Lifelong SLAM 论文解读合集(2):针对长时间重复运行SLAM地图更新问题
目录
- (IROS 2020)Are We Ready for Service Robots? The OpenLORIS-Scene Datasets for Lifelong SLAM
- 下载链接
- 具体内容
- (ICRA 2012)Practice Makes Perfect? Managing and Leveraging Visual Experiences for Lifelong Navigation
- 经验积累
- 塑性地图
- 创建地点
- (IROS2009)Towards Lifelong Visual Maps
- 骨架图和frameSLAM
- 视角删除
- 环境类型
(IROS 2020)Are We Ready for Service Robots? The OpenLORIS-Scene Datasets for Lifelong SLAM
一个针对室内服务机器人的lifelong SLAM数据集。
下载链接
数据集传送门:lifelong-robotic-vision.github.io/dataset/scene
数据集传送门:https://shimo.im/docs/HhJj6XHYhdRQ6jjk/read
具体内容


(ICRA 2012)Practice Makes Perfect? Managing and Leveraging Visual Experiences for Lifelong Navigation

这篇文章提出了一个叫做经验的概念,意思是对同一个地方多次观测都被叫做经验。反复经过几个地方就是在积累经验。如果根据现有经验定位在某一个失败了,我们将其归咎于经验不够导致的错误的数据关联,从而进一步存储针对这个地方的新的经验。根据在不同的场景下积累经验,企图获得一条完整的轨迹非常困难,因为缺乏数据的对应关系。
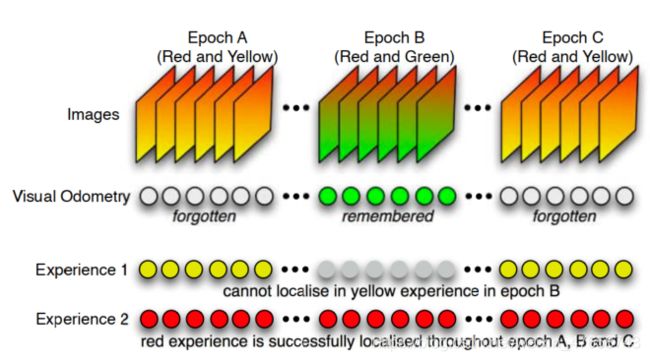
经验积累
就像上面那个图,Epoch B在experience 1里定位失败了,但在experience 2里成功了,定位成功的experience过少(少于一定比例),我们就需要存储Epoche B上面给定的VO数据输出作为新的经验。在Epoch A和Epoch C中,能定位成功的经验非常多,因此我们不存储他们的VO输出作为新的experience。对于VO来说,经验指的就是relative poses and feature locations。当访问同一个区域的时候,Upon revisiting an area, localisation is attempted in all previous experiences that are relevant to the area。有关于这一区域的所有经验都会被尝试用来定位。
塑性地图
We denote experiences by E andrefer to the jth experience as jE. The set of all experiences creates the plastic map。塑性地图其实就是由一堆经验组成的,经验前面已经说过是啥了。往塑性地图里加经验的方法如下:
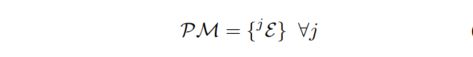

这个算法里,允许的最小经验数量越大,系统就越来越鲁棒。但是个人认为,如果同一个地方环境变化不大,却被强行安排了一大堆的经验,是不是太浪费储存空间。同一个地方的不同经验被分别保存,而不是合并、求平均等操作,目的是保证显式解决数据关联的问题。
创建地点
When Fk is simultaneously localised in more than one experience we can create a place. By querying each successful localiser for its nearest node, we can create a place with the set {jEm}k.当一帧图像能够同时被好几个经验定位,我们找成功定位的这几次经验中离我这一帧最近的节点,为这几个节点来创建一个place地点。However it is also possible a previously created place contains some of these nodes, in which case we merge the sets created from Fk and the previous place.如果被找到的节点,被之前产生的地点所包含,我们就把当前这一帧产生的place与之前的place合并:
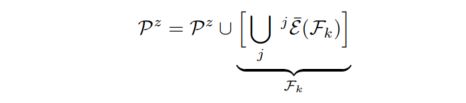

就像上面的图片里,A和B被合并成了C地点,地点是被用来连接不同的经验的。 We require the ability to query all places with a set of experience nodes, and receive the set of places which contain these nodes. 算法要求能够利用一系列经验来检索所有的地点,并且能够收到一系列地点来包含这些节点。
(IROS2009)Towards Lifelong Visual Maps
这篇文章是willow garage团队发的一个关于双目视觉lifelong mapping的一篇论文。他们认为,lifelong mapping解决下面三个问题:
- 增量地图
- 动态环境
- 定位和里程计失效
作者说自己有两大贡献:其一是提出了一套lifelong mapping的框架,能够进行地图缝合和修补,重定位,删除地图以保持效率。其二就是他这个删除的方法非常秀,有利于重定位。
骨架图和frameSLAM
整体的流程和keyframe based SLAM一样,定义了两帧ci和cj之后,可以有:

那个诡异的圆形符号就是俩位姿做差的意思,The covariance expresses the strength of the constraint, and arises from the geometric matching step that generates the constraint. 协方差就是匹配是生成的,表示这个约束的强弱。
视角删除
view deletion指从骨架图中删除view,具体就是下面的公式,删除了t1之后留下t0和t2:

环境类型

作者主要把环境分为了5种:
- In a completely static scene, a view will continue to match all view that come after it.
- In a static scene with some small changes (e.g., dishes or chairs being moved),
there will be a slow degradation of the matching score over time, stabilizing to the score for features in the static areas. - If there is a large, abrupt change (e.g., a large poster moved), then there is a large falloff in the matching score.
- There are changes that repeat, like a door opening and closing, that lead to occasional spikes in the response graph.
- Finally, a common occurrence is an ephemeral view, caused by almost
complete occlusion by a dynamic object such as a person – this view matches nothing subsequently.
进一步地,我们需要对这些环境种类进行聚类。
 这个c衡量两帧之间地接近程度,m代表两帧中特征较少那一帧地特征点个数,m_tilde指的是匹配上的特征点个数。当两帧完全匹配了,c就是0。一个聚类就是一个view集合的最大连通子图。
这个c衡量两帧之间地接近程度,m代表两帧中特征较少那一帧地特征点个数,m_tilde指的是匹配上的特征点个数。当两帧完全匹配了,c就是0。一个聚类就是一个view集合的最大连通子图。