OpenTSDB-时序数据库(更新中)
前言:
原本地址.
文章参考了OpenTSDB文档,以及其他网友的优质博客,结合自己的一些理解,也算是边学边写博客了
1. 简介
OpenTSDB(Open time series data base),时间序列数据库。顾名思义,就是以时间为标签存储数据,它的特点是能够提供最高 毫秒级精度 的时间序列数据存储,能够长久保存原始数据并且不失精度。但是OpenTSDB这个db有误导性,他其实只是一层读写服务(基于HBase)
HBase可以看我另一篇文章: HBase架构基础和结构模型.
1.1 什么是时序数据?
股票的变化趋势、温度的变化趋势、系统某个指标的变化趋势……其实都是时序数据,就是每个时间点上纪录一条数据。 关于数据的存储,我们最熟悉的就是mysql了,但是想想看,每5分钟存储一个点,一天288个点,一年就10万+,这还是单个维度,往往在实际应用中维度会非常多,比如股票交易所,成千上万支股票,每天所有股票数据就可能超过百万条,如果还得支持历史数据查询,mysql是远远扛不住的,必然要考虑分布式存储,最好的选择就是Hbase了,事实上业内基本上也是这么做的。
了解Hbase的人都知道,它可以通过加机器的水平扩展迅速增加读写能力,非常适合存储海量的数据,但是它并不是关系数据库,无法进行类似mysql那种select、join等操作。 取而代之的只有非常简单的Get和Scan两种数据查询方式。这里不讨论Hbase的相关细节,总之,你可以通过Get获取到hbase里的一行数据,通过Scan来查询其中RowKey在某个范围里的一批数据。如此简单的查询方式虽然让hbase变得简单易用, 但也限制了它的使用场景。针对时序数据,只有get和scan远远满足不了你的需求。
这个时候OpenTSDB就应运而生。 首先它做了数据存储的优化,可以大幅度提升数据查询的效率和减少存储空间的使用。其次它基于hbase做了常用时序数据查询的API,比如数据的聚合、过滤等。另外它也针对数据热度倾斜做了优化。
1.2OpenTSDB术语
metric: 指标,比如在系统监控中cpu的利用率、天气数据,温度,湿度等的变化。
timestamp: 时间戳(时间戳是指格林威治时间1970年01月01日00时00分00秒起至当下的总秒数)
在线时间戳工具网站.
tag: 标签。 比如在cpu在某个机器上的数据,就可以把机器ip作为tag打进去。
在OpenTSDB里tag是个k-v,比如 ip=192.168.0.1 就可以做为一个tag。注意
OpenTSDB最多只能打8个tag。(每个标签由tagKey和tagValue组成,tagKey和tagValue均为字符串)
value: 我们要存的时序数据的值。(64位整数或者单精度浮点数)
举个例子,在监控场景中,我们可以这样定义一个监控指标:
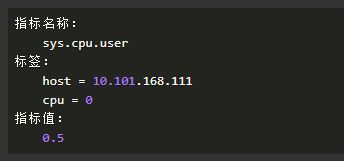
指标名称代表这个监控指标是对用户态CPU的使用监控,引入了两个标签,分别标识该监控位于哪台机器的哪个核。
OpenTSDB支持的查询场景为:指定指标名称和时间范围,给定一个或多个标签名称和标签的值作为条件,查询出所有的数据。
以上面那个例子举例,我们可以查询:
a. sys.cpu.user (host=,cpu=)(1465920000 <= timestamp < 1465923600):查询凌晨0点到1点之间,所有机器的所有CPU核上的用户态CPU消耗。
b. sys.cpu.user (host=10.101.168.111,cpu=*)(1465920000 <= timestamp < 1465923600):查询凌晨0点到1点之间,某台机器的所有CPU核上的用户态CPU消耗。
c. sys.cpu.user (host=10.101.168.111,cpu=0)(1465920000 <= timestamp < 1465923600):查询凌晨0点到1点之间,某台机器的第0个CPU核上的用户态CPU消耗。
2 数据存储优化
如果我们只通过原始的Hbase接口去存时间序列,我们可能会设计出这样的Rowkey。
metric|timestamp|tagK1:tagV1|tagK2:tagV2…

