VPS-SLAM: Visual Planar Semantic SLAM for Aerial Robotic Systems
VPS-SLAM: Visual Planar Semantic SLAM for Aerial Robotic Systems
ABSTRACT:室内环境中存在大量的高级语义信息,这些信息可以为机器人提供更好的环境理解,从而提高其估计误差的不确定性。虽然语义信息已经被证明是有用的,但是研究社区在准确地感知、提取和利用环境中的语义信息方面面临着一些挑战。为了解决这些挑战,在本文中,我们提出了一个轻量级的实时可视化语义SLAM框架,运行在空中机器人平台上。这种新方法将低级视觉/视觉惯性测程(VO/VIO)与从检测到的语义对象中提取的平面对应几何信息相结合。从选择的语义对象中提取平面提供了增强的鲁棒性,并使快速精确地改进度量估计成为可能,同时不考虑其形状和大小而将其推广到多个对象实例。我们基于图形的方法可以集成几种最先进的VO/VIO算法以及最先进的对象检测器,以便估计机器人完整的6自由度姿态,同时创建环境的稀疏语义地图。与其他作品相比,这是一个显著的优点。我们在一个标准RGB-D数据集上测试我们的方法,并将其性能与先进的SLAM算法进行比较。我们还进行了几个具有挑战性的室内实验,以验证我们在不同环境条件下的方法,并进一步在一个空中机器人上进行测试。
INDEX TERMS:SLAM, visual SLAM, visual semantic SLAM, autonomous aerial robots, UAVs.
I. INTRODUCTION
许多与不同应用相关的室内自主任务需要使用小型空中机器人,能够在狭窄的受限空间中导航。这种车辆不能承载很大的重量,只能配备光传感器,如RGB或RGB-d摄像头,以及计算资源有限的处理单元。要实现真正自主的操作,需要精确的定位和有意义的映射结果,这确实是一个具有挑战性的问题,尤其是在鲁棒性方面。
使用视觉传感器的同步定位和建图(SLAM)可能是基于特征(稀疏、半稠密或稠密)或基于强度的。大多数半稠密SLAM技术,像[1]-[3],依靠低水平等环境特征点,线和平面。在光照变化和重复模式出现的情况下,这种方法的性能通常会下降。另一方面,其他国家基于SLAM基础的技术,如[4]-[6],专注于稠密的3d环境的映射,因此要求高端CPU和GPU硬件为了实现实时操作,这是一个明确的限制较低的空中机器人的计算能力。
最近在计算机视觉算法方面的改进已经使得在低端cpu或gpu上实时运行基于对象的检测器成为可能。将这种检测器与依赖于低级特性的视觉测程(VO)/视觉惯性测程(VIO)系统结合使用,可以提高数据关联的准确性,并在不需要高计算要求的情况下提供更健壮的循环闭包,如[7]、[8]所示。虽然在SLAM系统中添加语义信息无疑提供了额外的知识,但是提取语义对象的准确三维位置是一个具有挑战性且意义重大的问题,因为位置估计中的误差会导致语义对象的数据关联和映射出现误差。语义对象三维位置估计的不准确主要是由两个因素造成的;(1)不同语义对象类实例的三维结构不均匀且复杂。(2)语义对象检测错误等物体探测器提供的bounding box不能准确地贴合被检测物体周围。
在常见的室内环境中,一些物体呈现出垂直和/或水平的平面,可以通过提取这些平面来提高这些物体的相对位置估计。因此,为了克服上述限制,并实现一个健壮的轻量级SLAM算法,我们提出了一种语义SLAM方法,在语义检测范围内使用平面对象。
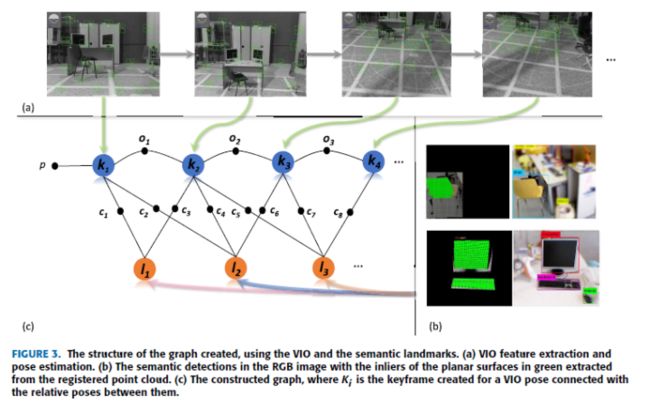
该算法可分为两部分。在第一部分中,使用VO/VIO估计来传播机器人状态。这个阶段使用环境中的底层特性来传播机器人状态。由于低水平特征检测和匹配中的不准确性,以及IMU测量中的误差和偏差(针对VIO系统),VO/VIO对机器人状态的估计常常会随着时间积累误差。我们通过将检测到的语义对象的高级平面与之前映射的语义平面相关联来解决这个问题。为了提取检测区域内的平面表面,将目前最先进的物体检测器提供的输出与精心应用的平面提取技术相结合。因此,算法的第二部分对估计进行了修正,并建立了从语义检测中提取的平面稀疏语义映射。
创建的语义映射由平面、类标签和平面类型(即水平或垂直)组成,它们由中心和法线方向表示,可以通过对语义对象的新检测来增强。综上所述,本文工作的主要贡献如下:
1、健壮、轻量级的语义SLAM算法,适合在空中机器人上运行。
