork 之后,这些区域由父子进程共享,而且内核将它们的访问权限改变为只读,如果父子进程中的任何一个试图修改这些区域,内核只为修改区域的那片内存制作一个副本给子进程。
不管是哪种技术实现,最后父子进程的数据都是独立的,不会相互影响,我们来看一个实际的例子:
// test_fork2.c
#include
#include
int main() {
int count = 0;
// 创建子进程
pid_t pid = fork();
// 父子进程中都有这个变量
count++;
if (-1 == pid)
perror("fork fail");
else if (0 == pid) // 子进程 count 变量
printf("child process count: %d\n", count);
else // 父进程 count 变量
printf("parent process count: %d\n", count);
return 0;
}
编译运行:
# 编译
gcc test_fork2.c -o test_fork2
# 运行
./test_fork2
parent process count: 1
child process count: 1
结果是父子进程中的 count = 1,如果父子进程的 count 不独立的话,子进程的 count 应该等于 2,但是实际上是等于 1,说明父子进程的数据是独立的。
子进程的执行位置
fork 还有一个特点:子进程不是从 main 函数开始执行的,而是从 fork 返回的地方开始,我们来看个实际的例子:
// test_fork3.c
#include
#include
#include
int main(void) {
int ret_from_fork = 0;
int mypid = getpid();
printf("Before: my pid is %d\n", mypid);
// 创建子进程,子进程从这里返回
ret_from_fork = fork();
sleep(1);
printf("After: my pid is %d, fork() said %d\n", getpid(), ret_from_fork);
return 0;
}
编译运行结果:
# 编译
gcc test_fork3.c -o test_fork3
# 运行
./test_fork3
Before: my pid is 9670
After: my pid is 9670, fork() said 9671
After: my pid is 9671, fork() said 0
看到只打印一个 Before 信息,没有打印 2 个 Before 原因是:内核通过复制父进程 9670 来创建子进程 9671,并将父进程 9670 代码和当前运行到的位置都复制到子进程 9671,所以新的子进程 9671 从 fork 返回的地方开始运行,而不是从头开始,也就不会打印开头的 Before 了。
创建进程 vfork
还有一个创建进程的系统调用 vfork,它跟 fork 很相似,但是也有几点不同:
- vfork 的目的是创建一个子进程来运行一个程序
- vfork 并不复制父进程地址空间,子进程在父进程地址空间中运行,并阻塞父进程直到子进程返回
- vfork 保证子进程先运行
- 子进程需要调用 exec 或 exit 函数退出,否则会带来未知结果。
来看个实际的例子:
// test_vfork.c
#include
#include
#include
int main() {
int count = 0;
pid_t pid = vfork();
count++;
if (-1 == pid) {
perror("fork fail");
} else if (0 == pid) {
printf("child process count : %d\n", count);
exit(0);
} else {
// 父进程会阻塞
printf("parent process count: %d\n", count);
}
return 0;
}
编译运行:
# 编译
gcc test_vfork.c -o test_vfork
# 运行
./test_vfork
child process count: 1
parent process count: 2
这个结果跟前面使用 fork 的例子是不同的,使用 vfork 先打印的子进程信息,再打印父进程的信息,是因为父进程被阻塞了,直到子进程执行完了才有机会执行。并且由于子进程在父进程的地址空间中运行,所以子进程中对 count 加一的操作对父进程也是有效的,因此最后父进程的 count = 2。
exec
fork 函数里面最后也是调用 exec 等函数来执行程序的,我们有必须要了解这个函数:
#include
// path:程序名称,argv:运行参数
int execv(const char *path, char *const argv[]);
exec 有很多变种函数,例如 execlp,execle,等等,但基本的用法都是差不多的,这里就以 execl 为例来看个程序:
#include
#include
int main() {
char* argvs[] = {"ps", "-ef", NULL};
execv("ps", argvs);
return 0;
}
运行结果就相当与 shell 命令:ps - ef,其他的变种函数可以通过 man exec 来查看。
进程等待 wait
父进程可以使用 wait 系统调用主动等待子进程或者指定进程结束,并获得子进程的结束信息:
#include
#include
// 等待子进程结束
pid_t wait(int *wstatus);
// 等待指定的 PID 进程结束
pid_t waitpid(pid_t pid, int *wstatus, int options);
这个系统调用的过程如下:
- wait 暂停调用它的进程直到子进程结束
- wait 调用成功返回子进程的 PID
- wstatus 存储子进程的返回信息(正常退出,异常退出,被信号杀死),以此来知道子进程是如何结束的
大致的流程如下:
F ---fork------> F -------- wait ----> F ------------->
| |
| |
| |
-------> C -------------exit() -
来看看 wait 是如何使用的:
// test_wait.c
#include
#include
#include
#include
int main() {
int status = 0;
pid_t pid = fork();
if (0 == pid) {
printf("child process\n");
sleep(3);
// 父进程会得到 exit 的退出状态码
exit(0);
} else if(pid > 0) {
// 等待子进程返回,wait 运行成功返回子进程 PID
if (pid == wait(&status))
printf("child has run ok status = %d, parent processing...\n", status);
}
return 0;
}
编译运行:
# 编译
gcc test_wait.c -o test_wait
# 运行
./test_wait
child process
child has run ok status = 0, parent processing...
