Large-scale Video Classification with Convolution Neural Networks
Large-scale Video Classification with Convolution Neural Networks
摘要:卷积神经网络(CNNs)在图像识别问题中已经被当做一个有力的模型被建立起来。受这些成果的影响,我们在大规模的视频分类数据集上准备了大量的对于CNNs经验的评价,我们用了一个新的数据集,它包括一百万个YouTube视频,属于487个不同的类别。为了扩展CNN的在时间域的连通性,我们研究很多种方法,为了利用局部时空信息和多分辨率,有凹的结构作为一个有希望的方法来加速训练。我们最好的时空网络跟基于特征的方法比较来看,表现出了很好的性能(55.3% VS 63.9%),但是相比于单帧模型,只有一点点的提升(59.3% VS 60.9%)。我们更加深入的研究了我们最好的模型的泛化性能,通过在UCF101动作识别数据集上对顶层进行再训练,观察到相对于基于UCF101数据集的模型有很显著的性能提升(63.3%VS 43.9%)。
1.引言:图像和视频在网络上变得普遍存在了,这就鼓励了大量算法的发展,用来分析这些图片和视频的语义信息。目前,对于理解图片内容来说,卷积神经网络(CNNs)已经被证明是一种有效的模型,在图像识别,分割,检测和检索等方面都取得了最好的效果。在这些结果背后最关键的因素是网络的规模变得越来越大,参数越来越多和大量的有标签的数据集来支持我们的学习过程。在这些条件下,CNNs已经表现出了很强的学习能力和表现图片的特征。在图像领域好的结果的激励下,我们研究了CNNs在大规模视频分类上的性能,我们的网络不仅能够在单一的、静止的图片上表现出很好的性能,而且在复杂的时间域有进展。这里有一些挑战是延伸和应用CNNs在视频数据集上。
从实践的观点来说,现在还没有可以匹配当前图片数据集那样规模和变化多样的标准的视频分类数据集,因为视频更加的难于收集、标注和存储。为了得到足够多的数据来训练我们的CNN结构,我们收集了一个新的Sports-1M数据集,这个数据集由一百万个属于487个不同类别的YouTube视频组成。我们公开了这个数据集,这个领域的研究团体可以用它来支持他们将来的工作。
从模型的角度来说,我们对于回答下面的问题感兴趣:怎样的时间域的连通性可以更好的利用视频中表现出的局部运动信息?增加的运动信息如何影响CNN的预测?这个影响到底有多大的提升?我们通过评价多种不同的CNN结构、每种结构运用不同的方法合并时间域的信息来探究这些问题。
从计算的观点来说,CNNs需要很就的训练时间来有效的优化这百万级的参数。当扩展到时间域的连通性时,我们进一步的混合就更加困难了,因为这个网络处理的不仅仅是一幅图片了,而是视频的一次很多帧。为了缓和这个问题,我们用有效的方法来加速运行时间,通过改变CNNs的结构包括两个分离的处理流程:context stream在低分辨率的帧上学习特征和高分辨率的fovea stream,只在帧的中间部分操作。我们发现在运行时间上有2到4倍的的提升,因为减少了输入的维度。
最后,一个自然的问题就是在Sport-1M数据集上学习到的特征在其他数据集上是否有较好的泛化能力。我们研究了迁移学习的问题,有很好的表现(从41.3%增加到65.4%),在UCF101数据集上通过保留在Sport-1M上训练的低层特征而不是重新训练整个网络。此外,因为在UCF101数据集上只有一部分的类别是关于运动的,我们对于迁移学习能够量化相关的提升在两种设定下。
我们的贡献可以总结如下:
1、我们提出了大量的试验分析,在多种方法上将CNNs延伸到大规模数据集的视频分类上(我们公开了数据集),报道了巨大的收获,在强壮的基于特征的基底有所收获。