2、在语义检测中加入快速平面提取,实现了精确的高水平数据关联和语义地标的映射。
本文档的其余部分组织如下:解释了几何和语义SLAM的艺术现状。第三节解释了语义检测和平面提取部分,第四节描述了使用VO/VIO测量值和提取的语义信息创建图形的过程。第五节介绍了使用标准数据集进行的实验和获得的结果,以及使用额外的现场实验,比较了我们的方法与几种先进的几何和语义SLAM方法的准确性。最后,第六节讨论得到的结果,第七节给出最后的结论。
II. RELATED WORK
研究社区已经见证了对基于视觉SLAM的算法应用于机器人的极大兴趣,因此有大量的视觉SLAM相关文献。近年来,结合几何信息和语义信息的SLAM技术得到了广泛的应用,具有重要的相关性。现在人们普遍认识到,为精确的数据关联和循环闭包合并对象级信息可以提高解决方案[10]-[12]的质量、健壮性和可解释性。
salads-moreno等人[13]提出了这个方向的首批工作之一:一个名为SLAMCC的实时语义SLAM方法。SLAMCC是为RGB-D传感器开发的,它将ICP算法应用于3D摄像机的姿态跟踪,并将估计值添加到姿态图中。然后将之前存储在数据库中的语义对象估计出的相对3D姿态进行整合,以共同优化所有姿态。Murali等人[14]提出了一种将语义信息集成到视觉SLAM系统中的方法。在门控因子图框架内,使用语义信息检测系统的inliers/outliers,以实现动态障碍的鲁棒性能。一个预先训练的基于深度学习的对象检测器提供对象的语义信息。Sunderhauf等[15]提出了一种将ORB-SLAM2[1]与基于深度学习的物体探测器以及对物体探测的平面信息进行三维无监督分割相结合的语义映射方法。我们建议的方法类似于这种方法,除了作者只提供语义映射框架,而不是一个完整的大满贯框架——他们执行耗时的数据关联使用欧几里德距离的3d点检测object-landmark对,而不是更准确的使用界标协方差的马氏距离。
Parkhiya等人提出了一种单目语义SLAM方法。他们使用深度网络从特定类别的物体(如椅子)中学习二维特征特征,并将其与三维CAD模型匹配,以估计语义对象的相对三维姿态。将这些语义对象与机器人的VO估计位姿一起添加到图优化框架中作为地标,得到机器人的修正度规位姿。
Grinvald等人[17]提出了一种基于从几何VIO传感器获取的位姿的语义映射系统。该方法利用点云数据的几何平面分割,在数据关联步骤中使用语义检测,进一步细化分割。McCormac等人[18]使用名为FusionCC的RBG-D摄像机提供了一个对象级SLAM系统,使用Mask-RCNN对象检测器对对象的截断签名距离函数(TSDF)表示进行分段。目标用于跟踪、重新定位和循环闭合,并对所提取的姿态图进行优化。Bowman等人[8]对他们之前的工作[7]进行了扩展,从而在语义SLAM方法中使用了诸如椅子和门等语义对象。将联合度量语义SLAM问题分解为连续的位姿优化问题和离散的语义数据关联和语义标签优化问题。该框架将惯性信息、几何信息和语义信息紧密结合在一起。Atanasov等人[19]对[8]提出的框架进行了扩展,利用卷积神经网络从汽车等语义对象中提取描述性语义特征,使其与几何信息和惯性信息紧密耦合。
最新的一篇关于语义风暴[10]的文章提出,在一个针对城市驾驶环境的健壮的框架中,对数据关联的不同可能假设进行追踪。也是在最近,Yang等人[12]提出了一个统一的SLAM框架,包括高层对象和基于单目信息的平面。它们不需要以前的模型,并且合并了一个非常新颖的、通用的对象到平面约束。除了没有考虑深度信息之外,与我们的方法的一个显著区别是,这项工作使用2D边框来表示对象。其他创新的方法集中在SLAM框架本身[11]中对3D激光雷达数据进行点语义标记。这项工作也强调了城市场景下的自动驾驶作为一个重要的应用领域。
我们建议的方法的目的是向快速、高效提取物体的平面表面,可以用作语义特征,从而推广了一些具有平面表面的语义对象,创建环境的一个稀疏优化图,需要最少的计算资源,因此能以较低的计算资源运行在空中机器人平台。图2给出了系统的总体概况,其不同的组成部分将在下面的章节中解释。

III. SEMANTICS BASED PLANAR EXTRACTION
A. SEMANTIC OBJECT DETECTION
