原文 http://tecdat.cn/?p=3232
我们最近有一个很棒的机会与一位伟大的客户合作,要求Business Science构建一个适合他们需求的开源异常检测算法。业务目标是准确地检测各种营销数据的异常情况,这些数据包括跨多个客户和Web源跨越数千个时间序列的网站操作和营销反馈。输入anomalize:一个整洁的异常检测算法,该算法基于时间(建立在之上tibbletime)并可从一个到多个时间序列进行扩展!我们非常高兴能够为其他人提供这个开源R软件包以使其受益。在这篇文章中,我们将概述anomalize它的作用和方式。
案例研究:当开源利益调整时
我们与许多教授数据科学的客户合作,并利用我们的专业知识加速业务发展。然而,很少有客户的需求和他们愿意让其他人受益于我们推动数据科学界限的利益。这是一个例外。
我们的客户遇到了一个具有挑战性的问题:按时间顺序检测每日或每周数据的时间序列异常。异常表示异常事件,可能是营销域中的Web流量增加或IT域中的故障服务器。无论如何,标记这些不寻常的事件以确保业务顺利运行非常重要。其中一个挑战是客户处理的不是一个时间序列,而是需要针对这些极端事件进行分析。
我们有机会开发一个开源软件包,该软件包符合我们的兴趣,即构建Twitter AnomalyDetection软件包的可扩展版本,以及我们的客户希望获得一个可以从开源数据科学社区随着时间的推移而改进的软件包的愿望。结果是anomalize!!!
anomalize
对于我们这些喜欢阅读的人来说,这里有anomalize四个简单步骤的工作要点。
第1步:安装Anomalize
install.packages("anomalize")
第2步:加载Tidyverse和Anomalize
library(tidyverse)
library(anomalize)
第3步:收集时间序列数据
我们提供了一个数据集,tidyverse_cran_downloads以帮助您启动和运行。该数据集包括15“tidyverse”包的每日下载次数。
tidyverse_cran_downloads
## # A tibble: 6,375 x 3
## # Groups: package [15]
## date count package
##
## 1 2017-01-01 873. tidyr
## 2 2017-01-02 1840. tidyr
## 3 2017-01-03 2495. tidyr
## 4 2017-01-04 2906. tidyr
## 5 2017-01-05 2847. tidyr
## 6 2017-01-06 2756. tidyr
## 7 2017-01-07 1439. tidyr
## 8 2017-01-08 1556. tidyr
## 9 2017-01-09 3678. tidyr
## 10 2017-01-10 7086. tidyr
## # ... with 6,365 more rows
第4步:异常化
使用三个整齐的功能:time_decompose(),anomalize(),并time_recompose()及时发现异常情况。 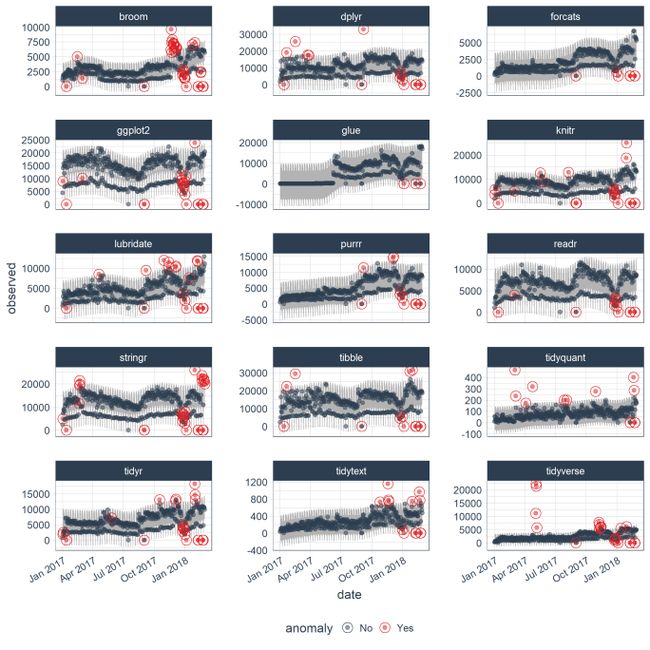
异常工作流程
您刚刚实施了“异常检测”(异常检测)工作流程,其中包括:
- 用时间序列分解 time_decompose()
- 用余数检测余数的异常 anomalize()
- 异常下限和上限转换 time_recompose()
时间序列分解
第一步是使用时间序列分解time_decompose()。“计数”列被分解为“观察”,“季节”,“趋势”和“剩余”列。时间序列分解的默认值是method = "stl",使用黄土平滑器进行季节性分解(参见stats::stl())。的frequency和trend参数是基于使用所述时间序列的时间尺度(或周期性)自动设置tibbletime在引擎盖下基于函数。
