(1小时数据结构)数据结构c++描述(二十八)--- 图(强连通分量)
强连通分量定义:
如果两个顶点 v 和w是互相可达的,则称它们为强连通的。也就是说,既存在一条从v到w的有向路径,也存在一条从w到v的有向路径。如果一幅有向图中的任意两个顶点都是强连通的,则称这幅有向图也是强连通的。
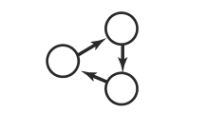
上面的有向图中,就是一个联通分量。应为也是一个图,所以也是连通图。

此图,所有用灰色标记的就是对应的连通分量,{1},{0,2,3,4,5},{6},{7,8},{9,10,11,12}.
在有向图中,强连通性其实是顶点之间的一种等价关系,因为它有以下性质
- 自反性:任意顶点 v 和自己都是强连通的
- 对称性:如果 v 和 w 是强连通的,那么 w 和 v 也是强连通的
- 传递性:如果 v 和 w 是强连通的且 w 和 x 也是强连通的,那么 v 和 x 也是强连通的
比如我们研究一个问题
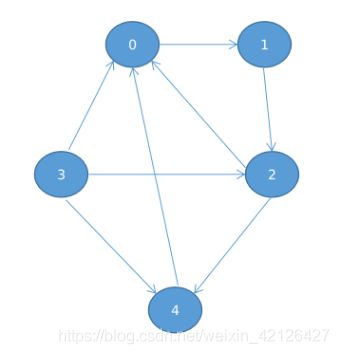
如图,我们可以看到它的连通分量是 {0,1,2,4},{3}。有些人会想到DFS遍历一次就可以吗,前提你必须是从0开始,如果你从3开始的话,是不是会出现问题。
下面据个比较经典的例子:

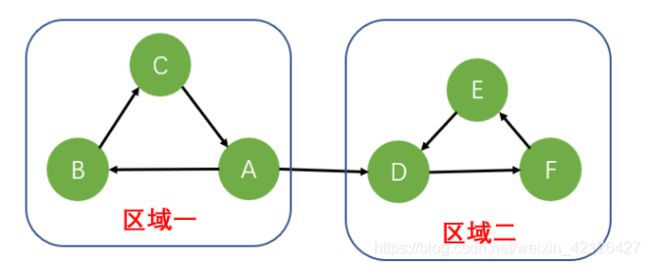
我们知道区域一,与区域二是两个连通分量,若从A开始的话,采用DFS遍历,发现遍历一的时候会遍历到二,但是区域一与区域二并不是强连通的。
若我们采用D开始的话,就会发现先遍历区域二,在遍历区域一。就是我们想要的呀。
在看下个图:

我们把第二个图,用这样的方式来表达,每个灰色区域是一个连通量,举一个例子,若我们从0开始DFS遍历,发现会连到1,那我们从1开始,一次往后退的方式,是不是就能解决这个问题,那我们如何来解决这个问题呢,如何找到这个顺序呢。
于是 Kosaraju算法出现了:
Kosaraju算法:
1.在给定的一幅有向图 G 中, 来计算它的反向图 GR 的逆后序排列
2.在 G 中进行标准的深度优先搜索,但是要按照刚才计算得到的顺序而非标准的顺序来访问所有未被标记的顶点。
第一步中,求的顺序就是我们需求的对应的想要的顺序,1,0,2,4,5,3,11,9,12,10,6,7,8.