语义对象检测可以使用任何状态的基于对象的检测器来执行。我们选择“你只看一次”(YOLOv2)([20])目标检测器,以满足空中机器人的机载计算限制。我们选择在COCO dataset([21])上训练的轻量级的Tiny-YOLOv2模型([21]),在GPU平均消耗为300 mb的情况下提供实时性能,对对象检测器进行了修改,只检测超过一定概率阈值的相关对象。
虽然Tiny-YOLO不需要高计算量,但它需要一台支持GPU的车载计算机。因此,为了在没有GPU支持的情况下在机载机器人上测试我们的方法,我们还利用了基于CPU的基于形状和颜色的物体检测器的实现,它能够实时检测蓝色和红色的立方体物体。检测器首先对HSV色空间中的基于颜色的信息进行处理,从而过滤出基于颜色的目标。然后使用形状图像处理器对滤波后的图像进行处理,该处理器考虑到对应目标的近似形状,从而检测出具有相应颜色的立方体形状目标。更多关于检测器的细节可以在[22]中找到。对从RGB相机接收到的图像进行目标检测。然后将从对象检测器检测到的bounding box提供给对象分割(III-B)将与RGB图像匹配的深度图像生成的三维点云分割成平面信息。
B.语义对象分割
从RGB图像中提取第三- a段接收到的语义对象的bounding box,用于提取语义对象的相关三维点云数据。这个三维点云是由与RGB图像匹配的相应深度图像生成的。如图7c所示,从检测器接收到的bounding box可能会有错误,因为bounding box不能很好地贴合物体。采用[8]中所示的特征三维点或检测到的bounding box内的所有三维点的中值,会导致语义对象相对三维位置的计算出现误差,从而导致语义数据的映射和数据关联出现误差。为了最小化错误语义的映射对象,启发从我们以前的平面聚类和分割方法([23],[24]),我们以下列方式分割了表面存在带有质心以及法线方向的检测bounding box的所有的水平和垂直平面:
1) NORMAL EXTRACTION
为了快速、实时地提取每个三维点的法线,我们采用了积分法线估计技术([25])。简单地说,该技术首先将输入的3D点云Ii的z分量转换为积分图像Im,因为在积分图像中,计算特定区域内所有值的总和,它使计算非常快速和高效。在进行平滑处理后,利用深度变化图选择合适的平滑区域,计算p点的法线np为:np = ph * pv。ph值是向量的3d点p的左右邻居和pv是向量的3d点p的顶部和底部的邻居。矩阵Ncp包含点云中每个3d点的法线方向,并传递给下面解释的质心提取步骤。
2) CENTROID EXTRACTION
为了快速和鲁棒地提取平面曲面和质心,我们使用[26]中提出的方法。该方法以前一步计算得到的Ncp以及所有对应的三维点向量作为输入。所有平面由平面方程ax+by +cz+d=0,因此每个三维点都表示为由欧几里得点及其法向量和nd组成的向量:
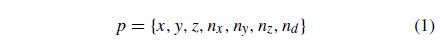
![]()
计算相邻点的法向欧几里得距离,以找到所有的连通分量。然后对计算得到的连通分量进行曲率检查,以过滤非平面分量。提取出所有具有质心和法线的平面后,首先检查平面是否为水平面:

其中np为提取出的平面的法线,ng为已知的地面平面的法线。如果dhor小于thor,则将平面np标记为水平面。如果dhor大于thor,则检查平面的垂直阈值为:
![]()
如果dvert小于tvert,则将平面分段np标记为垂直面。因此,提取的平面包含以下信息:

IV. GRAPH SLAM
在缺乏环境特征的情况下,根据VO/VIO算法进行的姿态估计会累积误差,从III-B语义检测中可以看出,由于遮挡、光照不足,会导致三维位置估计的不确定性。由于这些不确定性的存在,滤波技术的使用,如扩展卡尔曼滤波(EKF) SLAM可能导致在估计机器人和地标姿势的分歧。与只考虑机器人最近以前的状态的过滤技术相反,基于图slam的技术提供了考虑所有以前的机器人状态的优势,并解释了更高的非线性。因此,为了稳健地融合来自VO/VIO的测量结果和语义检测,我们使用基于图slam的优化。该算法可分为三个主要阶段:
A. VO/VIO ODOMETRY
使用松耦合方法将VO/VIO评估与语义数据融合的优点是可以进行集成,将几种最先进的VO/VIO系统集成到框架中,使用针对特定环境的最佳方法。在这项工作中,我们整合到我们的框架中三个不同的视觉测程算法,即:1. ROVIO ( [27]) 2. Snap VIO1 3. RTAB-map odometry ([28]).