2、我们强调了一种结构,将输入处理成两种不同的分辨率--一个低分辨率的context stream和一个高分辨率的fovea stream,一种能够提升运行速度而且不损失精度。
3、我们应用我们的网络在UCF101数据集,得到了最好的效果。
2.相关工作:标准的视频分类方法涉及三个主要的阶段:第一,局部视觉特征描述了视频的一个区域,提取密集的或者稀疏的兴趣点。第二,得到的特征融合成一个固定尺寸大小的视频级的描述子。一个流行大方法是,用学习到的K-means字典来量子化所有的特征,根据时空的变化位置累积视频的视觉单词成直方图。第三,在视觉单词的结果上训练一个分类器(SVM)类区分感兴趣的视觉类别。
卷积神经网络是一个生物激励的类别的深度学习模型,它用一个简单的、一个训练好的端到端的、从原始像素值到分类输出的神经网络取代了上面的三个步骤,图像的稀疏结构明确的利用规则化通过限制层之间的(局部滤波器)连接、参数共享(卷积)和特殊局部不变建立神经元(max pooling)。因此,这些结构有效的转换需求工程,从特征设计和累积策略到设计网络连接结构和超参数选择。由于计算限制,CNNs直到现在已经被应用到相对较小规模的图像识别问题(MNIST,CIFAR10/100,NORB,Caltech-101/256),但是GPU硬件的提升能够使CNNs应用到大规模网络参数,这反过来推动了图像分类、目标检测、场景标示、室类分割等的巨大提升。此外,通过大规模网络在ImageNet数据集上学习到的特征在很多图像识别的数据集上都有很好的表现,用一个SVM分类器,甚至不需要fine-tuning。
相比图像数据领域,把CNNs用在视频分类上还是相对较少的。我们推测是因为在视频分类上我们没有一个相对较大的标准数据集,因为CNNs在图像领域所有的成功应用都共享一个相对较大的训练数据集。特别的,我们常用的数据集(KTH,Weizmann,UCF Sports,IXMAS,Hollywood 2,UCF-50),只包含很少的视频片段和很少的固定的类别。甚至是我们能够获得最大的数据集,例如CCV(9317个视频,20个类别)和目前介绍的UCF-10(13320个视频片段,101个不同的类别)再跟图像数据集比较起来也是相对较小的。尽管有这些限制,一些将CNNs扩展到视频领域也在不断的探索。一些人通过将时间和空间为视为平等的维度作为输入,将CNN应用到视频上。他们将这些拓展视为一种可能的泛化。非监督的训练时空特征的学习模型也在发展,基于卷积限制玻尔兹曼机和独立子空间分析(ISA)。相反,我们的模型是通过监督的方式训练一个端到端的模型。
3.模型:不想图像能够复制和重采样到一个固定的尺寸那样,视频在时间上变化广泛,我们不能够很简单的用一个固定的尺寸结构来处理它们。在这个工作中,我们我们把每一个视频都看作是一个小的、固定尺寸的片段。因为每一片段包含连续的几帧,我们可以在时间维上扩展网络的连通,用来学习时空特征。具体的做法有很多种选择,我们描述三种连通的模式(早期融合、晚期融合、慢融合)。然后,我们描述了一种多分辨率的结构用来解决计算的效率。
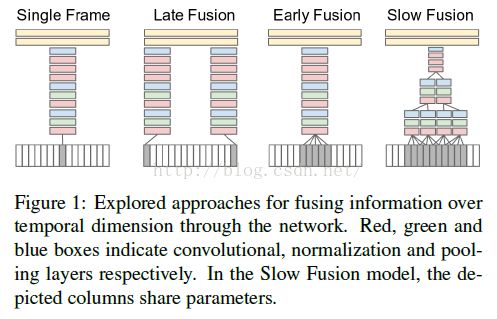
3.1在CNN中融合时间信息:
我们探讨了几种不同的融合时间域信息的方法:可以在网络的早期通过修改第一层的卷积滤波器来扩展到时间维进行融合,或者可以先通过单独的处理两个网络,后面在输出的时候融合它们。我们首先描述一个基线,单帧的CNN,然后讨论怎么根据不同的融合方法把它扩展到实践维上。
Single-frame.我们用一个单帧的基本结构来理解静态的表现对分类精度的影响。这个网络的结构和ImageNet挑战的胜利者的结构相似,但是接受的输入的尺寸是170*170*3像素,而不是原始的224*224*3。用速记的符号,整个结构是C(96,11,3)-N-P-C(256,5,1)-N-P-C(384,3,1)-C(384,3,1)-C(256,3,1)-P-FC(4096)-FC(4096),C(d,f,s)表示卷积层有d个滤波器、每个滤波器的大小为f*f,步长为1应用到输入上。FC(n)表示全连接层有n个节点。所有的池化层P池化空间在一个2*2的非重叠区域,所有的正则化层N在【11】描述,用相同的参数:k=2,n=5,@=0.0001,b=0.5。最后的层上连接一个softmax分类器。
