模拟测试数据的生成方法
阅读原文链接: http://c.raqsoft.com.cn/article/1542086018243?r=alice
应用系统或软件产品一般都需要进行不同阶段的验证工作,包括原型功能论证、功能测试、性能测试等,这些测试、论证场景都可能涉及到测试数据的准备。测试数据有时可以直接复用历史数据,但很多情况下,基于历史数据建立的测试数据可能会出现内容缺失不全、数据量级不够、数据涉密不能导出、数据已加密无法参与计算等情况,这时就需要根据用户的业务需求、数据预置约束条件、数据间层级关联等条件,生成对应的模拟验证数据。一般来说,按照用户要求模拟数据应该做到:数据量可控、充分的随机性、保持数据间特定的逻辑关联关系(包括直接关联或隐含关联)。
单数据表是最常见的数据模拟情况,这种表由主键和普通字段组成,也可以由无主键的普通字段组成。在单数据表的基础上,可以进一步进行多数据表的关联模拟,关联关系可以归类分为:外键关联、同维关联、主子关联。对于关联数据生成的原则具体可参见《怎样生成有关联的测试数据》一文。对于已经生成的数据,则可以参考《优化 Join运算的系列方法》对模拟生成的数据进行更进一步地深入查询和分析处理。
一般来说,单数据表模拟数据的难点是对数据表字段内容的灵活生成。而多数据表模拟则是在此基础上考虑关联关系(一层或多层)的生成,尤其是需要保证多数据表在进行关联过滤之后,还能够有充足、有效的结果数据,从而满足数据的关联运算或是其它展现需求。实际情况中,通过编程生成这些模拟验证数据的难点通常是数据间复杂的逻辑关联关系。
本文中,我们将介绍一个方便、灵活的模拟数据生成工具——集算器。集算器是一款面向应用程序员和数据分析员,专注于结构化数据分析与处理的快速开发工具,是一套基于 Java 解释执行的动态语言,采用了先进的计算模型和设计思想,让开发更易于实现、性能更好。同时,集算器还具备完备的类库和轻量级架构,足以让数据模拟生成更加灵活和高效。
集算器具有跨平台、无框架、易部署的特点,仅需要安装有JAVA虚拟机的操作系统即可,特别是对于数据模拟生成的过程,可以随时分步调试查看中间过程数据。
集算器使用SPL程序语言。SPL(Structured Process Language)是一种面向(半)结构化数据计算的程序设计语言,能够满足复杂处理和过程计算的数据处理需求。
同时,集算器还可以直接将模拟生成的数据落地在本地磁盘的二进制“集文件”(集算器自定义的一种文件格式)中,免去繁琐的安装数据库的操作,这也符合模拟测试相对临时性的工作特点。集文件本身具有使用简单、可追加、支持大数据、可分段并行等特点,而且很容易转成其它格式,如数据库、文本等。当然,集算器自身也支持直接或通过集文件将模拟数据导入到任意目标数据库中,所需的具体外部库的使用可以参见《外部库》函数参考章节。
为了方便叙述和验证,本文默认模拟生成的数据均落地在本地集文件中。
1、 为什么使用集文件?
在用集算器生成模拟数据时,常用两种文件格式:文本文件和集文件。
文本是各种数据平台 / 数据库都支持的文件格式,具有良好的通用性。但文本文件的查询性能较差,占用磁盘空间也较大,而且缺少字段的数据类型定义,有时可能会出现“类型歧义”的错误。
针对这些问题,集算器设计了一种二进制格式文件,称为集文件(文件后缀 btx)。集文件中使用了低 CPU 消耗的压缩编码,数据存储时较文本文件占用磁盘空间更小,具有较高的查询性能,并且字段的数据类型也被存储,避免出现类型歧义。同时,集文件继承了文本文件支持大数据量、可追加和易于分段并行的特点。因此,在需要使用数据文件时,集文件是更好的选择。
2、 如何使用集文件?
