flink
-
简介
是一个框架和分布式处理处理引擎,用于对无界和有界数据流进行状态计算。
低延迟,高吞吐,结果正确性和良好的容错性。 -
应用场景:

-
流处理演变:

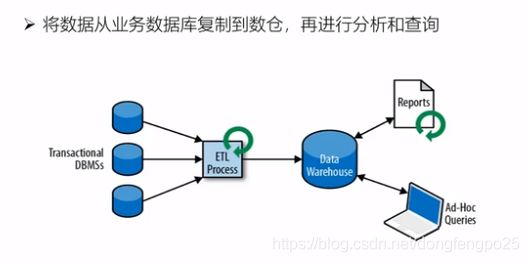
离线大数据事务图如下:
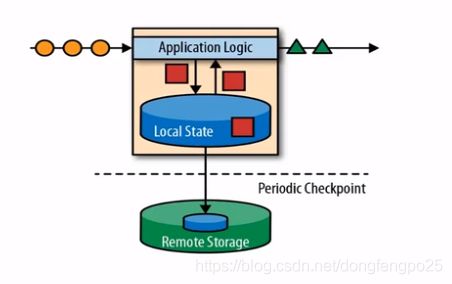
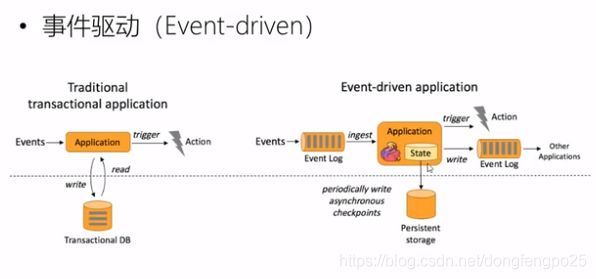
有状态的流式处理:
如sum统计,数据仍然是流进来,流出去,但可以保存一个求和的本地状态,存储在内存里,再写入到远程的存储空间里,落盘,为flink的检查点概念。
但在分布式,高并发情况下一致性不好,可能网络延迟,乱序,不能保证数据的一致性。但如果隔一段时间再处理,数据应该都齐了,才能保证一致性。所以批处理如下:
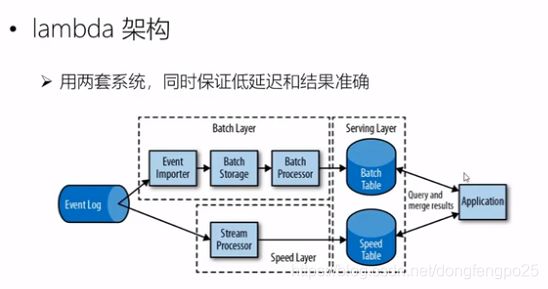
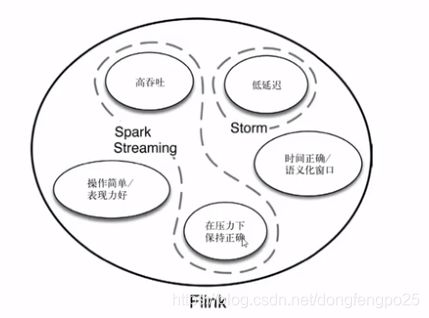
上面为第二代流处理,维护两套系统,批处理解决了一致性,但出现了延迟,实时性不好。第二套流处理解决了延迟问题,保证了实时性,但一致性不够好。两套配合起来解决了高吞吐,低延迟,正确性。
缺点:本来是一套系统,现在要维护两套系统,比较繁琐。api也不一样,
于是第三代流处理系统出现了:
4. flink主要特点
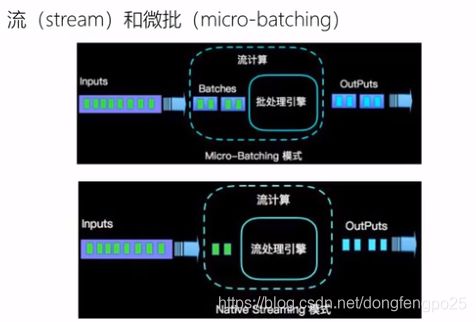
基于流的世界观:
spark是一批一批的数据,包装成RDD,然后统一做处理
flink是一切都是流,离线是有界的流,实时是无界的流。
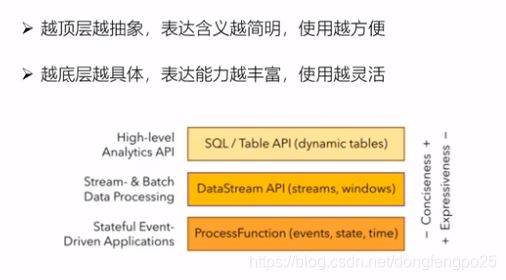
分层API
其他特点:
支持事件时间(event-time)和处理时间(processing-time)语义
精确一次(exactly-once)的状态一致性保证
低延迟,每秒处理数据百万个事件,毫秒级延迟
与众多常用存储系统的连接(kafka,es,hdfs等)
高可用,动态扩展,实现7*24小时全天候运行
- flink vs spark streaming

