图像到图像的映射(二)创建全景图
找到两幅图像的匹配点以后采用将第二张图像叠加到第一张图像的坐标系中的方法(映射见《图像到图像的映射(一)》)
多张图的映射就是全景图。
随机采样一致性(RANSAC)算法结合去除不可靠的匹配对。
RANSAC算法流程
RANSAC 是“RANdom SAmple Consensus”(随机一致性采样)的缩写。该方法是用来找到正确模型来拟合带有噪声数据的迭代方法。给定一个模型,例如点集之间的单应性矩阵,RANSAC 基本的思想是,数据中包含正确的点和噪声点,合理的模型应该能够在描述正确数据点的同时摒弃噪声点。
在计算单应性变换矩阵时,只需要4对匹配点,就可以求得两幅图像之间的变换矩阵,然而,在特征点提取时,会产生大量的匹配特征点,这样对变换矩阵H的精度就会有很大的影响,由于在特征检测时特征检测算子对图像特征的误检测,一般的参数估计方法都无法将其排除,所以本文采用RANSAC算法来完成对匹配点的求精。RANSAC算法经常被应用于计算机视觉领域中,是最有效的鲁棒变换估计算法之一,其应用在计算投影变换矩阵的主要步骤为:
- 从两幅图像匹配点集合中随机抽取最少的匹配点集,构成待定投影变换矩阵H的初始模型参数;
- 将所有的集合数据依次代入(1)中所求得的模型中,计算代入点与初始点之间的距离,若小于某一阈值t,则将该点称为内点(inliers),否则称为外点(outliers),将获得的内点进行记录;
- 通过计算获取原始匹配集合中的所有内点(inliers),针对最大inliers集合,用它们重新计算模型参数,即可得到投影变换矩阵H的最终结果。
RANSAC 算法的优点能鲁棒的估计模型参数。例如,它能从包含大量局外点的数据集中估计出高精度的参数。
缺点是它计算参数的迭代次数没有上限,如果设置迭代次数的上限,得到的结果可能不是最优的结果,甚至可能得到错误的结果。
RANSAC只有一定的概率得到的可信的模型,概率与迭代次数成正比。另一个缺点是它要求设置跟问题相关的阈值,
RANSAC只能从特定的数据集中估计出一个模型,如果存在两个(或多个)模型,RANSAC不能找到别的模型。(这一部分在homography.py文件中)
class RansacModel(object):
""" 单应性矩阵由
http://www.scipy.org/Cookbook/RANSAC的 ransac.py计算
"""
def __init__(self,debug=False):
self.debug = debug
def fit(self, data):
""" Fit homography to four selected correspondences. """
# transpose to fit H_from_points()
data = data.T
# 映射起始点
fp = data[:3,:4]
# 映射的目标点
tp = data[3:,:4]
# 计算单应性矩阵
return H_from_points(fp,tp)
def get_error( self, data, H):
""" 将单应性矩阵的每个转换点的返回错误。 """
data = data.T
# from points
fp = data[:3]
# target points
tp = data[3:]
# transform fp
fp_transformed = dot(H,fp)
# normalize hom. coordinates
fp_transformed = normalize(fp_transformed)
# return error per point
return sqrt( sum((tp-fp_transformed)**2,axis=0) )
get_error()方法对每个对应点使用该单应性矩阵的、,然后返回平方距离之和,因此RANSAC能够判定哪些点是Udine的,哪些点是错的。
当拍摄的图像是多平面的时候,更大概率出现错误匹配对。图像配准的过程中就会出现鬼影现象。
全局拼接(RANSAC)
传统的全局拼接方法首先在相邻的图像之间进行两两配准,计算局部变换矩阵,然后把这些局部变换矩阵进行递推组合,计算全局变换矩阵,然而由于测量噪声、光照条件等不确定性,相邻图像之间的两两配准存在误差,并且随着递推过程向后传播,造成图像配准结果不一致,出现拼接裂缝,且拼接处色差落差大。
场景一(室外近景 场景层次简单 光线充足)

场景二(室外 场景层次简单 景深落差较小)

场景三(室外 树木较多 层次丰富 景深落差较大)


场景四(室内 场景层次丰富)