ROVIO是一种基于扩展卡尔曼滤波(EKF)的单目VIO算法。ROVIO使用图像补丁的直接图像强度误差来实现鲁棒跟踪。在EKF的更新阶段,使用这些图像强度误差作为创新项。这些图像强度测量与IMU紧密结合,以准确估计机器人的姿态与真实的度量尺度。但是由于图像强度计算和IMU测量中的噪声,ROVIO提供的姿态估计会随着时间积累巨大的漂移,在许多情况下,姿态估计可能会发散而无法恢复。在非常高的角度运动的空中机器人和较少的特征的环境中,ROVIO估计的姿态可能会倾向于完全偏离真实的机器人姿态。由于这个限制,对于空中机器人上的高速战斗,我们使用snap VIO算法。snap VIO算法也是一种能够估计机器人姿态的单目方法,其中机器人的姿态估计随着时间漂移,但算法不会像ROVIO那样倾向于完全偏离其真实值。
为了将我们提出的方法与不提供同步IMU数据的标准RGB-D数据集([29])进行比较,我们使用了基于RTAB-map的RGB-D视觉测程模块。里程计算法采用特征映射(F2M)方法,利用前一个关键帧生成的特征局部映射注册一个新的关键帧。它利用好特征跟踪(GFTT)([30])提取关键点特征,并利用提取的特征的简要描述符与创建的局部地图的简要描述符进行匹配。运动估计采用OpenCV库([31])中提出的换位n点算法(Perspective-n-Point algorithm, PnP)进行。采用局部束平差的方法对测距估计值进行修正。
B. GRAPH CONSTRUCTION
机器人状态向量x = [xr;Rr]在关键帧k上传播,其中xr = [x;y;z), x;y和z是机器人沿x轴的位置估计;y轴和z轴分别相对于参考ew的世界框架(图1),Rr为机器人相对于世界框架的旋转矩阵。我们假设机器人的初始状态是已知的。
每个标志由其状态和与平面类型和类类型表示为L = L1的标签的协方差组成;::;Ln。式中,Li = (lzi;李;合作意向书;lci),lzi为第i个标志点的三维位置,li为第i个标志点与loi的协方差,lci为平面,为第i个标志点的类类型。
由VO/VIO组成的算法前端提供了世界参考框架w中的三维姿态估计。t时刻机器人状态xr的估计作为关键帧节点Kt添加到因子图中。利用相邻关键帧Kt-1和Kt之间的位姿增量ur (k),将它们之间的约束以边缘的形式相加,由VO/VIO在t-1和t时刻的位姿增量可得为:
![]()
xr (k - 1)和xr (k)分别为t - 1和t时刻接收到的位姿测量值。每个关键帧Ki根据时间和机器人的运动约束添加到因子图中。
每一个被检测到的语义对象Si在经过数据关联过程(IV-C节)后,被添加到因子图中作为一个地标节点来扩充语义地标的地图L,或者与当前映射的语义地标相关联。添加关键帧Ki中观察到的地标相对位姿作为地标与各自关键帧之间的约束。图3展示了利用n个关键帧和提取出的三个语义标志的平面检测到的图表面。
C. DATA ASSOCIATION
数据关联阶段首先通过以下方式接收section III-B中提取的语义平面:Si D fszi;sni;soi;sci g. Si是第一个检测和提取的语义平面i,包含szi和sni作为被检测平面的质心及其对应的法向(如图1所示)。soi和sci分别为平面类型和类标签。第一个接收到的语义对象不经过数据关联直接映射为第一个语义标记,可以表示为:
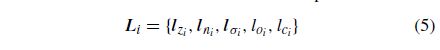
其中lzi和lni是世界参照系中语义地标的中心和法线,为:

其中wRc为从摄像机帧到世界帧的旋转矩阵。l 是估计的不确定性的位置语义,具有里程碑意义。l 的初始值是决定基于数量的3d点包含在平面表面。语义对象较低数量的3d点对应于高确定性的错误估计质心和正常的方向,将l更高。对第一个语义地标进行映射后,每个检测到的语义平面Sk进行以下三个步骤的数据关联过程:
首先,检测接收到的语义平面是否与语义标志的类标签匹配,其平面类型是否与语义标志的平面类型相等。进一步检查表示平面的三维点个数是否大于某个阈值tp和语义平面的面积是否大于某个阈值ta。这一步骤确保排除了由于检测到的边界盒不完全匹配语义对象而提取的平面表面的错误质心。
第二步,利用Eq. 7将摄像机帧内平面的法向方向转换为世界帧,表示为lnk。lni之间的差异lnk必须小于预定义的阈值tn,这样平面才能传递到下一个步骤。
如果语义平面通过第一步和第二步,则使用Eq. 6将质心的相对三维测量值从摄像机帧转换为世界帧。然后,我们可以通过地图地标计算检测到的语义对象的马氏距离。如果计算得到的mahalonobis距离大于给定的阈值,则将检测到的语义对象映射为新的地标Lj,否则将语义对象Sk与当前的地标Li匹配。在图优化步骤(教派IV-D),这两个职位lz以及协方差l 所有映射的语义地标进行了优化。
D. GRAPH OPTIMIZATION