- 第一个例子
批处理:
package com.dong.flink
import org.apache.flink.api.scala._
/**
* 批处理
*/
object wordCount {
def main(args: Array[String]): Unit = {
//创建一个批处理的执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
//从文件中读取数据
val txtPath = "D:\\dev\\java\\ide\\scala\\ws\\flink\\flink\\src\\main\\res\\hello.txt"
val inputDataSet = env.readTextFile(txtPath)
//分词之后count统计
val wordCountDataSet = inputDataSet.flatMap(_.split(" "))
.map((_, 1)).groupBy(0).sum(1);
//打印
wordCountDataSet.print();
}
}
流处理:
package com.dong.flink
import org.apache.flink.streaming.api.scala._
/**
* 流处理
*/
object StreamWordCount {
def main(args: Array[String]): Unit = {
//创建一个流处理的执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//接收socket数据流
val textDataStream = env.socketTextStream("localhost", 7777)
//逐一读取数据,打散之后进行word count
val wordCountDataStream = textDataStream.flatMap(_.split("\\s"))
.filter(_.nonEmpty)
.map((_, 1))
.keyBy(0)
.sum(1)
//打印
wordCountDataStream.print()
//比批处理多一步骤,调用真正执行作业
//上面只是定义完成一组处理流程,未执行任务
env.execute("stream word count job")
}
}
流处理需要建立一个socket模拟流,那么可以使用nc工具,参考:
下载nc.exe工具,放入C:\windows\system32目录下
打开命令界面 cmd,输入 nc -L -p 9999
nc下载
-
运行架构




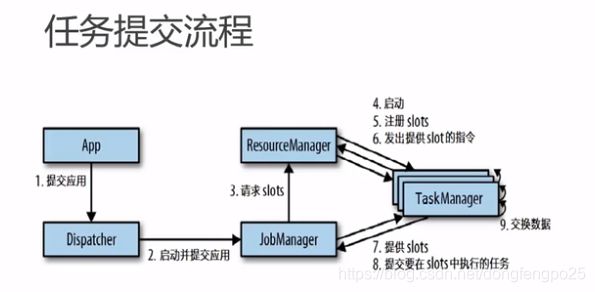
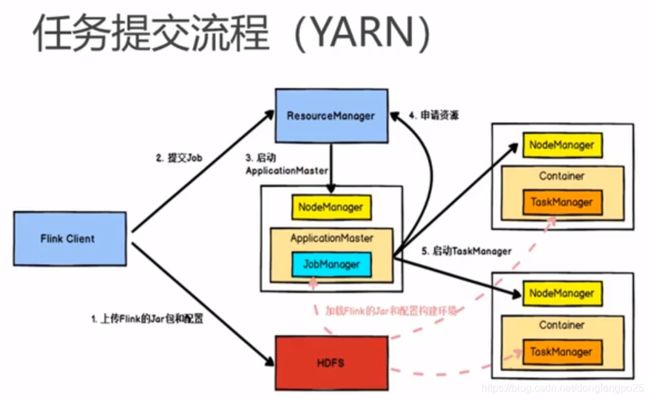
-
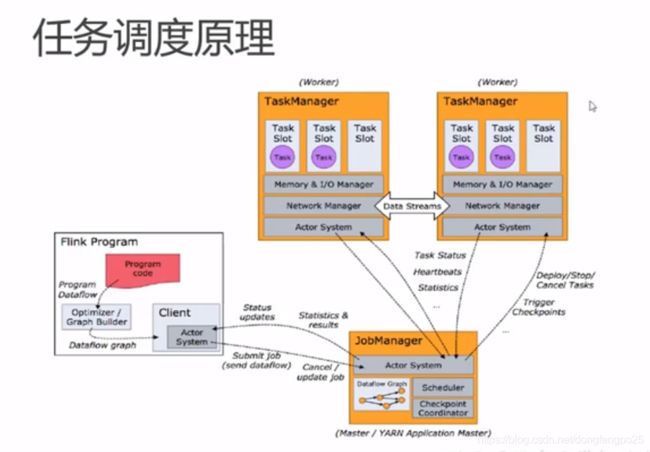
运行原理
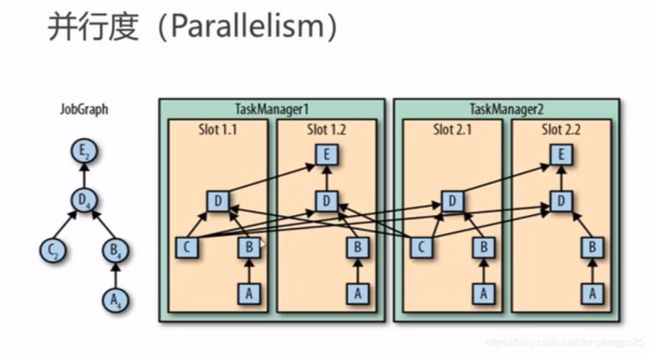
TaskManager和Slots:
Flink中每一个taskManager都是一个Jvm进程,它可能会在独立的线程上执行一个或多个subtask
为了控制一个TaskManager能接收多少个task, TaskManager通过task slot来进行控制(一个TaskManager至少有一个slot)
slot是隔离内存,cpu是可以共享的。但是共享cpu效率上需要控制,往往是按照cpu的核数来划分slot的。
默认情况下,Flink允许子任务共享slot,即使它们是不同任务的子任务。这样的结果是,一个slot可以保存作业的整个管道。
Task slot是静态的概念,是指Task Manager具有的并发执行能力。
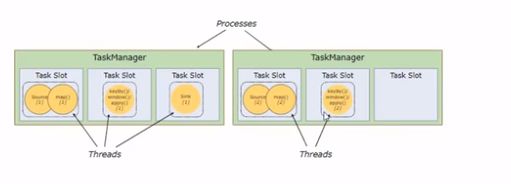
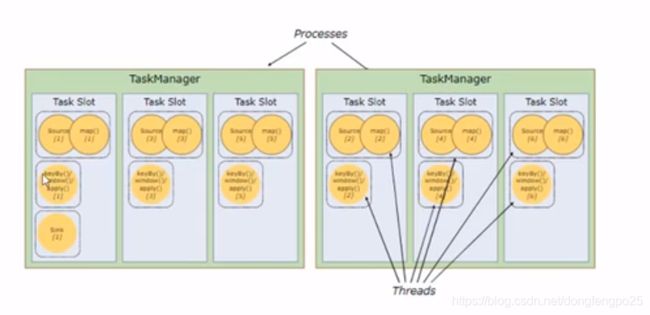
例子:
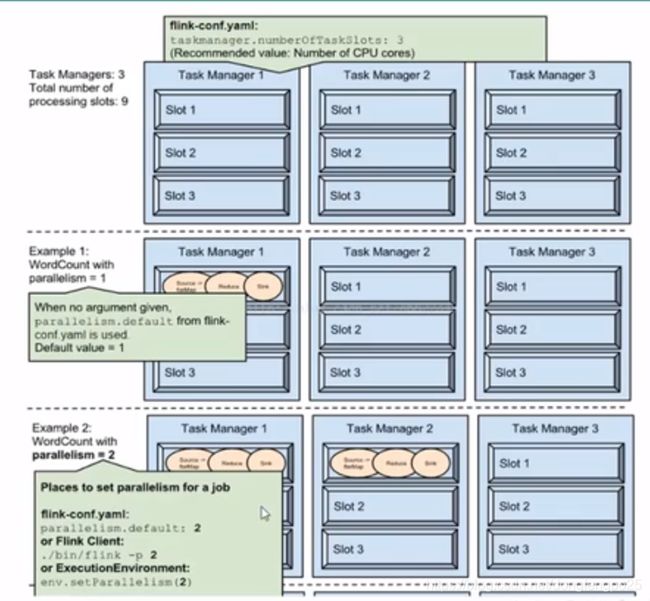
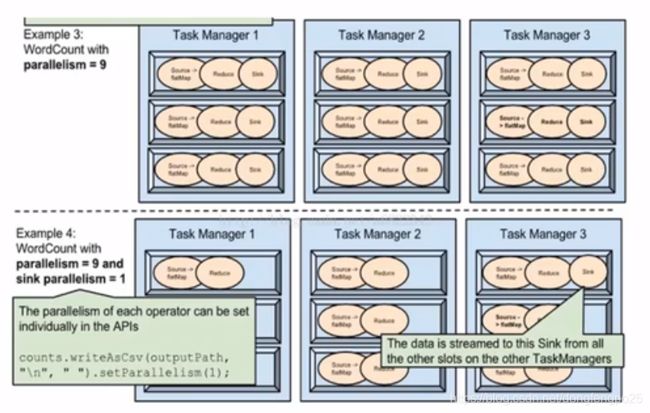
-
程序与数据流
所有的flink程序都是由三部分组成的: Source、Transformation和Sink。
Source负责读取数据源, Transformation利用各种算子进行处理加工,Sink负责输出。
在运行时,flink上运行的程序会被映射成“逻辑数据流”(dataflows),它包含了这三部分。

