如果你的系统不是采用一个大而全的设计( monolithic ), 不管是现在流行的微服务(microservices)还是其他, 就涉及到进程间通讯。机器之间的交流和人与人之间的交流一样,诸多的问题就会扑面而来。
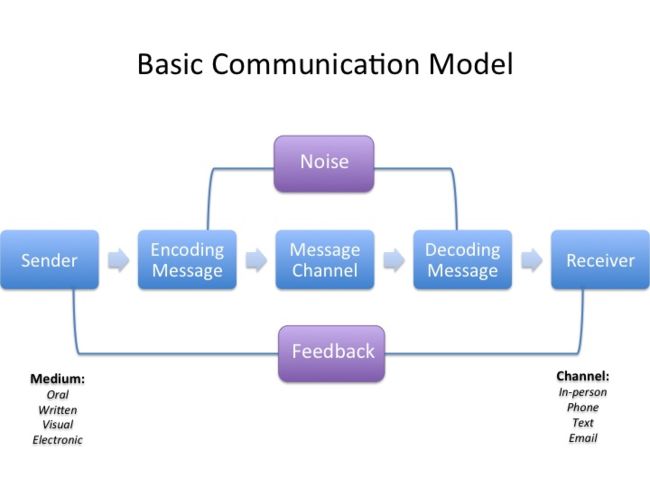
从一个发送者(客户端)到接受者(服务器),之间会掺和进各种因素, 比如人与人之间交流的噪音,不同文化背景等等,在进程间进行通讯有同样的问题:
- 通讯的格式
- 服务的注册和发现
- 同步还是异步
- 平衡(Balance)模式
- 备选方案
所以在万不得已的情况下, 不要选择RPC解决方案, 如需要,一要谨慎选择开放有限的服务, 二是否有其他的解决方案,比如RESTful API 风格, 使用RPC 风格在我们业务中是个比较合适的解决方案, 可以参考以前的文章关于DDD设计风格的架构。 所以在Command 端,可以理解只有POST 请求的 HTTP API, 比较适合用RPC 特别对于并发比较大的应用。 如果集合现有的架构和通讯网络基础架构, 能够以最小的代价引入RPC, 可以说是个不错的选择。
如果将上面一般的信息交流过程,映射到rpc 可以得到下面的图形:
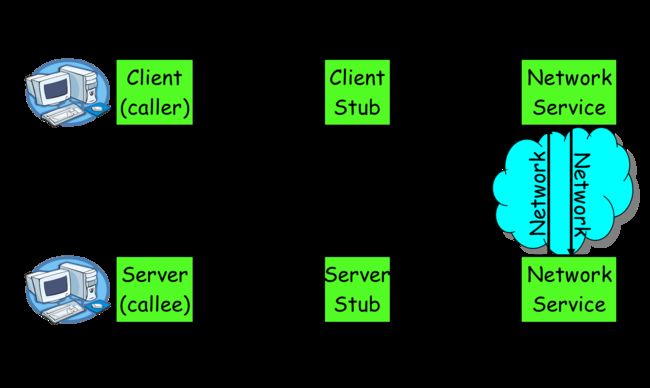
基本的模块功能也非常的容易理解,但是在实际的操作中还有诸多的细节需要考虑, 现在市面上也有很多成熟的解决方案。 如阿里巴巴的dubbo(开源)、Facebook的thrift(开源)、Google grpc(开源)、Twitter的finagle(开源)等。
其实在我们的系统中,有部分使用grpc 作为gateway 转送外围请求到内部系统,但是在一些模块中还是使用了自己定制的rpc框架。
整个框架参考了 luxiaoxun/NettyRpc & fixio - FIX Protocol Support for Netty 和 Dubbo 等设计思想和原理, 在3天左右的工作时间里实现了基础的代码和测试, 带入测试环境。
当然这个架构的设计有大量为本应用定制的元素,不一定适合所有用类。
需求
- 和DDD 紧密集合,面向Command 端, Event 自然走MQ走不在讨论范围内。
- 一套内部的序列化方式
- 基于Netty
- 提供服务有限精简,非CRUD 这样的操作(参考DDD设计思想)
- 无侵入性
参考前面基本介绍DDD 设计基本文章,我们整个交易系统采用了此设计架构,DDD 中的aggregate root 作为触发状态变化的核心元素, 将 domain 中触发状态改变的command 转换成事件分发出去;这一层对外提供操作服务,所以这部分是我们需要改造的部分。
为了维护高可用性和高并发性, 这层首先需要做partition, 但是不能replication, 因为一个aggregate root 在全局中只能有单个线程在运作, 所以其实是带状态的。也就是在同一个时间,一个aggregate root 只能在一台机器,一个线程中被操作。
这让服务器端和客户端协调都带来很棘手的问题, 理论提供一个带parition 的MQ 比如KAFKA 就可以解决这个问题。
这确实是我们第一个版本的实现方案(其实第二个,开始有个其他的rpc 解决方案),能够很好的满足需求, 比如我们对唯一组件的 account id 作为partition 的key将请求分发到kafka(需要保证kafka 的partition 和你节点上面parition算法一致), 服务端监听就可以了:
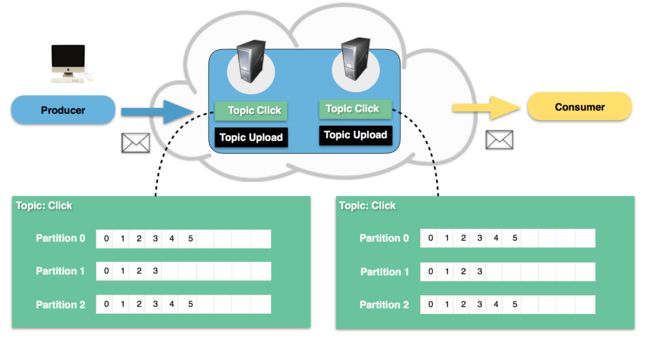
有了这个中间层, 可以很好的解耦各系统之间的关联, 多一个中间的跳转有性能上的稍微损耗,而且kafka 没有很好的transaction 支持,但是这个方案可以是很好的 failover backup 方案。
下面的服务的注册和发现, 将提供一个解决方案如何在rpc 下保证服务端和客户端保持一致。
网络通讯层
基于Netty 大部分的问题已近解决, 有先前使用netty 解决其他网络通讯层的问题,所以比较容易解决。基本就是一个固定流程:参考 luxiaoxun/NettyRpc
final ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast("tagDecoder", new LengthFieldBasedFrameDecoder(4069, 0, 4, 0, 0)); //Size is 4k at most
pipeline.addLast("rpcDecoder", new SBERpcDecoder());
pipeline.addLast("rpcEncoder", new SBERpcEncoder());
pipeline.addLast("pingPong", new PingPongHandler()); // process pingPong
if (application != null) {
pipeline.addLast("app", application); // process application events events
}
唯一需要定制的就是你的 Decoder 和 Encoder 和你的Application 层用。
由于我们这里使用的是 SBE 序列化方式, 所以这部分是定制的, 这里要注意SBE 默认编码是 Little Endian 还是 Big Endian 编码格式, 是否和Netty 默认冲突。
后面接的是你的Application 层应用,这一次是避免加入RPC 对原有价格的侵入控制点, 我们这里是分发到进程内Command Bus(基于disruptor)。所以这里RPC 必须都是异步调用, 需要根据一个request id(UUID, 或者为一个sequence) 回调---如果需要返回结果的话。 Command Bus 不介意一个Command 是从RPC 还是 MQ 还是 HTTP 请求来。
注 RPC异步 vs 同步:

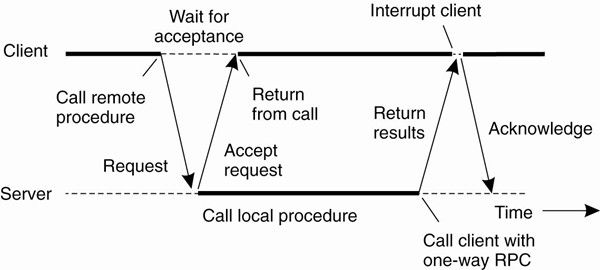
我们这里的返回结果,完全通过另外一个通道,所以这里不涉及,如果需要回调可以看 luxiaoxun/NettyRpc 设计方式。
业务层
也就是处理Command Business Logic 部分,对于发送过来的command 需要是一个DDD风格的Command:
- 包含一个Aggregate Root Identifier, 也就是唯一标示一个物体的, 比如人的account Id, 一个产品的booker Id 等。
- 一个全局统一的partition 算法。
- 一个标准的SBE 兼容消息
比如一个简单的创建账号的请求(command)
@SBEMessage(id = 800, desc = "Create Portfolio Account")
public class CreatePortfolioCommand {
private static final long serialVersionUID = -8206695527451683906L;
@TargetAggregateIdentifier
@FieldType(index = 999, type = "AccountId", id = 999)
protected AccountId accountId;
@FieldType(index = 1, type = "int64", id = 1)
protected long userId; //this may pass by frontend
@FieldType(index = 2, type = "double", id = 2)
protected double credit;
@FieldType(index = 3, type = "VARCHAR8", id = 3, presence = Presence.OPTIONAL)
protected String vendor;
}
一个Message 包含:
short domain;
long timestamp;
long sequence;
int part;
Object payload;
int id;
- domain 一个short 标注来自那个domain, 自己知道就可以,理论一个应用domain 个数不会超过百把个,否则太复杂了!