## # A time tibble: 6,375 x 6
## # Index: date
## # Groups: package [15]
## package date observed season trend remainder
##
## 1 tidyr 2017-01-01 873. -2761. 5053. -1418.
## 2 tidyr 2017-01-02 1840. 901. 5047. -4108.
## 3 tidyr 2017-01-03 2495. 1460. 5041. -4006.
## 4 tidyr 2017-01-04 2906. 1430. 5035. -3559.
## 5 tidyr 2017-01-05 2847. 1239. 5029. -3421.
## 6 tidyr 2017-01-06 2756. 367. 5024. -2635.
## 7 tidyr 2017-01-07 1439. -2635. 5018. -944.
## 8 tidyr 2017-01-08 1556. -2761. 5012. -695.
## 9 tidyr 2017-01-09 3678. 901. 5006. -2229.
## 10 tidyr 2017-01-10 7086. 1460. 5000. 626.
## # ... with 6,365 more rows一个很好的方面是,frequency并trend自动为您选择。如果要查看所选内容,请进行设置message = TRUE。此外,您可以通过输入基于时间的周期(例如“1周”或“2个季度”)来更改选择,这通常更直观,可以确定有多少观察属于时间跨度。引擎盖下,time_frequency()以及time_trend()基于时间段将这些使用数值tibbletime!
余数的异常检测
下一步是对分解的数据执行异常检测,特别是“余数”列。我们使用了这个anomalize(),它产生了三个新列:“remainder_l1”(下限),“remainder_l2”(上限)和“异常”(是/否标志)。默认方法是method = "iqr",在检测异常时快速且相对准确。alpha默认情况下alpha = 0.05,该参数设置为,但可以调整该参数以增加或减少异常频段的高度,从而使数据更难或更难以变得异常。max_anoms默认情况下,该参数设置为max_anoms = 0.2可能异常的20%数据的最大值。这是可以调整的第二个参数。最后,verbose = FALSE默认情况下返回一个数据框。尝试设置verbose = TRUE 以列表的形式获取异常值报告。
## # Groups: package [15]
## package date observed season trend remainder remainder_l1
##
## 1 tidyr 2017-01-01 873. -2761. 5053. -1418. -3748.
## 2 tidyr 2017-01-02 1840. 901. 5047. -4108. -3748.
## 3 tidyr 2017-01-03 2495. 1460. 5041. -4006. -3748.
## 4 tidyr 2017-01-04 2906. 1430. 5035. -3559. -3748.
## 5 tidyr 2017-01-05 2847. 1239. 5029. -3421. -3748.
## 6 tidyr 2017-01-06 2756. 367. 5024. -2635. -3748.
## 7 tidyr 2017-01-07 1439. -2635. 5018. -944. -3748.
## 8 tidyr 2017-01-08 1556. -2761. 5012. -695. -3748.
## 9 tidyr 2017-01-09 3678. 901. 5006. -2229. -3748.
## 10 tidyr 2017-01-10 7086. 1460. 5000. 626. -3748.
## # ... with 6,365 more rows, and 2 more variables: remainder_l2 ,
## # anomaly如果你想想象正在发生的事情,现在尝试另一个绘图功能是一个好点plot_anomaly_decomposition()。它只适用于单个时间序列,因此我们只需选择一个即可查看。“季节”正在消除每周的循环季节性。趋势是平滑的,这对于消除集中趋势而不过度拟合是合乎需要的。最后,分析剩余部分以检测最重要的异常值的异常。
tidyverse_cran_downloads %>%
# Anomalize
time_decompose(count, method = "stl", frequency = "auto", trend = "auto") %>%
anomalize(remainder, method = "iqr", alpha = 0.05, max_anoms = 0.2) %>%
# Plot Anomaly Decomposition
plot_anomaly_decomposition() +
ggtitle("Lubridate Downloads: Anomaly Decomposition")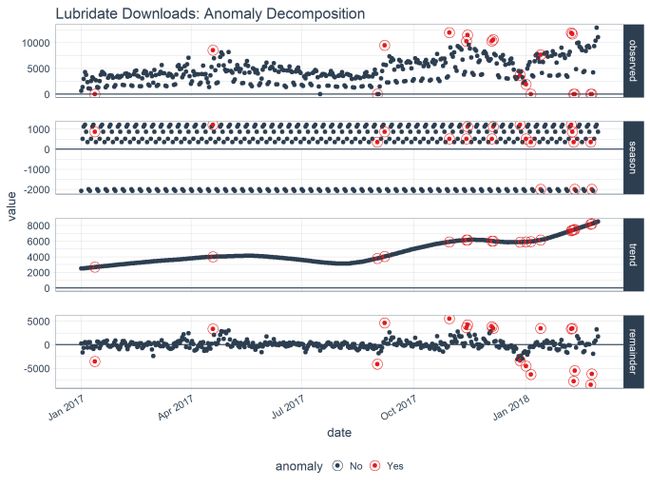
异常下限和上限
最后一步是围绕“观察”值创建下限和上限。这是工作time_recompose(),它重新组合观察值周围的异常的下限和上限。创建了两个新列:“recomposed_l1”(下限)和“recomposed_l2”(上限)。