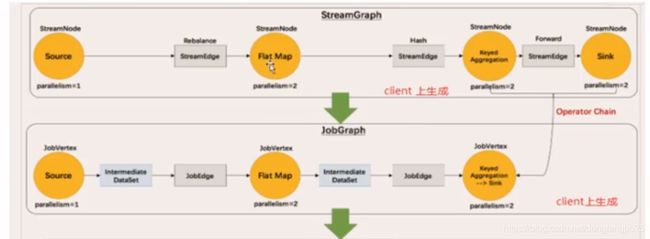

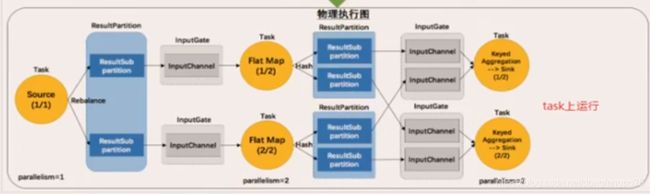
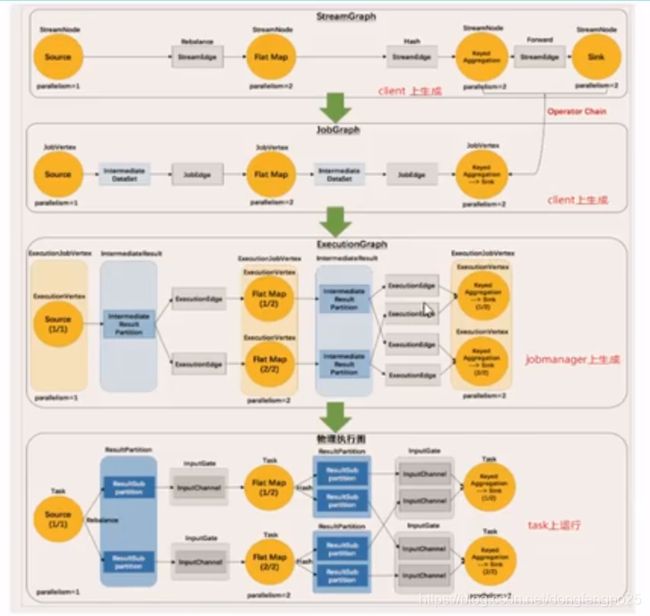
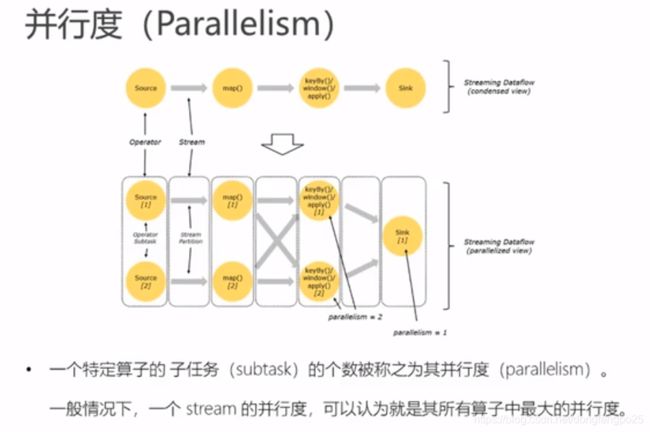