Early Fusion:早期的融合扩展合并信息在一开始的像素级上贯穿所有时间窗。这个的实施通过修改单帧模型的第一层上的滤波器,延伸它们的尺寸大小11*11*3*T像素,T表示时间的持续。早期的、直接的连接到像素数据能够使网络精确的检测到局部运动的方向和速度。
Late Fusion:晚期融合模型用两个分离的单帧网络(如上面所描述的),一直到最后的卷基层C(256,3,1),相邻的15帧共享参数,然后在第一个全连接层上融合两路。因此,两个单帧的顶部都不能检测任何的运动信息,但是第一个全连接层能够通过比较两个顶部的输出计算全局的运动信息。
Slow Fusion:慢融合模型是一种混合两种方法的权衡,它在整个网络上缓慢的融合时间信息,这样高层就会慢慢的得到更多的时空维度上的信息。这个结构的实施是通过扩展所有卷积层的连接到时间维上,在空间维上加上时间维卷积层来计算激活值。在我们所用的模型中,第一个卷积层,每一10帧的输入,滤波器的时间维扩展T=4,步长为2,产生4个响应。第二层和第三层的T=2,步长为2。因此,第三个卷积层能够获得素有10帧输入的信息。
3.2多分辨率CNNs:
因为CNNs在大规模数据集上训练通常需要花费几周的时间,甚至是在一个快速的GPU上,对于我们实验(不同的结构和超参数)来说,运行时间性能是一个关键的部分。这激励了在保证他们的性能的同时来加速我们的模型。前面有很多的努力工作,包括提升硬件、权值量化机制、更好的优化算法和初始化策略,但是在这项工作中,我们集中精力在改变结构上,在不牺牲性能的情况下,这能够加快运行时间。
一种加快网络速度的方法是减少层数和每一层的神经元数,但是我们发现这会降低网络的性能。我们进一步的用低分辨率的图像进行试验,而不是减少网络的大小。然而,这加快了网络的运行时间,图像的高频的细节被证明是实现好的精确度的关键。
Fovea and context streams:提出的多分辨率结构目的是在于应对在两个分辨率空间中两个独立的处理过程。一个178*178帧视频切片形成了网络的输入。context stream接收一个原始分辨率一半(89*89像素)的采样,然而,fovea stream接收中间的89*89的区域在原始分辨率上。这样,总共的输入维度减半。显著地,这种设计利用了在很多在线视频所表现的相机的偏置,因为感兴趣的物体通常在中间区域。
Architecture changes:这两个处理流程有相同的网络,但是开始在视频的89*89。因为输入是全帧模型的空间大小的一半,我们取出最后一个pooling层来确保两个流程在层大小为7*7*256上终止。两个流程的激活值用密集连接的方式串联,流入到第一个全连接层。
3.3Learning:
优化:我们用随机梯度下降来优化我们的模型。每一个模型的复制品的个数在10到50之间变化,每一个模型进一步划分成4到32个部分。我们用小批的(32个样本),冲量为0.9、权值衰减0.005。所有的模型初始化学习速率为0.001,当验证误差停止提升的时候,这个值进一步的通过手工的方法减小。
Data augmentaton and preprocessing:我们利用增加数据来减少过拟合。在通过网络之前,我们处理所有的图像,首先复制中间的部分,把他们的尺寸变成200*200像素,随机采样170*170的区域,最后以50%的概率随机轻弹图像的水平方向。这些预处理步骤应用到所有帧。在最后一步,我们从原始像素中减去一个常值117,这大约是我们的所有图片的所有像素的平均值。