利用集文件存储模拟生成的数据,因为其具有与其它数据格式广泛的互通性,后续就可以灵活进行与目标数据源的双向转化,包括 Oracle、DB2、MS SQL、MySQL、PG 等关系型数据库和 TXT/CSV、JSON/XML、EXCEL 等文件类型。
下面首先针对常用的文本文件、MySQL进行双向互转的说明。
1) 集文件与文本文件互转
集文件可以与文本文件进行互相转换,相应的SPL实现脚本示例如下:
| A | B | |
| 1 | =file("文本.txt").cursor@t() | /导入文本数据 |
| 2 | >file("文本转集文件.btx").export@ab(A1) | /导出为集文件 |
| 3 | =file("集文件.btx").cursor@b() | /导入集文件 |
| 4 | >file("集文件转文本数据.txt").export@at(A3) | /导出为文本 |
A1:导入文本文件数据。使用cursor@t()游标方式读入“文本.txt”文件数据,其中 @t 指定将第一行记录作为字段名,如果不使用 @t 选项就会以_1,_2,…作为字段名。
A2:使用循环函数,将文本数据循环追加到集文件中。使用export@ab()将文本数据导出到集文件中,其中,@a 表示追加写数据到集文件, 如果不用 @a 就表示重建集文件,@b 表示导出为集文件。
在集算器中可以直接查看生成的“文本转集文件.btx”文件数据结果,如下图所示:
A3:导入集文件数据。使用cursor@b()游标方式读入“集文件.btx”,其中 @b 表示将导入的是集文件。
A4:使用循环函数,将集文件数据循环追加到文本文件中。export@t()将指定单元格的数据导出到文本文件中,其中,@a 表示追加写数据到文本文件中, 不用 @a 则表示重建文本文件,@t表示将集文件的字段名作为第一条记录写入文本文件。
查看生成的“集文件转文本数据.txt”文本文件数据结果,如下图所示:

2) 集文件与 MySQL 互转
集文件也可以与MySQL之间进行数据互转,相应的SPL脚本也很简单。下例将MySQL数据库employeeinfo表中的数据导出到集文件中:
| A | B | |
| 1 | =connect("MySQL") | /连接 MySQL 数据源 |
| 2 | =A1.cursor("select * from employeeinfo") | /游标读取 MySQL 中 employeeinfo 表数据 |
| 3 | >file("MySQL集文件.btx").export@az(A2) | /循环游标将 MySQL 数据导入到集文件中 |
| 4 | >A1.close() | /关闭数据库连接 |
A1:连接 MySQL 数据源,使用connect()进行 MySQL 数据库的连接。如果用鼠标点击 A1 单元格,可以直接查看 MySQL 数据库的连接信息。具体查看数据库配置教程相关章节文档的配置说明。
A2:游标读取 MySQL 中 employeeinfo 表数据。
A3:使用循环函数,将 A2读出的数据循环追加到集文件中。使用export@az()将文本数据导出到集文件中,其中,@a 表示追加写数据到集文件中, 如果不用 @a 则表示重建集文件,@z是将数据强制导出集文件,注意,这里用了 @z 而不是前面的 @b,事实上 @z 会强制导出集文件(和 @b 效果一样),同时还可以通过表达式 export@z(A2;s) 增加 s 选项作为分组表达式,s对于文本文件为自选分隔符, 缺省默认分隔符是 tab,有 s 参数时认为 A2 文本数据对 s 有序,仅在 s 变化时才分段,这种设置分段的集文件用于并行数据量大时的分段导出, 导出时同一段的记录不会被拆开。缺省情况下不分段导出“文本转集文件.btx”集文件。
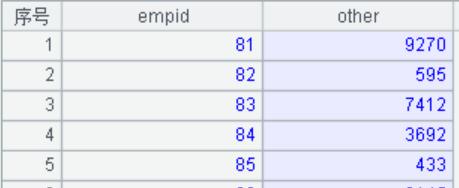
同样,在集算器中可以直接查看生成的“MySQL集文件.btx”文件数据结果,如下图所示:
A4:使用close()函数关闭 A1 建立起的 MySQL 数据源连接。
下例则是将集文件中的数据插入到MySQL数据库employeeinfo表中:
| A | B | |
| 1 | =connect("MySQL") |
/连接MySQL数据源 |
| 2 | =file("集文件.btx").cursor@b() | /游标导入集文件数据 |
| 3 | =A1.update(A2,employeeinfo,empid,other;empid) |
/执行update更新 |
| 4 | >A1.close() |
/关闭数据库连接 |
A1:连接 MySQL 数据源。使用connect()进行 MySQL 数据库的连接。如果用鼠标点击 A1 单元格,可以直接查看 MySQL 数据库的连接信息。具体查看数据库配置教程相关章节文档的配置说明。
A2:游标方式导入集文件的数据。集文件数据使用cursor@b()将以游标方式读取,其中包含数据表字段:empid 和 other。
A3:更新 MySQL 数据库“employeeinfo”库表中的数据。使用update()将单元格 A2 通过游标读取的集文件数据更新到 MySQL 数据库“employeeinfo”库表中。
A4:使用close()函数关闭 A1 建立起的 MySQL 数据源连接。
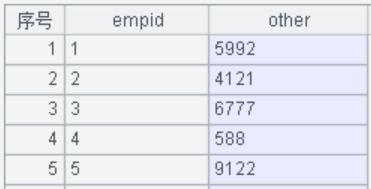
使用第三方工具查看 MySQL 数据库的“employeeinfo”库表,插入的数据结果如下截图所示:

二、 模拟生成字段数据
在开始单数据表模拟之前,我们先了解一下通过SPL脚本处理主键字段和普通字段的方法。
具体的方法参考原文链接:http://c.raqsoft.com.cn/article/1542086018243?r=alice