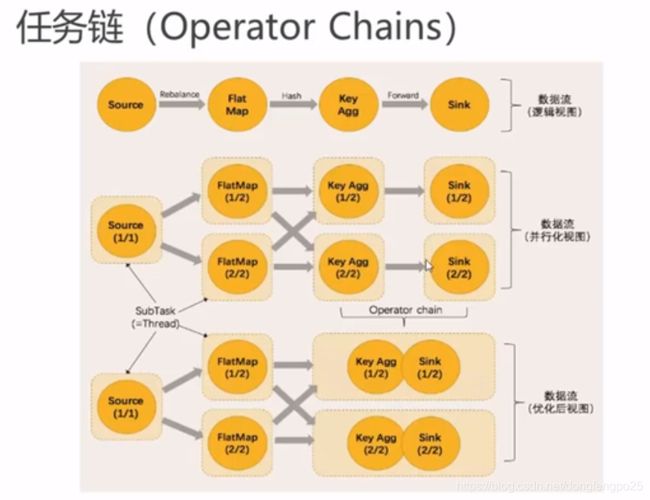
任务之间的数据传输必须要有通信的花费,而且必须要做序列化和反序列化,这个过程还是比较耗费资源的。所以优化在同一个任务链里,相当于内部的方法调用,极大的省去资源的花费。可以做operator chain。
但是如果是超大的任务,耗费资源极高的情况下,还是分散slot效果更佳。就不做operator chain。 -
控制任务算子的并行度
env.disableOperatorChaining() 禁用任务链
*.startNewChain() 强制断开任务链,启用新任务链 -
流处理API
source:
package com.dong.flink
import org.apache.flink.streaming.api.scala._
import java.util.Properties
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
//温度传感器读数样例类
//case class SensorReading(id: String, timestamp: Long, temperature: Double)
object KafkaSource {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
// val stream1 = env.fromCollection(
// List(
// SensorReading("sensor_1", 1547718199, 35.34),
// SensorReading("sensor_2", 1547718200, 15.86),
// SensorReading("sensor_3", 1547718201, 6.79),
// SensorReading("sensor_4", 1547718202, 39.04)))
//env.fromElements(1, 2.0, "abc").print();
//val stream2 = env.readTextFile("D:\\dev\\java\\ide\\scala\\ws\\flink\\flink\\src\\main\\res\\sensor.txt")
//stream2.print("stream1").setParallelism(1)
// 3. 从kafka中读取数据
// 创建kafka相关的配置
val properties = new Properties()
properties.setProperty("bootstrap.servers", "192.168.4.51:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
//FlinkKafkaConsumer自动处理数据状态一致性的保证,啥都不用做,比spark舒服的地方,它需要手动提交数据偏移量
val stream3 = env.addSource(new FlinkKafkaConsumer[String]("sensor", new SimpleStringSchema(), properties))
stream3.print("stream3").setParallelism(1)
// 4. 自定义数据源
//val stream4 = env.addSource(new SensorSource())
// sink输出
//stream4.print("stream4")
env.execute("source test")
}
}
transform:
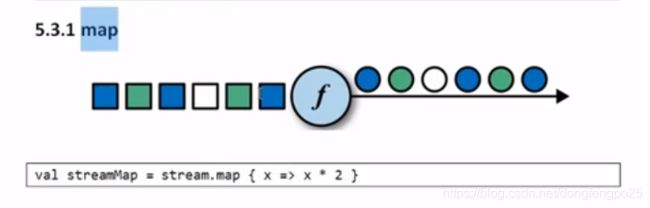

