导语 | Elasticsearch(下文简称ES) 是当前热门的开源全文搜索引擎,利用它我们可以方便快捷搭建出搜索平台,但通用的配置还需要根据平台内容的具体情况做进一步优化,才能产生令用户满意的搜索结果。下文将介绍对 ES 搜索排名的优化实践,希望与大家一同交流。文章作者:曹毅,腾讯应用开发工程师。
一、引言
虽然使用 ES 可以非常方便快速地搭建出搜索平台,但搜出来的结果往往不符合预期。因为 ES 是一个通用的全文搜索引擎,它无法理解被搜索的内容,通用的配置也无法适合所有内容的搜索。所以 ES 在搜索中的应用需要针对具体的平台做很多的优化才可以达到良好的效果。
ES 搜索结果排序是通过 query 关键字与文档内容计算相关性评分来实现的。想掌握相关性评分并不容易。首先 ES 对中文并不是很友好,需要安装插件与做一些预处理,其次影响相关性评分的因素比较多,这些因素可控性高,灵活性高。
下文将为大家介绍 ES 搜索排名优化上的实践经验,本篇文章示例索引数据来自一份报告文档,如下图所示:

二、优化 ES Query DSL
构建完搜索平台后,我们首先要进行 ES Query DSL 的优化。针对 ES 的优化,关键点就在于优化 Query DSL,只要 DSL 使用恰当,搜索的最终效果就会很好。
1. 最初使用的 multi_match
当我们构建好索引同步好数据以后,想比较快实现全文索引的方式就是使用 multi_match 来查询,例如:

这样使用非常方便和快速,并且实现了全文搜索的需求。但是搜索的结果可能不太符合预期。但是不用担心,我们可以继续往下优化。
2. 使用 bool 查询的 filter 增加筛选
在应用中,我们应该避免直接让用户针对所有内容进行查询,这样会返回大量的命中结果,如果结果的排序稍微有一点出入,用户将无法获取到更精准的内容。
针对这种情况,我们可以给内容增加一些标签、分类等筛选项提供给用户做选择,以达到更好的结果排名。这样搜索时被 ES 引擎评分的目标结果将会变少,评分的抖动影响会更小。
实现这个功能就使用到 bool 查询的过滤器。bool 查询中提供了4个语句,must / filter / should / must_not,其中 filter / must_not 属于过滤器,must / should 属于查询器。关于过滤器,你需要知道以下两点:
- 过滤器并不计算相关性评分,因为被过滤掉的内容不会影响返回内容的排序;
- 过滤器可以使用 ES 内部的缓存,所以过滤器可以提高查询速度。
这里需要注意:虽然 must 查询像是一种正向过滤器,但是它所查询的结果将会返回并会和其他的查询一起计算相关性评分,因此无法使用缓存,与过滤器并不一样。
一般一个文档拥有多个可以被筛选的属性,例如 id、时间、标签、分类等。为了搜索的质量我们应该认真地对文档进行打标签和分类处理,因为一旦选择了过滤,即使用户的搜索关键词再匹配文档也不会被返回了。示例 Query DSL 如下:

上面的示例中,存在一个小技巧,即使用标签的 id 来进行筛选。因为 tags 字段是text 类型的,term 查询是精确匹配,不要将其应用到 text 类型的字段上,如果text字段要被过滤器使用,在 mappings 中应该要使用 string 类型(它将字段映射到两个类型上,text 和 keyword )或者 keyword 类型。
3. 使用 match_phrase 提高搜索短语的权重
在这个阶段,搜索的时候经常会出现搜索结果和搜索关键词不是连续匹配的情况。例如搜索关键词为:“2020年微信用户研究报告”,而返回的结果大多数是匹配“微信”、“用户”、“研究”、“报告”这些零散的关键词,而用户想要匹配整个短语的结果却在后面。
这并不是 ES 的 bug,在了解这种行为之前,我们需要先弄清楚 ES 是如何处理match 的?
首先 multi_match 会把多个字段的匹配转换成多个 match 查询组合,挨个对字段进行 match 查询。match 执行查询时,先把查询关键词经过 search_analyzer 设置的分析器分析,再把分析器得到的结果挨个放进 bool 查询中的 should 语句,这些 should 没有权重与顺序的差别,并且只要命中一个should 语句的文档都会被返回。转换语句如下图所示,前面是原语句,后面是转换后的语句:

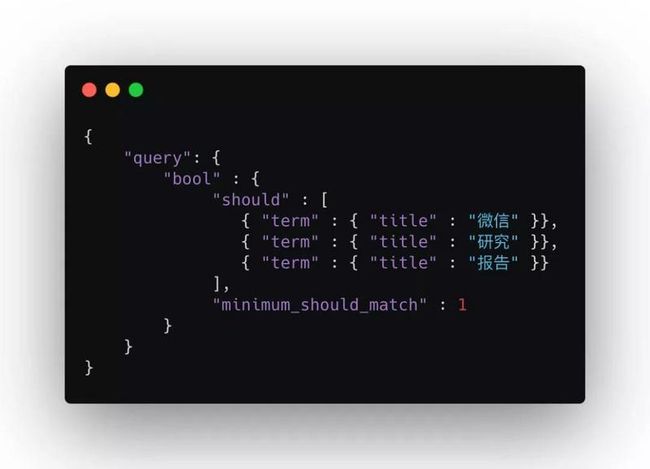
这样就导致了有的文档只拥有查询短语中若干个词,但评分却比可以匹配整个短语的文档高的情况。那我们如何考虑词的顺序呢?先别急,我们再来看看 ES 中的倒排索引。
我们都知道倒排索引中记录了一个词到包含词文档的 ID,但倒排索引当然不会这么简单。倒排列表中记录了单词对应的文档集合,由倒排索引项组成。倒排索引项中主要包含如下信息:
- 文档ID:用于获取文档;
- 单词词频(TF):用于相关性计算(TF-IDF,BM25);
- 位置:记录单词在文档中的分词位置,会有多个,用于短语查询;
- 偏移:记录在文档中的开始位置与结束位置,用于高亮。
这下我们就很清楚了,ES 专门记录了词语的位置信息用于查询,在DSL中是使用 match_phrase 查询。match_phrase 要求必须命中所有分词,并且返回的文档命中的词也要按照查询短语的顺序,词的间距可以使用 slop 设置。
match_phrase 虽然帮我们解决了顺序的问题,但是它要求比较苛刻,需要命中所有分词。如果单独使用它来进行搜索,会发现搜索出来的结果相比 match 会大大减少,这是因为匹配若干个词的文档和匹配顺序不对的文档都没被返回。
这时候可以采用 bool 查询的 should 语句,同时使用 match 与 match_phrase 查询语句,这样相当于 match_pharse 提高了搜索短语顺序的权重,使得能够顺序匹配到的文档相关性评分更高。如下是示例DSL:
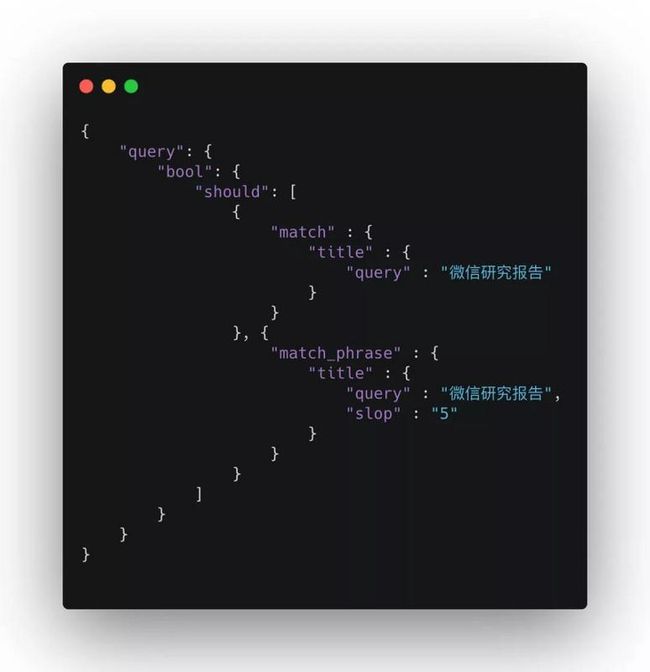
这里有一点需要注意,在倒排索引项中 text 类型的数组里,每个元素记录的位置是连续的。例如某文档数据中的 tags:["腾讯CDC","京东研究院”],“CDC” 与“京东”的位置是连续的,如果搜索 “CDC京东”,那此文档的评分将会比较高。
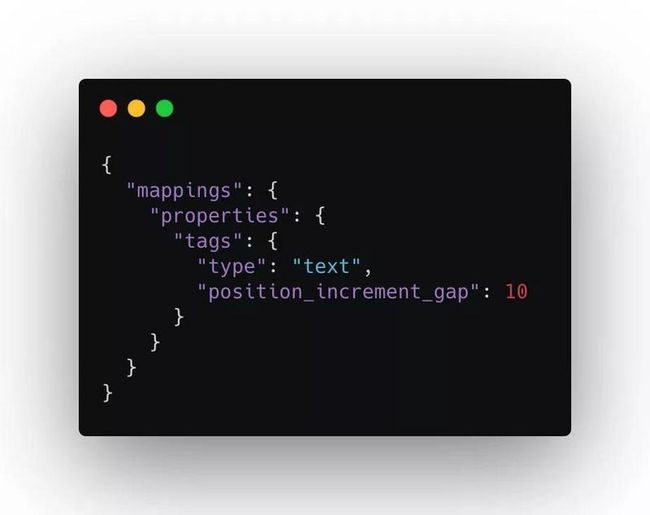
这种情况是不应该发生的,我们应该在设置索引mappings时,给 tags 字段设置上 position_increment_gap ,来增加数组元素之间的位置,此位置要超过查询所使用的 slop,例如:
4. 使用 boost 调整查询语句的权重
前文提到的搜索实现,有一个显而易见的问题:所有字段都无权重之分。根据常识我们知道,title 的权重应该高于其他字段,显然不能和其他字段是一样的得分。
查询时可以用 boost 配置来增加权重,不过这里设置的对象并不是某个字段,而是查询语句。设置后,查询语句的得分等于默认得分乘以 boost。
设置 boost 有几个需要注意的地方:
- 数据质量高的字段可以相应提高权重;
- match_phrase 语句的权重应该高于相应字段 match 查询的权重,因为文档中按顺序匹配的短语可能数量不会太多,但是查询关键词被分词后的词语将会很多,match的得分将会比较高,则 match 的得分将会冲淡 match_phrase 的影响;
- 在 mappings 设置中,可以针对字段设置权重,查询时不用再针对字段使用 boost 设置。
具体示例 DSL 如下:

5. 使用 function_score 增加更多的评分因素
影响文档评分的还有一些因素,例如我可能会经常考虑以下问题:
- 时间越近的文档信息比较及时,对用户更有用,应该排在前面;
- 平台中热门的文档,可能用户比较喜欢,应该比其他文档好;
- 文档质量比较高的,更希望让用户看到,那些缺失标签与摘要的文档并不希望用户总是看到;
- 运营人员有时候想让用户搜到正在推广的文档;
- ……
我们可以通过增加更多的影响报告评分的因素来实现以上场景,这些因素包括:时间、热度、质量评分、运营权重等。
这些因素有一个特点,就是在数据搭建阶段我们就能确定其权重,并且和查询关键词没有什么关系。这些文档本身就具有的权重属性我们可以认为是静态评分,需要和查询关键词来计算出的相关性评分称为动态评分,所以一个文档的最终评分应该是动态评分与静态评分的结合。
静态评分相关的属性不应该随便设置。为了给用户一个更好的体验,静态评分的影响应该具有:
- 稳定性:不要经常有大幅度的变动,如果大幅度变化会导致用户搜索相同的关键词过段时间出来的结果会不同;
- 连续性:方便我们其他的优化也能影响总评分,例如对于热度 0.1 与 1000 的文档,即使用户搜索 0.1 热度文档的匹配度为 1000 热度文档的 100 倍,但结果排名依然比不过 1000 热度的文档;
- 区分度:在连续稳定的情况下,应该有一定的区分度,也即分值的间隔应该合理。如果有 1000 份文档,在 1.0 分到 1.001 分之间,这其实是没有实际意义的,因为对文档排名的影响太少了。
新增加的这些因素并没有太通用的查询语句,不过 ES 提供了 function_score 来让我们自定义评分计算公式,也提供了多种类型方便我们快速应用。function_score 提供了五种类型
- script_score,这是最灵活的方式,可以自定义算法;
- weight,乘以一个权重数值;
- random_score,随机分数;
- field_value_factor,使用某个字段来影响总分数;
- decay fucntion,包括gauss、exp、linear三种衰减函数。
因为类型比较多,下面只介绍使用较多的 filed_value_factor 与 decay function 的实际案例。
(1)filed_value_factor
热度、推荐权重等对评分的影响可以按权重相乘,刚好适合 filed_value_factor 这种类型的函数,实现如下:

上面这段 DSL 的含义是:sqrt (1.2 * doc['likes'].value),如果缺失了此字段则为1。missing 这里的设置有个小技巧,比如假定缺失摘要的文档为质量低的文档,可以适当降低权重,那我们可以把 missing 设置为小于1的数值,factor 填 1 即可。
(2)decay function
衰减函数是一个非常有用的函数,它可以帮我们实现平滑过渡,使距离某个点越近的文档分数越高,越远的分数越低。使用衰减函数很容易实现时间越近的文档得分就越高的场景。
ES提供了三个衰减函数,我们先来看一下这三种衰减函数的差别,截取官方文档展示图如下:

- linear,是两条线性函数,从直线和横轴相交处以外,评分都为0;
- exp,是指数函数,先剧烈的衰减,然后缓慢衰减;
- guass,高斯衰减是最常用的,先缓慢再剧烈再缓慢,scale相交的点附近衰减比较剧烈。
当我们想选取一定范围内的结果,或者一定范围内的结果比较重要时,例如某个时间、地域(圆形)、价格范围内,都可以使用高斯衰减函数。高斯衰减函数有4个参数可以设置
- origin:中心点,或字段可能的最佳值,落在原点 origin 上的文档评分 _score 为满分 1.0 ;
- scale:衰减率,即一个文档从原点 origin 下落时,评分 _score 改变的速度;
- decay:从原点 origin 衰减到 scale 所得的评分 _score ,默认值为 0.5 ;
- offset:以原点 origin 为中心点,为其设置一个非零的偏移量 offset 覆盖一个范围,而不只是单个原点。在范围 -offset <= origin <= +offset 内的所有评分 _score 都是 1.0 。
假定搜索引擎中三年内的文档会比较重要,三年之前的信息价值降低,就可以选择 origin 为今天,scale 为三年,decay 为 0.5,offset 为三个月,DSL 如下:

6. 最终结果
到这里我们的 Query DSL 已经优化的差不多了,现在的搜索结果终于可以让人满意了。我们来看一下最终的DSL语句示例:(示例并非实际运行的代码)
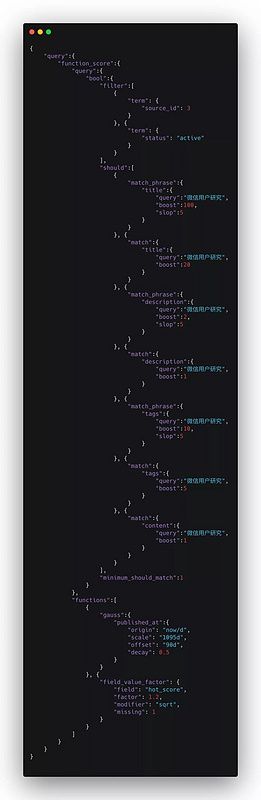
三、优化相关性算法
上文我们讨论了相关性评分应该由动态评分和静态评分结合得出,静态评分我们已经有了优化的方法,下文我们再来讨论一下动态评分的计算。
所谓动态评分,就是用户每次查询都要计算用户查询关键词与文档的相关性,更细一点来说,就是实时计算全文搜索字段的相关性。
ES 提供了一种非常好的方式,实现了可插拔式的配置,允许我们控制每个字段的相关性算法。在 Mappings 设置阶段,我们可以调整 similarity 的参数并给不同的字段设置不同的 similarity 来达到调整相关性算法的目的。ES 提供了几种可用的 similarity,我们接下来主要讨论 BM 25。
ES 默认的相关性算法就是 BM25,它是一个基于概率模型的词与文档的相关性算法,可以看做是基于向量空间模型的 TF-IDF 算法的升级。ES 在7.0.0版本已经废弃了 TF-IDF 算法,完全使用 BM25 替换,BM25 与 TF-IDF 算法的对比和细节本文不描述。
先来看看 wikipedia 上 BM25 的公式:


一眼看上去有这么多变量,是不是觉得难以理解?不过不用担心,我们需要调整的参数其实只有两个。这些变量里除了 k1 与 b ,其余都是可以直接从文档中算出的,所以在 ES 中 BM25 公式其实就是靠调整这两个参数来影响评分。
k1 这个参数控制着词频结果在词频饱和度中的上升速度。默认值为 1.2 。值越小饱和度变化越快,值越大饱和度变化越慢。词频饱和度可以参看下面官方文档的截图,图中反应了词频对应的得分曲线,k1 控制 tf of BM25 这条曲线。
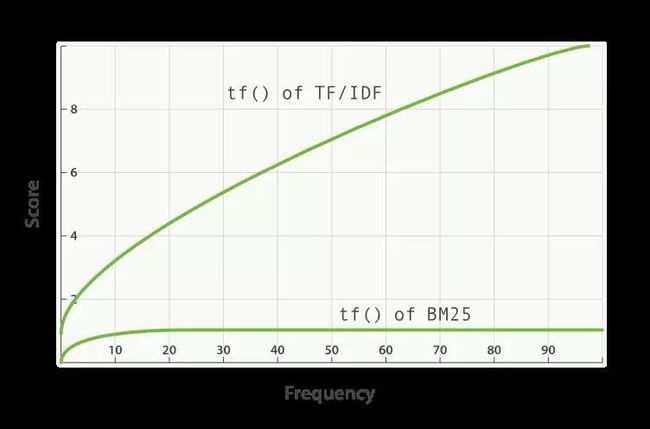
b 这个参数控制着字段长归一值所起的作用, 0.0 会禁用归一化, 1.0 会启用完全归一化。默认值为 0.75 。
在优化 BM25 的 k1 和 b 时,我们要根据搜索内容的特点入手,仔细分析检索的需求。
例如在示例的索引数据中 content 字段的质量参差不齐,甚至有些文档可能会缺失此字段,但此文档对应的真实数据(可能是某文件、某视频等)质量很高,因此放入 ES 中 content 字段的长度并不能反映文档真实的情况,更不希望 content 短的文档被突出,所以我们要弱化文档长度对评分的影响。
根据 k1 和 b 的描述,我们将 BM25 模型中的 b 值从默认的 0.75 降低,具体降低到多少才合适,还需要进一步的尝试。这里我以调整到 0.2 为例,写出对应的 settings 和 mappings :

k1 和 b 的默认值适用于绝大多数文档集合,但最优值还是会因为文档集不同而有所区别,为了找到文档集合的最优值,就必须对参数进行反复修改验证。
四、优化的建议
对 ES 搜索的优化应该把大部分精力花在文档数据质量提升和查询 DSL 组合调优上,需要反复尝试各种查询的组合和调整权重,在 DSL 的优化已经达到较好程度之前,尽量不要调整 similarity。
更不要在初期就引入太多的插件,例如近义词,拼音等,这样会影响你的优化,它们只是提高搜索召回率的工具,并不一定会提高准确率。更专业的平台应该做好更专业的搜索引导与建议,而不是让用户盲目的去尝试搜索。
搜索的调优也不能一直关注技术方面,还要关注用户。搜索质量的好坏是一个比较主观的评价,想要了解用户是否满意搜索结果,只能通过监测搜索结果和用户的行为,例如用户重复搜索的频率,翻页的频次等。
如果搜索能返回相关性较高的文档,用户应该会在第一次搜索便得到想要的内容,如果返回相关性不太好的结果,用户可能会来回点击并尝试新的搜索条件。
五、使用 _explain 做 bad case 分析
到这里,我们的搜索排名优化就告一段落,但可能时不时还会有一些用户反馈搜索的结果不准确。虽然有可能是用户自身不会使用搜索引擎(这里应该从产品上引导用户写出更好的查询关键词),但更多时候应该还是排名优化没有做好。
所以如果发现了 bad case,我们应该记录这些 bad case ,从这些问题入手仔细分析问题出在哪里,然后慢慢优化。
分析 bad case 可以使用 ES 提供的 _explain 查询 api,它会返回我们使用某 DSL 查到某文档的得分细节,通过这些细节,我们就能知道产生 bad case 的原因,然后有针对性的下手优化了。
六、结语
ES 是一个通用型的全文检索引擎,如果想用 ES 搭建一个专业的搜索平台,必须要经过搜索调优才可以达到可用的状态。本文总结了基于 ES 的搜索优化,主要是优化 DSL 与相关性计算,希望读者可以从中学习到有用的知识。
看腾讯技术,学云计算知识,来云+社区: https://cloud.tencent.com/developer