实验结果分析
传统的全局拼接最终效果,都出现了拼接裂缝,且拼接处出现了不同程度的色差。
室外光线充足,且选择的建筑物的纹理较为清晰,sift特征点明显,图片拼接效果较好。但是当特征物受到其他因素的影响(如树木遮挡等)时,由于树木、草地的纹理复杂,相似点多,拼接的结果容易出现偏差,拼接缝较大。
室内由于空间范围比较局限,并且杂物较多,纹理较复杂。拼接图像时,函数计算出透射变换矩阵后,会扭曲图像并叠加到中心图像去。在此过程中,由于拍摄角度的变化太大,当该图像参与拼接时,图像扭曲的程度较大,容易形成一个由中心图像向外发散的图像,导致拼接错位。
主观评价:
只附上主程序,要安装好PCV包
这个图片的匹配是由中间向两端先完成左半边拼接后,再继续中间向两端完成右半边拼接,但是这里图片的命名顺序要注意是从右往左命名,因为匹配的方向。
如五张图片的时候:im0,im1,im2,im3,im4,是im1-im2得到im12,im0-im12得到im02,im3-im02得到im32,im4-im32得到im42为最终全景图。
书中是五张图为一组图集,这里代码修改为三张图为一组图集,
匹配规则简化为im0-im1到im01,im2-im01得到im21为最终全景图。
奇数(2n+1)张图集或者偶数张图集2n都是匹配2n次。
# -*- coding: utf-8 -*-
from pylab import *
from numpy import *
from PIL import Image
# If you have PCV installed, these imports should work
from PCV.geometry import homography, warp
from PCV.localdescriptors import sift
# set paths to data folder
featname = ['su'+str(i+1)+'.sift' for i in range(3)]
imname = ['su'+str(i+1)+'.jpg' for i in range(3)]
# extract features and match
l = {}
d = {}
for i in range(3):
sift.process_image(imname[i],featname[i])
l[i],d[i] = sift.read_features_from_file(featname[i])
matches = {}
for i in range(2):
matches[i] = sift.match(d[i+1],d[i])
# visualize the matches (Figure 3-11 in the book)
for i in range(2):
im1 = array(Image.open(imname[i]))
im2 = array(Image.open(imname[i+1]))
figure()
sift.plot_matches(im2,im1,l[i+1],l[i],matches[i],show_below=True)
# 将RANSAC应用到对应点对上
# 将匹配转换成齐次坐标点的函数
def convert_points(j):
ndx = matches[j].nonzero()[0]
fp = homography.make_homog(l[j+1][ndx,:2].T)
ndx2 = [int(matches[j][i]) for i in ndx]
tp = homography.make_homog(l[j][ndx2,:2].T)
# switch x and y - TODO this should move elsewhere
fp = vstack([fp[1],fp[0],fp[2]])
tp = vstack([tp[1],tp[0],tp[2]])
return fp,tp
# 估计单应性矩阵
model = homography.RansacModel()
fp,tp = convert_points(0)
H_01 = homography.H_from_ransac(fp,tp,model)[0] #im 0 to 1
tp,fp = convert_points(1) #NB: 反向点
H_21 = homography.H_from_ransac(fp,tp,model)[0] #im 2 to 1
# 扭曲图像
delta = 2000 # 用于填充和平移
im1 = array(Image.open(imname[0]), "uint8")
im2 = array(Image.open(imname[1]), "uint8")
im_01 = warp.panorama(H_01,im1,im2,delta,delta)
im1 = array(Image.open(imname[2]), "f")
im_21 = warp.panorama(H_21,im1,im_01,delta,delta)
figure()
imshow(array(im_21, "uint8"))
axis('off')
show()
APAP
Julio Zaragoza等提出的APAP (As-Projective-As-Possible)拼接,在保存了被摄体的整体单应性假设的前提下,假设被摄体的细节部分满足不同的局部单应性,并通过一个新的滑动窗口方法,被称为Moving DLT (Moving Direct Linear Transformation),对其进行加权估计,在很大程度上解决了单应性拼接方法中,噪音和视差带来的图像错位和鬼影。2013年,Julio Zaragoza等人发表了一种新的图像配准APAP算法,适用于“当场景是平面的或者视图纯粹因旋转而不同时”的图像配准。
流程是:
- SIFT提取匹配点对;
- RANSAC去除outliers(去除不正确的匹配点)
- 计算全局的单应矩阵,计算拼接之后整幅图尺寸,使用全局单应矩阵将Source Image映射到Target Image中去
- 在两幅图片和中有一对匹配的点对,得到原始图像(Source Image)中的点与目标图片(Target Image)中的点的一个映射关系。不同于原来直接求解单应性矩阵的映射,是在计算单应性矩阵的时候采用了加权估值,对于那些不是对应点的像素点,将它周围所有的点对它进行一个加权计算。
参考:
https://image.hanspub.org/Html/5-2670059_16204.htm
https://blog.csdn.net/xuanwu_yan/article/details/9400321
APAP与全局拼接效果比对
可以看出APAP一定程度上消除重影的现象