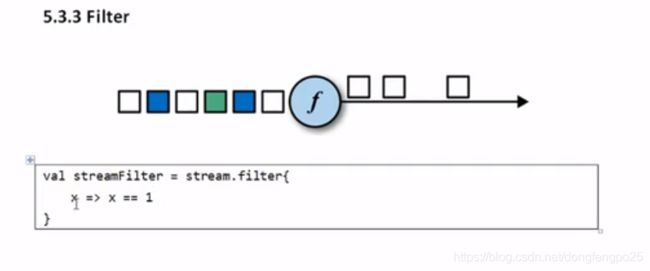
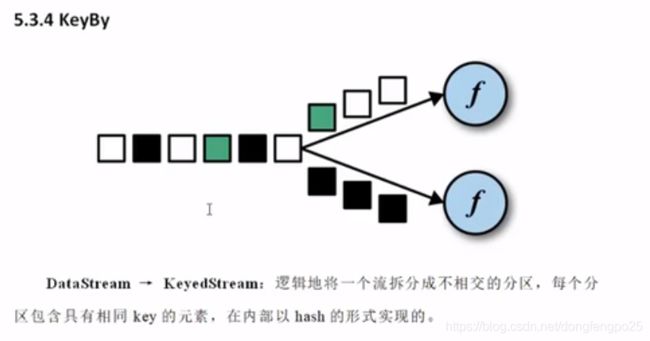
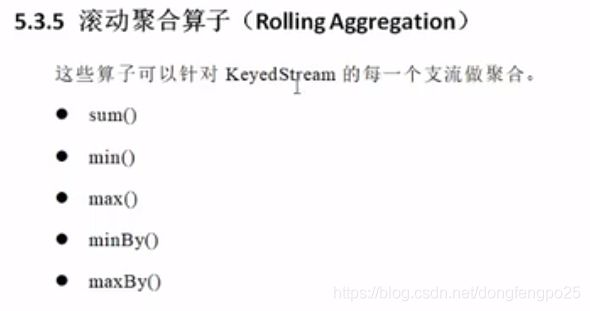
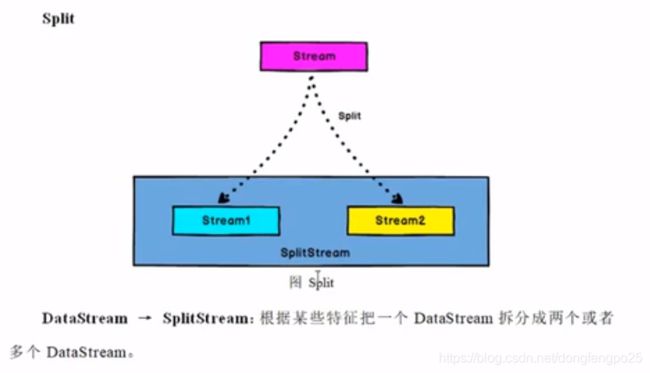
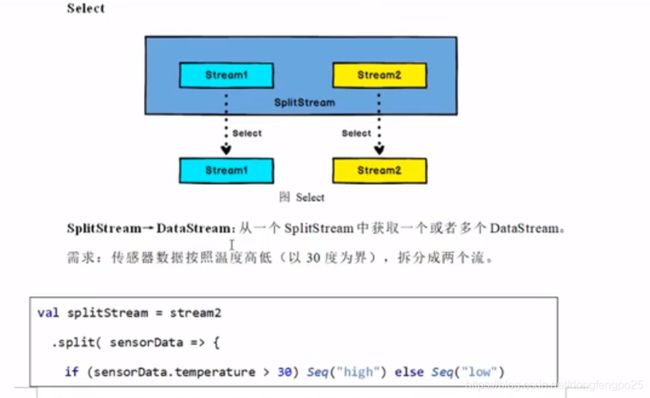
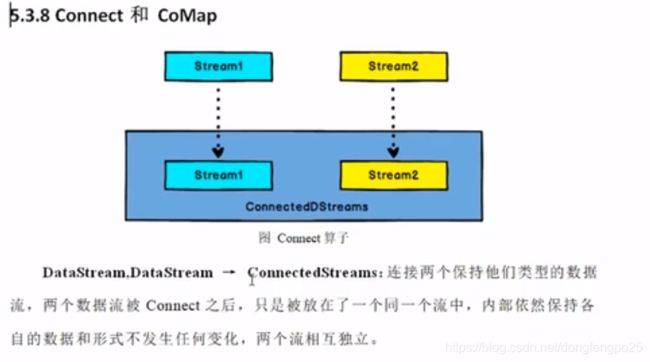
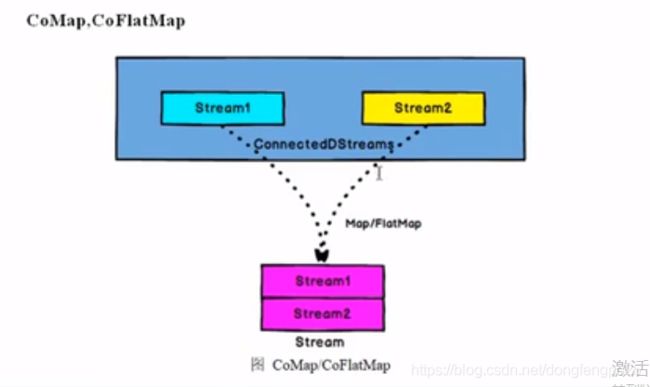
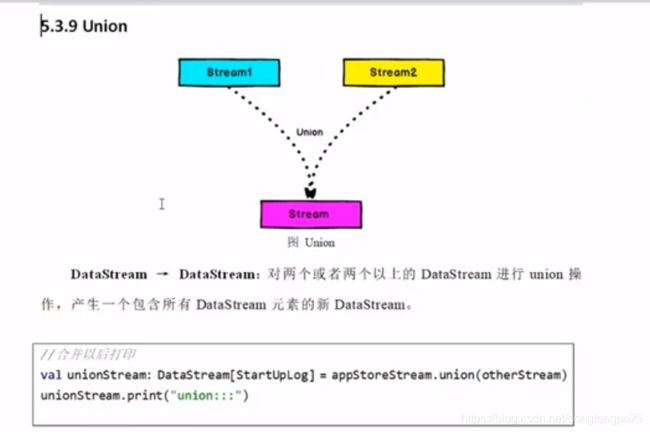