图构造完成之后(IV-B节),图优化步骤包括找到最适合给定VO/VIO度量和语义标志的节点配置。x D (x1;:::;xm)T是机器人的状态向量,其中xi和xj是利用边Ozij连接的节点i和j的位姿,Ozij是通过VO/VIO估计得到的节点i和j的相对位姿。ij是节点之间的信息矩阵i和j . zij是语义具有里程碑意义的测量节点i和j。观察到测量的loglikelihood因此可以给出

是预期的VO/VIO测程结果与从语义标志接收到的测量结果之间的差异。对于一对观测值C,最小二乘估计问题因此寻求找到x*,这最符合前面所有的观察结果:
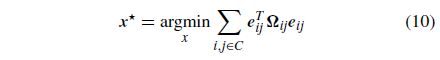
为了提高对语义检测中可能出现的异常值的鲁棒性,在所有语义度量约束条件中添加了Psuedo-Huber成本函数。Eq. 10的解可以通过围绕初始猜测Qx进行线性化得到,从而迭代求解矩阵H和右手向量为b的一个·线性系统:
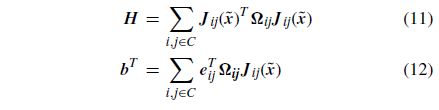
式中,Jij为在Qx计算的误差函数的雅可比矩阵。
在此优化过程中,对机器人的姿态和语义地标位置进行了优化。在因子图优化后,我们还可以恢复更新的协方差的地图地标,以计算马氏距离所需的数据关联(节。IV-C)。对语义对象进行重新观察,并将其正确地关联到所映射的地标上,从而在优化步骤后实现循环闭包。为了快速有效地计算非线性优化问题,利用G2O([32])框架和Lavenberg-Marquardt求解算法。1解释了所提算法的全部工作。
V. EXPERIMENTS AND RESULTS
A. STANDARD DATASET
为了验证我们的方法,我们对标准数据集进行测试,并将其与基于几何和基于对象的SLAM方法的最新方法进行比较。
1) RGB-D SLAM TUM DATASET
该dataset2([29])由kinect传感器提供的点云数据和用于地面真实数据的动作捕捉系统组成。数据集的测程数据采用第四- a节中介绍的RTAB map RGB-D视觉测程算法([28])获得,检测并映射座椅、电视显示器、书籍、键盘等多个语义对象作为语义地标,用于环闭度检测。下面我们将描述在数据集的几个序列上进行的实验,并在第六节中讨论它们的结果。



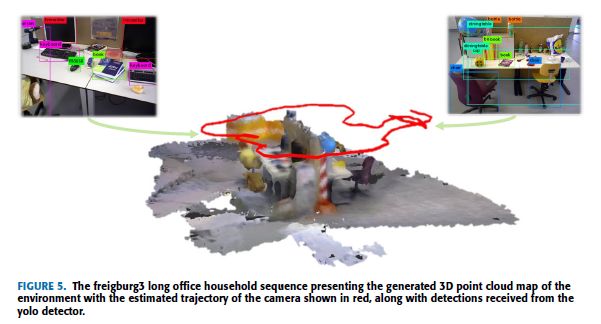
a: Freiburg3 LONG OFFICE HOUSEHOLD (fr3/office)
按照这种顺序,将kinect RBG-D摄像机沿由几种办公材料组成的环境移动,该办公材料包括椅子,桌子,书本,电视显示器等。摄像机以不同的平移运动和旋转运动移动,以验证所提出方法的鲁棒性。图5展示了使用由语义SLAM算法估计的姿势生成的3D点云图。图4a和4b展示了由我们提出的算法估算的相机轨迹和地面真实轨迹。在执行该序列期间,我们提出的算法估计的平均轨迹误差(ATE)([29])为0:033 m,而VIO算法的ATE为0:043 m。
b: Freiburg2 XYZ (fr2/xyz)
在此序列中,kinect摄像机沿x,y和z轴平移运动,没有任何旋转运动。 仅将两个语义对象(电视监视器和键盘)用作语义界标。 图4c和4d展示了我们提出的算法与地面真实轨迹进行比较时的估算轨迹。 我们针对该序列提出的算法的ATE为0:0181m,VIO的ATE为0:0182 m。
c: Freiburg2 RPY (fr2/rpy)
此序列与Freiburg2 XYZ实验相似,只是相机进行了附加的旋转运动以及平移运动。 仅将两个语义对象(电视监视器和键盘)用作语义界标。图4e和4f在将其与地面真实轨迹进行比较时,给出了我们提出的算法估算的轨迹。 我们针对该序列提出的算法的ATE为0:019 m,VIO的ATE为0:0202 m。
d: Freiburg2 DESK (fr2/desk)
在这个序列中,kinect摄像机沿着包含语义对象(例如电视显示器,椅子,键盘和书本)的桌子平移和旋转,图4g和4h比较了我们提出的算法估算的轨迹和地面真实轨迹 。 从图中可以看出,在此序列中,在几个时间实例中都没有地面真实轨迹估计。机器人姿态的ATE和VIO姿态的ATE分别为0:076 m和0:103 m。
B. FIELD EXPERIMENTS
我们在使用不同系统设置的多个实验中评估了我们的算法,并在不同的室内场景中对其进行了验证。所有现场实验均与ORB-SLAM2([1])作为其广泛使用的开源SLAM框架之一进行了比较。 可用。 尽管我们的方法使用的VIO包含附加的IMU信息,但此比较的目的是针对仅使用低级功能的SLAM框架评估使用高级语义信息的建议框架的性能。
1) SYSTEM SETUP
对于实验,如下所述测试了两种不同的系统设置:
a: HAND-HELD SETUP