如上图是一个简单的表结构设计,rowkey采用metric name + timestamp + tags的组合,因为这几个元素才能唯一确定一个指标值。
如果我们每秒存储一个数据点,每天就有86400个数据点,在hbase里就意味着86400行的数据,不仅浪费存储空间,而且还查起来慢,所以OpenTSDB做了数据压缩上的优化,多行一列转一行多列,一行多列转一行一列。数据开始写入时其实OpenTSDB还是一行一个数据点,如果用户开启了数据压缩的选项,OpenTSDB会在一个小时数据写完或者查询某个小时数据时对其做多行转一行的数据压缩,压缩后那些独立的点数据就会被删除以节省存储空间。
2.1 优化一:缩短row key
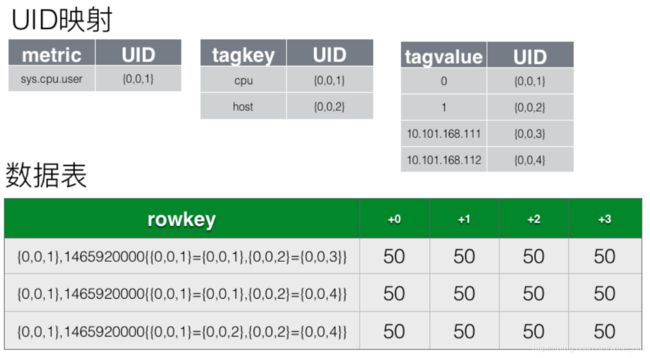
例(接上文的例子):
观察这张表内存储的数据,在rowkey的组成部分内,其实有很大一部分的重复数据,重复的指标名称,重复的标签。以上图为例,如果每秒采集一次监控指标,cpu为2核,host规模为100台,则一天时间内sys.cpu.user这个监控指标就会产生17280000行数据,而这些行中,监控指标名称均是重复的。如果能将这部分重复数据的长度尽可能的缩短,则能带来非常大的存储空间的节省。
OpenTSDB采用的策略是,为每个metric、tag key和tag value都分配一个UID,UID为固定长度三个字节。

上图为优化后的存储结构,可以看出,rowkey的长度大大的缩短了。rowkey的缩短,带来了很多好处:
a. 节省存储空间
b. 提高查询效率:减少key匹配查找的时间
c. 提高传输效率:不光节省了从文件系统读取的带宽,也节省了数据返回占用的带宽,提高了数据写入和读取的速度。
d. 缓解Java程序内存压力:Java程序,GC是老大难的问题,能节省内存的地方尽量节省。原先用String存储的metric name、tag key或tag value,现在均可以用3个字节的byte array替换,大大节省了内存占用。
2.2 优化二:减少Key-Value数
优化一是OpenTSDB做的最核心的一个优化,很直观的可以看到存储的数据量被大大的节省了。原理也很简单,将长的变短。但是是否还可以进一步优化呢?
在上面的存储模型章节中,我们了解到。HBase在底层存储结构中,每一列都会以Key-Value的形式存储,每一列都会包含一个rowkey。如果要进一步缩短存储量,那就得想办法减少Key-Value的个数。
OpenTSDB分了几个步骤来减少Key-Value的个数:
-
将多行合并为一行,多行单列变为单行多列。
-
将多列合并为一列,单行多列变为单行单列。
2.2.1 将多行合并为一行,多行单列变为单行多列。
OpenTSDB将同属于一个时间周期内的具有相同TSUID(相同的metric name,以及相同的tags)的数据合并为一行存储。OpenTSDB内默认的时间周期是一个小时,也就是说同属于这一个小时的所有数据点,会合并到一行内存储,如图上所示。合并为一行后,该行的rowkey中的timestamp会指定为该小时的起始时间(所属时间周期的base时间),而每一列的列名,则记录真实数据点的时间戳与该时间周期起始时间(base)的差值。
这里列名采用差值而不是真实值也是一个有特殊考虑的设计,如存储模型章节所述,列名也是会存在于每个Key-Value中,占用一定的存储空间。如果是秒精度的时间戳,需要4个字节,如果是毫秒精度的时间戳,则需要8个字节。但是如果列名只存差值且时间周期为一个小时的话,则如果是秒精度,则差值取值范围是0-3600,只需要2个字节;如果是毫秒精度,则差值取值范围是0-360000,只需要4个字节;所以相比存真实时间戳,这个设计是能节省不少空间的。
2.2.2 单行多列合并为单行单列
多行合并为单行后,并不能真实的减少Key-Value个数,因为总的列数并没有减少。所以要达到真实的节省存储的目的,还需要将一行的列变少,才能真正的将Key-Value数变少。
OpenTSDB采取的做法是,会在后台定期的将一行的多列合并为一列,称之为『compaction』,合并完之后效果如下。

同一行中的所有列被合并为一列,如果是秒精度的数据,则一行中的3600列会合并为1列,Key-Value数从3600个降低到只有1个。
2.3 并发写优化
上面两个优化主要是OpenTSDB对存储的优化,存储量下降以及Key-Value个数下降后,除了直观的存储量上的缩减,对读和写的效率都是有一定提升的。
时间序列数据的写入,有一个不可规避的问题是写热点问题,当某一个metric下数据点很多时,则该metric很容易造成写入热点。OpenTSDB采取了和这篇文章中介绍的一样的方法,允许将metric预分桶,可通过『tsd.storage.salt.buckets』配置项来配置。

如上图所示,预分桶后的变化就是在rowkey前会拼上一个桶编号(bucket index)。预分桶后,可将某个热点metric的写压力分散到多个桶中,避免了写热点的产生。
2.4 总结
OpenTSDB作为一个应用广泛的时间序列数据库,在存储上做了大量的优化,优化的选择也是完全契合其底层依赖的HBase数据库的存储模型。表格存储拥有和HBase一样的存储模型,这部分优化经验可以直接借鉴使用到表格存储的应用场景中,值得我们好好学习。
3 数据写入与查询API

参考资料:
OpenTSDB简介.
解密OpenTSDB的表存储优化.
OpenTSDB 中文文档.