- timestamp 消息发送的时间戳
- sequence 一个客户端维护的sequence,服务器不检查重复,回调时候用
- part: Domain Command 属于那个partition
- payload 消息体
- id: 消息id 也就是上面SBEMessage 的id
为什么消息上面要带partition, 下面的服务注册和发现 还会再做说明,所以需要一个统一的客户端和服务器端的partition 算法。
为什么要带消息的id?几个作用:
- 路由
- 避免服务端和客户端的stub 代码, 无需IDL、XML语言去描述你的服务
- 无侵入性
只要在Application 层,套一薄薄层,路由到内部的Command Bus, 但是有个缺点就是内部必须有完善的文档, 知道每个服务器端能接受什么类型的服务,也就是那些类型message Id 支持,否则过来会在Application无情过滤掉。
对应Application 到业务层的Adapter:
@FunctionalInterface
public interface CommandHandler {
/**
* Handler for specific command
*
* @param command, the payload
* @param part, which partition
* @param sequence, the sequence like version may the command need to be fail detected
* @param timestamp, the time message newed
* @throws Exception
*/
void handle(final T command,
final int part,
final long sequence,
final long timestamp) throws Exception;
}
服务注册和发现
上面我们反复强调, partition 一致性的重要性,这里可以揭晓为什么这样设计。
DDD设计方式, Domain 无疑是整个架构的核心, 其实一个Object 都可以称为一个Aggregate Root; 维护这个对象状态变更, 比如一个账号对象(Account), 有基本的属性, 比如account Id, cash, credit, position等等, 有对这个对象的不同的操作:充值、取款、加仓、平仓、调整信用度等等, 这些自然的作为一个命令(Command)发送给这个对象。 为了维护这个对象状态一致性, 必须保证单线程操作!这个在单机还容易实现,但是对于集群环境呢?
对 account id 进行partition 分区, 在集群机器上,一个partition只能位于一台机器上。 比如对 account ID 分成32个partition, 理论可以支持最多32台机并行处理对account 的所有请求, 如果现在有两台机器, A & B, 他们分别得到partition:
A: 1,4,8,10,11,13,17,19,20,22,24,27,29
B: 0,2,3,5,6,7,9,12,14,15,16,18,21,23,25,26,30,31
如果错误将一个partition 为0 的账号请求发送到 A 机器上面将导致处理被拒绝。 虽然机器A 可以从Event source 将这个账号replay 出来, 但是由于性能优化, replay 出来的Domain 是做本地缓存的, 同样snapshot 和 event source 也是缓存,这样可能导致 domain 恢复错误。
但是一旦发生re-balance? 比如0 partition 从 A 移动到B, 这个时候会把A 中, partition 为 0 domain 相关所有数据刷入DB, 在 re-balance 结束前, partition 0 上命令可能失败。
这就导致一个问题,服务注册要带上自己的IP+Port+Partitioins.
服务发现端,同样需要根据不同partition 发送到对应的服务器端。
注册和发现服务使用redis, 服务器端在感知partition 发生变化后, 会刷到redis 一个map 上面(带TTL),然后双方一个消息到topic上, 同时定时刷行当前parition 到redis上面。
客户端直接监听和定时poll 这个map 就可以:
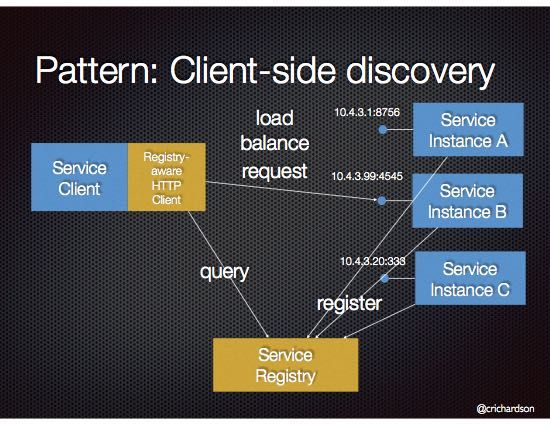
更多服务注册发现方法可以参考 Dubbo 的实现
所以我们这里的实现是个特别的 load balance ,其他一些load balance 可以参考同样Dubbo 的实现
测试
不考虑落地数据, 单机测试可以满足据大部分的性能需求。当然这个离上线还是比较远, 需要考虑re-balance 情况下有parittion 不可用, 所以我们这里还是有failover 方案, 在服务不可得情况下是发送到 mq 中,还待长时间进一步检验。
参考
- Remote procedure call
- Pattern: Client-side service discovery
- tang-jie/NettyRPC
- luxiaoxun/NettyRpc
- 你应该知道的RPC原理
- fixio - FIX Protocol Support for Netty
- onixs FIX Engine
- RPC Slide
- RPC课件
- What are the pros and cons of REST versus RPC?
- WEB开发中,使用JSON-RPC好,还是RESTful API好?