在此实验设置中,我们使用单个Intel RealSense D435i摄像机。3此版本的RealSense包括RGB摄像机,两个提供深度信息的红外摄像机和IMU传感器。 ROVIO用于测距信息,并使用RGB相机和IMU执行。 RGB相机用于沿着深度信息的语义检测,以提取从检测的语义对象提取平面所需的3D点云数据。
b: AERIAL ROBOTIC SETUP
在此实验设置中,我们使用相同的Intel RealSense相机,除了使用从Snapdragon VIO4传感器设置获得的里程表。 我们使用Snapdragon VIO,因为它是为在空中机器人上工作而优化的,因此可以实现高速飞行,而不会出现VIO算法完全离散的问题。
2) RESULTS
在本节中,我们将介绍在一些具有挑战性的室内场景中使用上一节所述的不同系统设置获得的结果,以验证我们提出的方法的准确性。 图1展示了Nvidia TX2计算机算法每个组件的平均运行时间。 图3分别给出了有关执行本节中描述的现场实验期间获得的地面真实数据的Sect. V-B2c, Sect. V-B2d 和 Sect. V-B2e。

a: LONG HALL EXPERIMENT
我们在室内环境中进行了一些实验,室内环境由长约22 m和宽6min的长通道组成。实验是使用Sect V-B1中介绍的机载空中机器人进行的。由于在该区域飞行的限制,空中机器人装置以手持方式移动。在该实验中,总共进行了5轮,覆盖了大约250 m的总轨迹长度。该实验的目的是在存在长轨迹的情况下测试算法的鲁棒性,并将结果与机器人的VIO估计值进行比较。由于在此实验中没有地面真相测量,因此以重复模式执行5个回合,以证明VIO在每个回合之后积累的漂移以及我们方法提供的准确无漂移姿态估计。我们通过使用我们的算法估计的估计姿势构建的环境的3D地图来展示算法的准确性。
从回收站中提取的平面表面(通常存在于环境中)用作语义对象。 这些随机放置的语义对象中总共只有15个用于映射和改善VIO的漂移。 图6显示了执行实验时获得的3D和2D图,图7a显示了在该实验过程中生成的3D点云图,以及在不同时间间隔对回收站的检测。
b: LONG CORRIDOR EXPERIMENT

该实验的目的是验证在VIO / VO算法的估计中存在大错误以及语义对象混乱的情况下我们算法的鲁棒性。该实验在长14 m,宽20 m的长廊中进行,挑战性的照明条件不利地影响了VIO算法的性能。如第V-B1节中所述,使用手持摄像机设置执行此实验。该环境由椅子和桌子形式的几个语义对象组成。由于桌子的水平面未完全适合边界框,因此仅将椅子的平面表面用于语义映射,这会导致其相对位置估计出错。在走廊周围总共进行了三个重复的轨迹循环,覆盖了大约204 m的总轨迹长度。图6c和图6d显示了在此实验中获得的3D和2D图,将使用我们的方法估算的姿态与VIO姿态估算进行了比较。为了证明在没有地面真实数据的情况下我们算法的准确性,我们展示了走廊的3D地图(图7b),该地图是使用我们的方法估算的3D姿态生成的,还显示了我们的方法估算的轨迹和VIO,以及在不同时间点的检测。
c: REPETITIVE TRAJECTORY WITH SEVERAL SEMANTIC OBJECTS
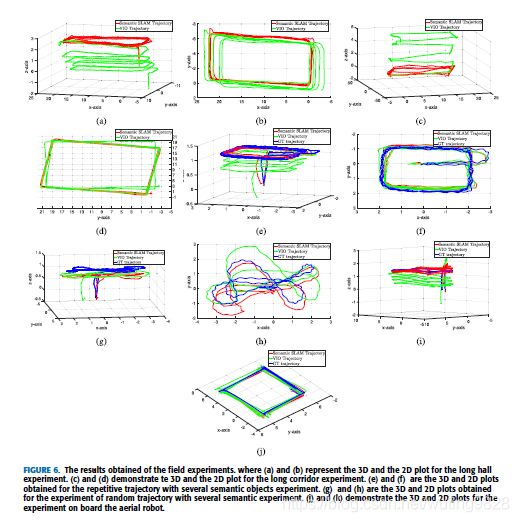
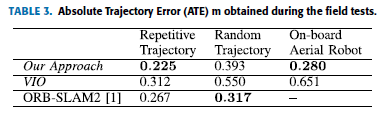
为了在存在不同形状和大小的几个语义对象以及地面真实信息的情况下验证该方法,我们使用本节中介绍的手持相机设置进行了实验。 V-B1。 使用了几种语义对象,例如椅子,电视显示器,键盘和书籍,并将它们放置在随机位置。 在此实验期间,以重复的方式进行了总共4轮,总轨迹长度约为69 m。 图6显示了由此获得的2D和3D图实验,将算法的输出结果与ROVIO,ORB-SLAM2和地面真实数据进行比较。 我们提出的方法的ATE为0:225 m,而使用的VIO算法的ATE为0:312 m。 ORB-SLAM2算法的ATE为0:267 m。
d: RANDOM TRAJECTORY WITH SEVERAL SEMANTIC OBJECTS
本实验的目的是测试在存在多个语义对象的随机杂波的情况下,在存在随机平移以及相机的旋转运动的情况下,所提出方法的鲁棒性。 该实验是使用本节 V-B1中介绍的手持相机设置进行的。存在的语义对象是椅子,电视显示器,书籍和键盘。 语义对象的混乱会在yolo检测器的检测中引起错误,如图7d所示。 图6g和图6h示出了在执行该实验期间获得的3D和2D图。 从我们的方法中获得的结果与ROVIO和ORB-SLAM2进行了比较。 我们的方法的ATE为0:393 m,而ROVIO和ORB-SLAM2的ATE分别为0:550 m和0:317 m。
e: ON-BOARD AERIAL ROBOT