第二步,然后我们在正序的DFS的时候就是按这个遍历,这样上面的问题便可以解决了。
代码部分:
template
void Graph::ShowConnection()
{
CalculateConnection();
set connections[100];
for (int i = 0; i < n; ++i) {
connections[id[i] - 1].insert(i);
}
for (int j = 0; j < connectedCount; ++j) {
cout << "connection " << j + 1 << ":";
for (set::iterator set_iter = connections[j].begin();
set_iter != connections[j].end(); set_iter++)
{
cout << *set_iter << " ";
}
cout << endl;
}
}
template
void Graph::CalculateConnection()
{
connectedCount = 0;
bool *visited = new bool[n];
for (int i = 0; i < n; ++i) {
visited[i] = false;
id[i] = 0;
}
//根据本图的反向图的顶点逆后序序列来进行DFS
//所有在同一个递归DFS调用中被访问到的顶点都在同一个强连通分量中
R = new Graph(n);
Reverse(); //程序改进
R->CalReversePost();
stack topostack = R->GetReversePost();
int j;
while (!topostack.empty()) {
j = topostack.top();
topostack.pop();
if (!visited[j]) {
connectedCount++;
DFSForConnection(j, visited);
}
}
delete[] visited;
} 其中的 Reverse(); 函数在 图BFS遍历 与 DFS遍历中有定义,CalReversePost()与GetReversePost在上一章拓扑排序中有定义。需要了解的可以看关注看我博客。
tarjan算法
我们继续看这个例子:
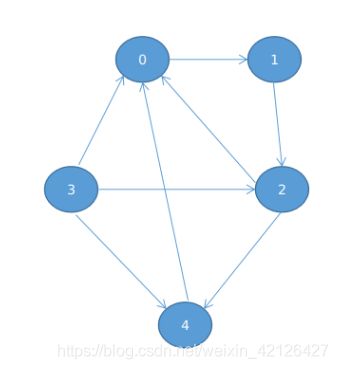
躺若我们遍历到A的时候,不让他到D,不就可以解决这个问题了吗,于是 tarjan算法诞生了。
Tarjan算法是基于DFS的算法,每个强连通分量为搜索树中的一棵子树。搜索时,把当前搜索树中未处理的结点加入栈中,回溯时可以判断栈顶到栈中的结点是否为一个强连通分量。
visited[u]:顶点u是否被访问过
dfn[u]:DFS遍历时顶点u被搜索的次序,也即时间戳
low[u]:顶点u能够回溯到的最早位于栈中的顶点
tarjanStack:用于存放每次遍历时被搜索到的顶点
inStack[u]:u目前是否在栈中,要配合tarjanStack使用
index:时间戳,随着访问的结点而递增
具体过程如下:
- 首先就是按照DFS算法搜索的次序对图中所有结点进行搜索。
- 在递归搜索过程中:
(1) 时间戳的初始化:当首次搜索到点u时,dfn和low数组的值都为到该点的时间戳。
(2)栈:每搜索到一个未访问过的点,将它压入栈中。
(3)对于由u指向的结点v,如果此时(时间为dfn[u]时)v还没被访问过,则继续对v进行深度搜索。如果此时结点v已经在栈中,则用u的low值和v的DFN值中最小值来更新low[u]。因为如果DFN[v] < low[u],则根据low值的定义,即能够回溯到的最早已经在栈中的顶点,所以我们应该用DFN[v]来更新low[u],表示u能和v回溯到相同的最早顶点。 - 在回溯过程中,即从对结点v的深度搜索中返回后,用u和v两点low值的最小值来更新low[u]。因为顶点v能够回溯到的已经在栈中的顶点,顶点u也一定能回溯到。因为存在从u到v的直接路径,所以v能够到达的顶点u也一定能够到达。
- 搜索完从顶点u指出的所有顶点后(也就是子树已经全部遍历),判断该结点的low值和dfn值是否相等。如果相等,则该结点一定是在深度遍历过程中该强连通图中第一个被访问过的顶点,因为它的low值和dfn值最小,不会被该强连通图中其他顶点影响。(论证一下为什么在同一个强连通分量中一定仅有一个结点的low值等于dfn值?因为如果在同一个强连通分量中有两个结点的low值等于dfn值,又这两个结点的dfn值一定不相同,所以它们的low值也一定不相同。可是根据low的定义,既然这两个结点位于同一个连通分量中,也就是这两个结点必然可达,那么这两个结点中其中一个结点的low值一定会被另外一个所影响,导致两个low值相同。这与假设矛盾,所以在同一个强连通分量中不可能存在两对dfn值和low值相等的结点。)既然知道了该顶点是该强连通子树里的根,又根据栈的特性,则该顶点相对于同个连通图中其他顶点一定是在栈的最里面,所以能通过不断地弹栈来弹出该连通子树中的所有顶点,直到弹出根结点即该顶点为止。
代码:
//用tarjan算法求强连通分量
template
void Graph::TarjanForConnection()
{
connectedCountForTarjan = 0;
bool *visited = new bool[n];
int *dfn = new int[n];
int *low = new int[n];
stack *tarjanStack = new stack;
bool *inStack = new bool[n];
int index = 0;
memset(visited, false, n);
memset(dfn, 0, n*4);
memset(low, 0, n*4);
memset(inStack, false, n);
for (int i = 0; i < n; ++i) {
if (!visited[i]) {
TarjanForConnection(i, visited, dfn, low, tarjanStack, inStack, index);
}
}