可以看到父进程成功等待了子进程 3 s,并得到了存储在 status 中的返回值,这个 status 有 2 种状态:
- 如果子进程调用 exit 退出,那么内核将 exit 的退出状态码放在 status 中
- 如果进程被杀死,内核将信号序列放在 status 中
实际使用时,wait 提供了相关的宏来判断 status 的状态,详情参考 man wait。另外 waitpid 与 wait 几乎的相同的,作为锻炼,就留给你自己去学习吧,参考 man waitpid。
进程结束
既然能够创建进程,那肯定能够结束进程,在 Linux 中进程退出又分为正常和异常退出,分别来了解了解。
正常退出
有 5 种正常退出进程的方法:
- 在 main 内执行
return,等价于调用 exit - 调用
exit - 调用
_exit或_Exit - 进程的最后一个线程在其启动例程中执行 return 语句
- 进程的最后一个线程调用
pthread_exit函数
异常终止
有 3 种异常终止的方法:
- 调用
abort,产生SIGABRT信号 - 当进程接受到某些信号时
- 最后一个线程对「取消」请求作出响应
不管是哪种终止情况,我们都可以使用 wait 或者 waitpid 来得到子进程的退出状态。
拓展:在 Linux 内核中查看 fork 执行流程
为了加深对 Linux 进程的理解,下面就来简单了解下 fork 在内核中的具体调用过程。建议你用源码查看工具来跟踪源码,我使用的是 Linux-2.6 的源码,要跟踪的文件是 kernel/fork.c,创建进程的总体过程如下图所示:

总体的流程是创建一个新的任务(task_struct),然后拷贝相关的进程信息,最后唤醒这个进程和后续的准备工作,其中最重要的是 copy_process 这个函数,来看看它的具体执行过程:
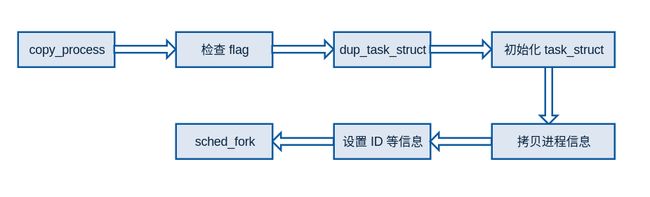
主要的流程就是先使用 dup_task_struct 复制一个进程结构,然后初始化这个进程信息,再拷贝父进程的相关信息,最后 sched_fork 调度进程。
整个过程大体上就是这样,具体的细节有兴趣可以深入的跟踪,这里就介绍这些了。
结语
本次我们学习了 Linux 中非常重要的进程控制,其中非常重要的是 fork 这个函数,因为我们就是用这个函数来创建进程的,另外我们也在内核中分析了 fork 的具体实现过程,希望通过这篇文章能够让你对 Linux 的进程有一个更加完整的了解和学习,希望你能认真实践。
最后,感谢你的阅读,我们下次再见 :)