为了测试在存在空中机器人高速运动的情况下算法的鲁棒性,我们在以最大2 m / s的速度飞行的空中机器人上运行该算法。机载空中机器人设置在第20节中进行了说明。 V-B1与手动飞行的空中机器人一起使用,执行带有多个循环的平方轨迹。在这种情况下使用的语义对象是蓝色的回收站,总共只使用了6个回收站,这些回收站与VIO数据一起被证明足以正确估计空中机器人的轨迹。空中机器人,因为它突然运动,会在VIO姿势的z轴估计中引起巨大的漂移,由于在此初始时刻未映射语义界标,因此无法进行校正。为了补偿这种初始漂移,我们介绍了第一个地标的大概位置,该位置在优化过程中与其他语义地标和机器人姿势一起进行了优化。图6表示在此实验中获得的3D和2D图。在此实验期间,我们建议的方法的ATE为0:280 m,VIO为使用的算法的ATE为0:651 m。由于高速运动以及环境中的功能不足,ORB-SLAM2在此实验期间失去了功能跟踪。
VI. DISCUSSIONS
A. STANDARD DATASETS
章节V-A1提供了RGBD TUM数据集和表格的评估。 图2比较了使用我们提出的算法与VO算法以及其他最新技术获得的结果。 从Freiburg3 Long Office Household(图4a和图4b)和Freiburg2办公桌(图4g和图4h)的实验中可以观察到,使用低级功能的前端VO算法在摄像机导航时会积累误差。 围绕环境,我们的方法结合了VO和语义地标的稀疏映射,可以纠正此累积错误(请参见表2)。 在Freiburg2 XYZ(图4c和图4d)和Freiburg2 RPY(图4e和图4f)实验中,即使我们的方法比VO算法提供了更好的结果,姿态估计也仅在短时间内得到改善。 这是由于以下事实:在这些实验中,相机执行的轨迹非常短,因此VO的漂移较小。
从图5可以看出,即使在检测到的语义对象周围的预测边界框中存在错误,我们的算法也能够估计相机姿态(请参见图4),准确地提取,映射和关联相机的平面检测到的物体。由于仅当提取的平面的面积超过某个阈值(在这种情况下设置为15 cm2)才被认为是有效的,因此在数据关联中将检测噪声的影响最小化。因此,从语义对象周围的不完整边界框提取的平面表面,或由于在某些时间实例中图像中存在的不完整语义对象而被拒绝,因为它们的计算面积小于阈值。
从表中可以看出。从图2可以看出,在这些序列中,ORB-SLAM2在大多数情况下都表现出色,部分原因是ORB-SLAM2离线补偿了某些序列在深度图中的比例偏差。由于我们的框架旨在在线工作,因此它使用RTAB地图测距法作为VO,尽管与基于对象的SLAM技术(例如MaskFusion和FusionCC和与基于环境低层特征的最新几何SLAM技术相比具有可比性。
B. FIELD EXPERIMENTS
章节V-B展示了系统设置以及使用我们自己的现场测试从实验中获得的结果,我们在下面的所有这些实验中讨论了获得的结果:
1) LONG HALL EXPERIMENT
图6将我们在实验中获得的算法结果与VIO算法进行了比较。在此实验期间,空中机器人装置围绕长走廊重复了相同的5轮。从图6a的3D图和图6b的2D图可以看出,VIO估计在z轴和x轴上累积了超过3 m的误差,以及方向误差。尽管我们提出的方法使用了VIO的这些噪声估计值以及回收站的平坦表面,但能够正确估计机器人的姿态而没有任何明显的漂移。从本实验中也可以理解,即使存在巨大的由于VIO的姿态估计存在错误,因此我们的算法几乎不需要语义功能即可准确地估算机器人的姿态。为了检查机器人的姿势估计的准确性,图7a展示了使用从我们的算法估计的姿势构建的环境的3D地图。从视觉上可以看出,使用我们的方法估算的姿势可以准确地构建长厅。 ORB-SLAM2也已在此实验中进行了测试,但是由于ORB-SLAM2使用前置RealSense摄像头,因此在靠近墙壁时,由于墙壁没有特征,它失去了跟踪功能,而由于我们的方法可以利用从不同来源生成的里程信息,它不仅限于从前置摄像头生成的里程表,而且可以在这种情况下成功工作。
2) LONG CORRIDOR EXPERIMENT
图6显示了拟议的长廊实验的执行情况。 这项拟议的实验是在非常具有挑战性的室内场景中进行的,该场景包括改变照明条件,从而大大扩展了VIO算法的姿态估计。 从图7b可以观察到这种变化的照明,其中编号为3和4的检测图像与编号为1和2的检测图像相比呈现非常低的照明。这种低照明条件会影响由VIO估计的姿势的准确性。 该算法在x和y位置累积了大误差,在z方向累积了约6 m的巨大误差(请参见图6c中的VIO姿态估计)。
由于语义对象(椅子)的混乱,yolo对象检测器还估计了检测到的对象周围的几个不准确的边界框(请参见图7b)。在我们的方法中,这种检测中的噪声不会对语义对象的相对姿态估计产生不利影响,因为在将其添加为语义界标之前进行了多次安全检查,包括对平面阈值进行了实验,在本实验中将其设置为10平方厘米。如图6所示,使用这些高噪声VIO姿态估计和走廊中的语义检测,我们的方法显然能够纠正VIO估计中存在的漂移,即使在这种充满挑战的室内环境中也可以进行精确的环路闭合。在此实验中,我们还评估了ORB-SLAM2的性能。从检测图像(图7b)可以看出,环境由几面无特征的白色墙壁组成,因此,仅使用低级特征信息的ORB-SLAM2在靠近表面时会失去其跟踪。鉴于,我们提出的框架可以轻松集成两种VIO算法,因此我们从ROVIO算法中选择估计值,该算法会累积较大的漂移,但不会由于附加的惯性信息而失去特征跟踪。