12. 函数类
class MyFilter() extends FilterFunction[SensorReading] {
def filter(v: SensorReading): Boolean = {
v.id.startsWith("sensor_1")
}
}
s1.filter(new MyFilter()).print()
//等价于
//s1.filter(_.id.startsWith("sensor_1")).print()
//等价于
//s1.filter(data => data.id.startsWith("sensor_1")).print()
富函数:
每个函数都有对应原Rich函数
FilterFunction ⇒ RichFilterFunction
有上下文,还有生命周期
13. Sink

kafka:
package com.dong.flink.sink
import org.apache.flink.streaming.api.scala._
import com.dong.flink.SensorReading
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer
import org.apache.flink.api.common.serialization.SimpleStringSchema
import java.util.Properties
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
object KafkaSinkTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
//FlinkKafkaConsumer自动处理数据状态一致性的保证,啥都不用做,比spark舒服的地方,它需要手动提交数据偏移量
val is = env.addSource(new FlinkKafkaConsumer[String]("sensor", new SimpleStringSchema(), properties))
val s1 = is.map(data => {
val array = data.split(",")
//转为String方便序列化输出
SensorReading(array(0).trim, array(1).trim.toLong, array(2).trim.toDouble).toString()
})
s1.addSink(new FlinkKafkaProducer[String]("localhost:9092", "sink", new SimpleStringSchema()))
s1.print()
env.execute("sink test")
}
}
redis:
package com.dong.flink.sink
import org.apache.flink.streaming.api.scala._
import com.dong.flink.SensorReading
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand
import org.apache.flink.streaming.connectors.redis.RedisSink
object RedisSinkTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val txtPath = "D:\\dev\\java\\ide\\scala\\ws\\flink\\src\\main\\res\\sensor.txt"
val is = env.readTextFile(txtPath)
val s1 = is.map(data => {
val array = data.split(",")
SensorReading(array(0).trim, array(1).trim.toLong, array(2).trim.toDouble)
})
val conf = new FlinkJedisPoolConfig.Builder()
.setHost("localhost")
.setPort(6379)
.build()
s1.addSink(new RedisSink(conf, new MyRedisMapper()))
s1.print()
env.execute("redis sink test")
}
}
class MyRedisMapper() extends RedisMapper[SensorReading] {
//定义保存数据到redis的命令
def getCommandDescription(): RedisCommandDescription = {
//把传感器id和温度保存成哈希表 hset key field value
new RedisCommandDescription(RedisCommand.HSET, "sensor_temperature")
}
def getKeyFromData(t: SensorReading): String = t.temperature.toString()
def getValueFromData(t: SensorReading): String = t.id
}
es:
package com.dong.flink.sink
import java.util
import org.apache.flink.streaming.api.scala._
import org.apache.flink.api.common.functions.RuntimeContext
import org.apache.flink.streaming.connectors.elasticsearch.{ElasticsearchSinkFunction, RequestIndexer}
import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink
import org.apache.http.HttpHost
import org.elasticsearch.client.Requests
import com.dong.flink.SensorReading
object EsSinkTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val txtPath = "D:\\dev\\java\\ide\\scala\\ws\\flink\\src\\main\\res\\sensor.txt"
val is = env.readTextFile(txtPath)
val s1 = is.map(data => {
val array = data.split(",")
SensorReading(array(0).trim, array(1).trim.toLong, array(2).trim.toDouble)
})
val httpHosts = new util.ArrayList[HttpHost]()
httpHosts.add(new HttpHost("localhost", 9200))
// 创建一个esSink 的builder
val esSinkBuilder = new ElasticsearchSink.Builder[SensorReading](
httpHosts,
new ElasticsearchSinkFunction[SensorReading] {
override def process(element: SensorReading, ctx: RuntimeContext, indexer: RequestIndexer): Unit = {
println("saving data: " + element)
// 包装成一个Map或者JsonObject
val json = new util.HashMap[String, String]()
json.put("sensor_id", element.id)
json.put("temperature", element.temperature.toString)
json.put("ts", element.timestamp.toString)
// 创建index request,准备发送数据
val indexRequest = Requests.indexRequest()
.index("sensor")
.`type`("readingdata")
.source(json)
// 利用index发送请求,写入数据
indexer.add(indexRequest)
println("data saved.")
}
}
)
// sink
s1.addSink( esSinkBuilder.build() )
s1.print()
env.execute("es sink test")
}
}
jdbc sink:
package com.dong.flink.sink
import java.sql.{ Connection, DriverManager, PreparedStatement }
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{ RichSinkFunction, SinkFunction }
import org.apache.flink.streaming.api.scala._
import com.dong.flink.SensorReading
object JdbcSinkTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val txtPath = "D:\\dev\\java\\ide\\scala\\ws\\flink\\src\\main\\res\\sensor.txt"
val is = env.readTextFile(txtPath)
val s1 = is.map(data => {
val array = data.split(",")
SensorReading(array(0).trim, array(1).trim.toLong, array(2).trim.toDouble)
})
s1.addSink(new MyJdbcSink())
env.execute("jdbc sink test")
}
}
class MyJdbcSink extends RichSinkFunction[SensorReading] {
// 定义sql连接、预编译器
var conn: Connection = _
var insertStmt: PreparedStatement = _
var updateStmt: PreparedStatement = _
// 初始化,创建连接和预编译语句
override def open(parameters: Configuration): Unit = {
super.open(parameters)
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "123456")
insertStmt = conn.prepareStatement("INSERT INTO temperatures (sensor, temp) VALUES (?,?)")
updateStmt = conn.prepareStatement("UPDATE temperatures SET temp = ? WHERE sensor = ?")
}
// 调用连接,执行sql
override def invoke(value: SensorReading, context: SinkFunction.Context[_]): Unit = {
// 执行更新语句
updateStmt.setDouble(1, value.temperature)
updateStmt.setString(2, value.id)
updateStmt.execute()
// 如果update没有查到数据,那么执行插入语句
if (updateStmt.getUpdateCount == 0) {
insertStmt.setString(1, value.id)
insertStmt.setDouble(2, value.temperature)
insertStmt.execute()
}
}
// 关闭时做清理工作
override def close(): Unit = {
insertStmt.close()
updateStmt.close()
conn.close()
}
}
-
flink window api
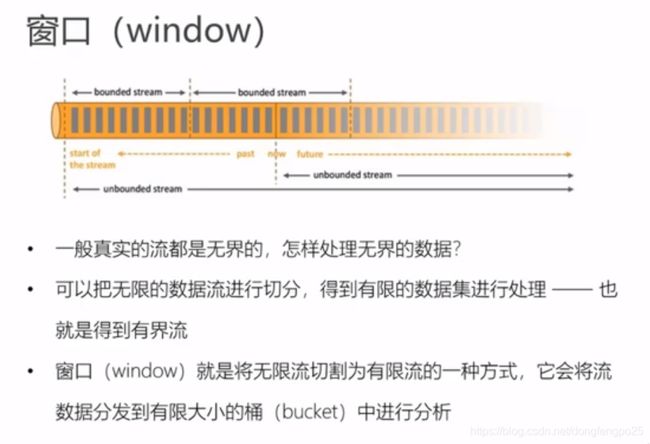