尽管APAP投射的方法能提高局部投射的准确性,但是若投射的基础不对,也只是在投射基础不正确的前提下,配准出错的更少一点而已。以此类推,误差累积更甚。
最大流和最小割
转载文章:图形分割算法
最小割
如下图1所示,是一个有向带权图,共有4个顶点和5条边。每条边上的箭头代表了边的方向,每条边上的数字代表了边的权重。
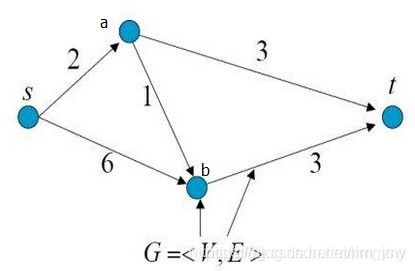
图1
公式1:
G = < V , E > G=<V,E> G=<V,E>
公式1是图论中对图的表示方式,其中V表示顶点(vertex)所构成的集合,E表示边(edge)所构成的集合。顶点V的集合和边的集合E构成了图G(graph)。
以图1为例,图1中顶点s表示源点(source),顶点t表示终点(terminal),从源点s到终点t共有3条路径:
s − > a − > t s -> a -> t s−>a−>t
s − > b − > t s -> b -> t s−>b−>t
s − > a − > b − > t s -> a -> b-> t s−>a−>b−>t
现在要求剪短图中的某几条边,使得不存在从s到t的路径,并且保证所减的边的权重和最小。相信大家能很快想到解答:剪掉边”s -> a”和边”b -> t”。
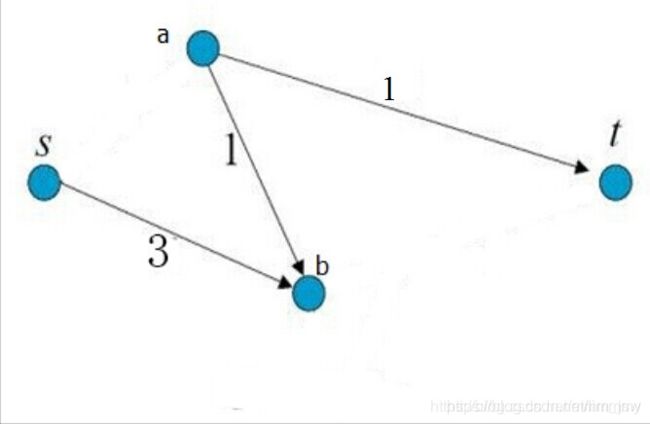
图2
如上图2所示,图中已经不存在从源点到终点的路径,所割掉的边的权重值之和为5,是所有的切割方式中权重值最小的,像这样的切割方法我们将其称之为最小割。
最大流
如图所示,假如顶点s源源不断有水流出,边的权重代表该边允许通过的最大水流量,顶点t流入的水流量最大是多少?
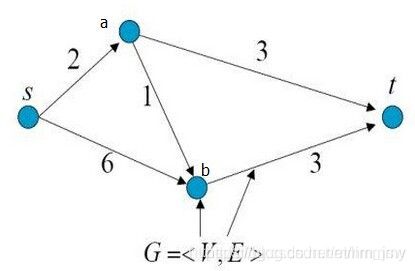
max-flow
我们可以从顶点s到顶点t的3条路径着手分析,从源点s到终点t共有3条路径:
s -> a -> t:流量被边”s -> a”限制,最大流量为2
s -> b -> t:流量被边”b -> t”限制,最大流量为3
s -> a -> b-> t:边”s -> a”的流量已经被其他路径占满,没有流量
所以,顶点t能够流入的最大水流量为:2 + 3 = 5。
这就是最大流问题。所以,图1的最大流为:2 + 3 = 5。
可以发现图1的最小割和最大流都为5,经过数学证明可以知道,图的最小割问题可以转换为最大流问题。所以,算法上在处理最小割问题时,往往先转换为最大流问题。
求解最大流和最小割是两个算法,只是求解最大流问题可以转化为求解最小割问题。