3) REPETITIVE TRAJECTORY WITH SEVERAL SEMANTIC OBJECTS
图6展示了使用几种具有不同形状和大小的语义对象(例如椅子,电视显示器,键盘和书籍)执行的实验。即使对于具有不同复杂3D结构的语义对象(如椅子),该算法也能够准确估计此类语义对象的3D位置并将其映射,因此,当与机器人进行比较时,能够估计机器人的无漂移轨迹VIO姿态估计和地面真实姿态。如图7c所示,yolo检测器估计有误差的物体周围的边界框。很多情况下,边界框无法完全适合对象或过度拟合对象。由于这些检测错误,使用边界框内3D点的中位数估算的语义对象的3D姿势可能会偏离真实位置。由于我们从这些语义对象中提取了平面信息,并且只允许在某个区域(在本实验中设置为15 平方厘米)上方的平面,因此,无论检测结果有何误差,我们都可以使用语义标记准确地映射和定位。
我们还将仅基于几何特征的实验结果与使用ORB-SLAM2的实验结果进行了比较。由于在此实验中,摄像头朝地面倾斜了约25度,并且由于地板上包含多个重复的图案,因此ORB-SLAM2会退化与ATE为0:226 m的方法相比,ATE的跟踪性能为0:267 m。
4) RANDOM TRAJECTORY WITH SEVERAL SEMANTIC OBJECTS
图6展示了以混乱的语义对象以随机轨迹方式进行的实验。由于光照条件不足以及相机的几次旋转以及平移运动,在此实验期间,由ROVIO算法估计的轨迹会降低其性能,并在其估计中积累巨大的漂移(请参见图6g和图6h)。还可以从图7d中观察到,在该实验期间,从yolo检测器接收到的检测具有明显的错误,例如,由于语义对象的混乱,估计在椅子周围有几个错误的边界框。即使存在这些检测错误,平面提取也不会受到很大的影响,因为仅当平面满足3D点阈值且平面阈值为0:15 平方厘米时才提取平面。因此,即使VIO估计中存在巨大的漂移以及检测中的错误,我们的方法也能够将摄像机的估计轨迹校正为地面真实轨迹,而我们算法估算出的ATE为0:393 m ,而ROVIO的ATE估计其漂移较大,为0:550 m。
在本实验中,由ORB-SLAM2估算的轨迹的ATE为0:317 m。 在此实验中,ORB-SLAM2的性能也会下降,但差异不会像ROVIO那样大。 在本实验中,由ROVIO估算的里程表与地面真实轨迹的偏差为1:5 m,我们的算法使用语义界标对其进行了很大程度的校正(见图6h)。 但是由于我们算法的前端确实取决于估计的VIO轨迹,因此VIO估计中的这些巨大误差导致我们在此实验中的算法性能下降,与ORB-SLAM2相比,该算法的性能稍差。
5) ON-BOARD AERIAL ROBOT
图6表示在空中机器人上进行的实验的图。机器人执行几个循环,最大速度为2m / s。由于空中机器人的高速运动,VIO在其位置和方向上积累了很大的漂移。然而,从3D和2D图(分别为图6i和图6j)可以看出,即使在如此高速的空中机器人的情况下,仅使用6个回收箱,我们的方法也不会偏离地面真实情况机器人。实验证明,我们提出的方法能够以较少的语义特征和在空中机器人的高速运动下纠正VIO算法中存在的位置和方向误差。
在此实验期间,室内环境由单色的白色表面组成,几乎没有几何特征,并且空中机器人还执行高速角向和平移运动。由于这些原因,ORB-SLAM2失去了功能跟踪,无法估计机器人的姿势。由于我们的框架松散地耦合了VIO估计,因此它可以使用最适合特定应用的VIO算法以松散耦合的方式集成多种VIO算法。因此,使用了经过优化可在空中机器人上运行的Snap VIO,它的性能会随着时间而下降,但不会失去功能跟踪。
VII. CONCLUSION
在本文中,我们提出了一种快速,健壮和轻量级的视觉语义猛击算法,该算法使用常用的平面作为高级语义信息。它能够在空中机器人上运行,以估计其无漂移轨迹。我们用文献中提供的标准数据集测试了该算法,表明与现有的VO / VIO算法和基于对象的SLAM技术相比,该算法能够提供更好的结果,并且与几何SLAM技术具有可比的结果。我们还通过手持摄像机设置以及机载空中机器人设置在不同的挑战性室内场景中进行了一些实验,证明了算法在这些挑战性室内环境中以及在空中飞行的机载空中机器人工作的能力速度为2 m / s。由于该框架将VO / VIO估计与语义映射方法松散地结合在一起,因此我们能够使用几种最先进的VO和VIO方法集成和测试我们的算法,从而在给定场景中选择性能最佳的算法。 Video5在提出的现场测试中演示了该算法的工作,并且该算法的源代码6是公开可用的,以使科学界能够利用所介绍的工作并对其进行改进以增加进一步的增强。