for (int i = 0; i < connectedCountForTarjan; ++i) {
cout << "connection " << i + 1 << " : ";
for (auto ite : tarjanConnection[i]) {
cout << ite << " ";
}
cout << endl;
}
delete[] visited;
delete[] dfn;
delete[] low;
delete tarjanStack;
delete[] inStack;
}
template
void Graph::TarjanForConnection(int u, bool * visited, int * dfn, int * low, stack* tarjanStack, bool * inStack, int & index)
{
dfn[u] = low[u] = ++index; //为顶点u设访问时间戳和low初值
visited[u] = true; //修改为已访问
tarjanStack->push(u); //顶点u入栈
inStack[u] = true;
//搜索从顶点u指出的每个顶点
for (ENode *w = enodes[u]; w; w = w->next) {
if (!visited[w->adjVex]) { //顶点v还没被访问过
TarjanForConnection(w->adjVex, visited, dfn, low, tarjanStack, inStack, index);
//从上个递归函数返回后就是回溯过程,用u和v即w->adjVex的最小low值来更新low[u]。
//因为顶点v能够回溯到的已经在栈中的顶点,顶点u也一定能回溯到。
//因为存在从u到v的直接路径,所以v能够到达的顶点u也一定能够到达。
low[u] = low[u] < low[w->adjVex] ? low[u] : low[w->adjVex];
}
else if (inStack[w->adjVex]) { //顶点v已经在栈中
//用u的low值和v的DFN值中最小值来更新low[u]。
//如果DFN[v]adjVex] ? low[u] : dfn[w->adjVex];
}
}
//搜索完从顶点u指出的所有顶点后判断该结点的low值和DFN值是否相等。
//如果相等,则该结点一定是在深度遍历过程中该强连通图中第一个被访问过的顶点,因为它的low值和DFN值最小,不会被该强连通图中其他顶点影响。
//既然知道了该顶点是该强连通子树里的根,又根据栈的特性,则该顶点相对于同个连通图中其他顶点一定是在栈的最里面,
//所以能通过不断地弹栈来弹出该连通子树中的所有顶点,直到弹出根结点即该顶点为止。
if (low[u] == dfn[u]) {
connectedCountForTarjan++; //找到一个强连通分量,计数自增
int x;
do {
x = tarjanStack->top();
tarjanStack->pop();
inStack[x] = false; //注意要和tarjanStack配套使用
tarjanConnection[connectedCountForTarjan - 1].push_back(x);
} while (x != u);
}
else {
return; //不等则返回
}
} 解决图:
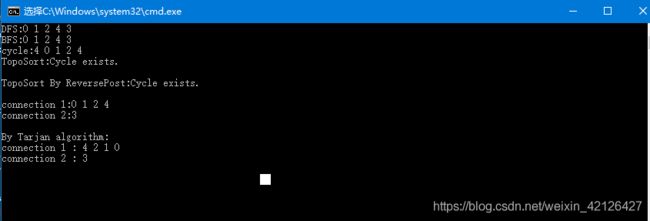
代码测试:
void testGraph2()
{
const int n = 5;
Graph graph(n);
set edgeInput[n];
edgeInput[0].insert({ 1 });
edgeInput[1].insert({ 2 });
edgeInput[2].insert({ 0,4 });
edgeInput[3].insert({ 0,2,4 });
edgeInput[4].insert({ 0,});
for (int i = 0; i < n; ++i) {
for (set::iterator set_iter = edgeInput[i].begin(); set_iter != edgeInput[i].end(); set_iter++) {
graph.Insert(i, *set_iter, 1);
}
}
//测试深度优先遍历
cout << "DFS:";
graph.DFS();
cout << endl;
//测试宽度优先遍历
cout << "BFS:";
graph.BFS();
cout << endl;
//测试是否有环
if (graph.HasCycle()) {
cout << "cycle:";
stack cycle = graph.GetCycle();
while (!cycle.empty()) {
cout << cycle.top() << " ";
cycle.pop();
}
cout << endl;
}
else {
cout << "cycle doesn't exist." << endl;
}
//测试拓扑排序
cout << "TopoSort:";
graph.TopoSort();
cout << endl;
//测试用DFS来求拓扑序列
cout << "TopoSort By ReversePost:";
graph.TopoSortByDFS();
stack topo = graph.GetReversePost();
while (!topo.empty()) {
cout << topo.top() << " ";
topo.pop();
}
cout << endl;
//测试强连通分量
graph.ShowConnection();// Kosaraju
cout << endl;
//测试tarjan算法求强连通分量
cout << "By Tarjan algorithm:" << endl;
graph.TarjanForConnection();
} 测试结果:
喜欢我的博客的小伙伴可以关注我博客,数据结构置顶有整个数据结构的目录与对应的源码,快来关注我吧。