## # A time tibble: 6,375 x 11
## # Index: date
## # Groups: package [15]
## package date observed season trend remainder remainder_l1
##
## 1 tidyr 2017-01-01 873. -2761. 5053. -1418. -3748.
## 2 tidyr 2017-01-02 1840. 901. 5047. -4108. -3748.
## 3 tidyr 2017-01-03 2495. 1460. 5041. -4006. -3748.
## 4 tidyr 2017-01-04 2906. 1430. 5035. -3559. -3748.
## 5 tidyr 2017-01-05 2847. 1239. 5029. -3421. -3748.
## 6 tidyr 2017-01-06 2756. 367. 5024. -2635. -3748.
## 7 tidyr 2017-01-07 1439. -2635. 5018. -944. -3748.
## 8 tidyr 2017-01-08 1556. -2761. 5012. -695. -3748.
## 9 tidyr 2017-01-09 3678. 901. 5006. -2229. -3748.
## 10 tidyr 2017-01-10 7086. 1460. 5000. 626. -3748.
## # ... with 6,365 more rows, and 4 more variables: remainder_l2 ,
## # anomaly , recomposed_l1 , recomposed_l2让我们看一下“lubridate”数据。我们可以使用plot_anomalies()和设置time_recomposed = TRUE。此功能适用于单个和分组数据。
time_decompose(count, method = "stl", frequency = "auto", trend = "auto") %>%
anomalize(remainder, method = "iqr", alpha = 0.05, max_anoms = 0.2) %>%
time_recompose() %>%
# Plot Anomaly Decomposition
plot_anomalies(time_recomposed = TRUE) +
ggtitle("Lubridate Downloads: Anomalies Detected")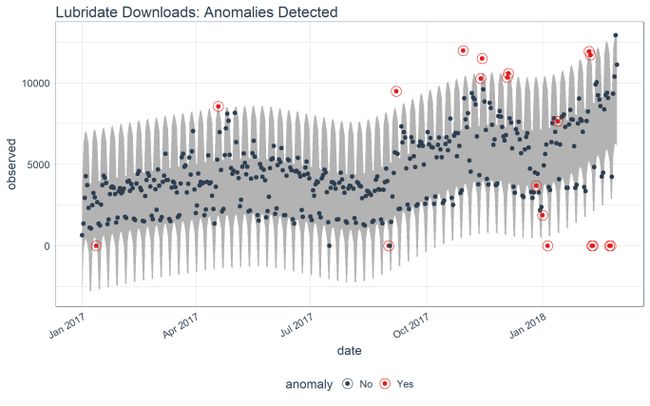
预测tsoutliers()函数
包 中的tsoutliers()功能forecast是在执行预测之前有效收集异常值以进行清洁的好方法。它使用基于STL的离群值检测方法,其具有围绕时间序列分解的余数的3X内四分位数范围。它非常快,因为最多有两次迭代来确定异常值带。但是,它没有设置整洁的工作流程。也不允许调整3X。一些时间序列可能需要更多或更少,这取决于剩余部分的方差的大小与异常值的大小的关系。
tsoutliers包
该tsoutliers软件包非常有效地用于检测异常的许多传统预测时间序列。但是,速度是一个问题,特别是在尝试扩展到多个时间序列或分钟或秒时间戳数据时。
在审查可用的软件包时,我们从中了解到所有软件包的最佳组合:
- 分解方法:我们包括两个时间序列分解方法:( "stl"使用Loess的传统季节分解)和"twitter"(使用中间跨度的季节分解)。
- 异常检测方法:我们包括两种异常检测方法:( "iqr"使用类似于3X IQR的方法forecast::tsoutliers())和"gesd"(使用Twitter使用的GESD方法AnomalyDetection)。
另外,我们对自己做了一些改进:
- Anomalize Scales Well:工作流程整洁,可与dplyr群组进行缩放。这些函数按分组时间序列按预期运行,这意味着您可以轻松地将500个时间序列数据集异常化为单个数据集。
- 用于分析异常的视觉效果:
- 我们提供了一种方法来围绕分离异常值的“正常”数据。人是视觉的,乐队在确定方法的工作方式或是否需要进行调整时非常有用。
- 我们包括两个绘图函数因此很容易看到“anomalize工作流程”期间发生了什么事,并提供一种方法来评估的“调节旋钮”驱动的影响time_decompose()和anomalize()。
- 基于时间:
- 整个工作流程使用tibbletime基于时间的索引设置数据。这很好,因为根据我们的经验,几乎所有时间数据都带有日期或日期时间戳,这对数据的特征非常重要。
- 无需计算在频率跨度或趋势跨度内有多少观测值。我们设置time_decompose()处理frequency和trend使用基于时间的跨度,例如“1周”或“2季度”(由...提供tibbletime)。
结论
我们的客户对此非常满意,看到我们可以继续构建每个人都可以享受的新功能和功能令人兴奋。
有问题欢迎下方留言!