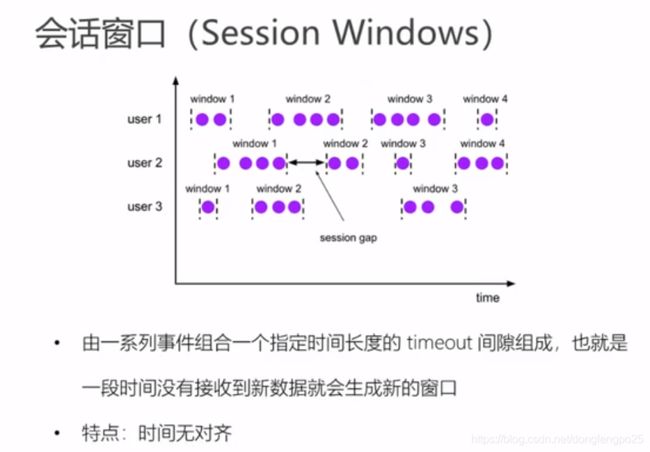





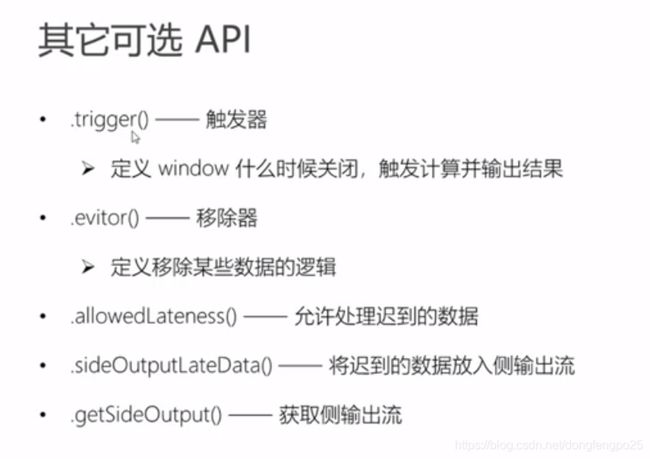

-
时间语义和watermark
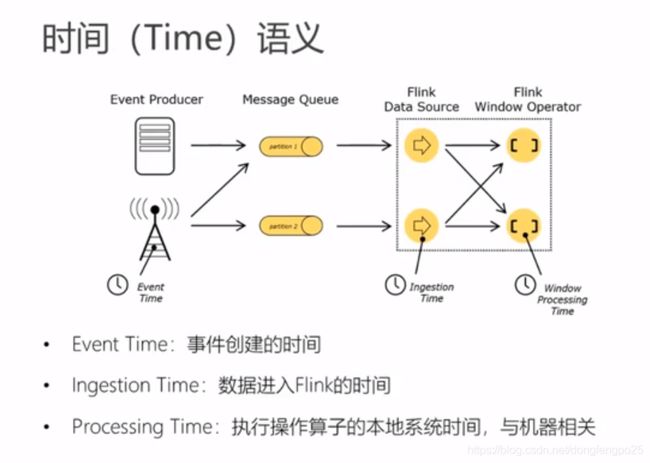
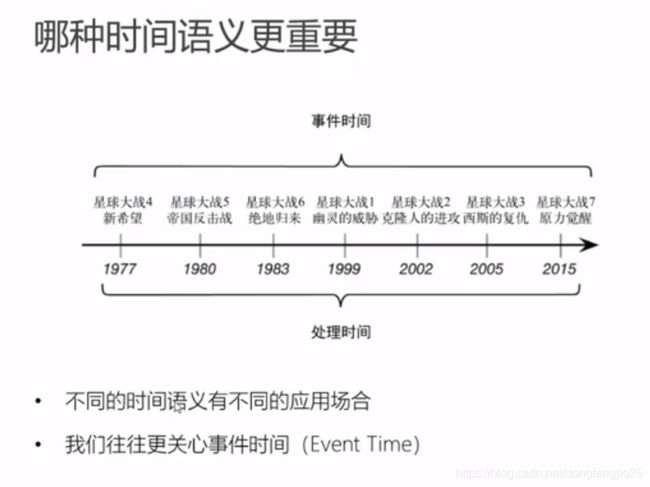
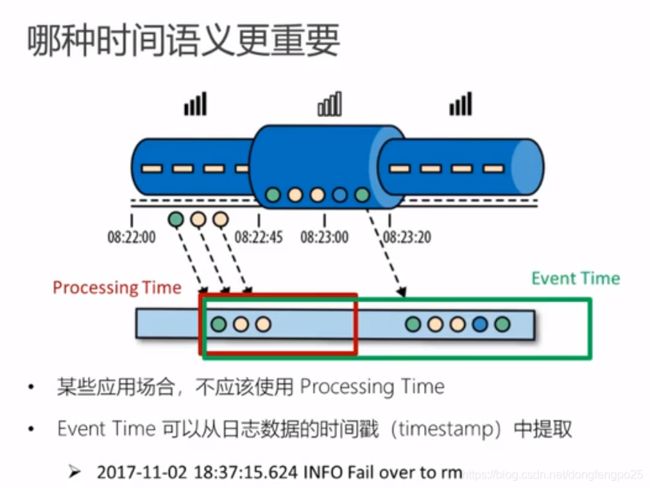

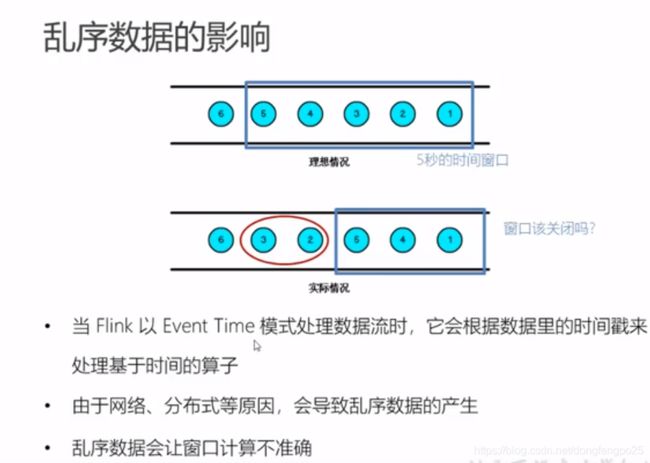

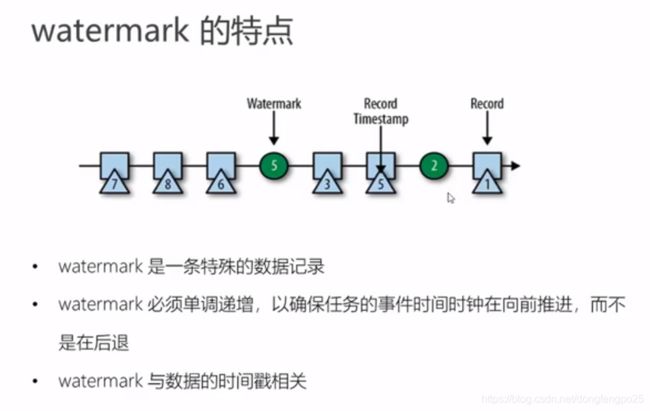
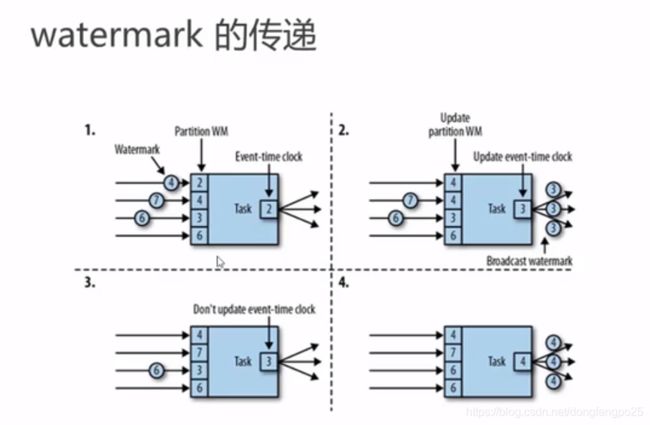
类似 木桶理论,为了保证水位线高的数据等待,以水位线最低的为准,更新成事件时间。




-
事件时间测试
package com.dong.flink.window
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import com.dong.flink.SensorReading
import org.apache.flink.streaming.runtime.operators.windowing.WindowOperator.Timer
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.functions.AssignerWithPunctuatedWatermarks
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
object WindowTest {
def main(args: Array[String]): Unit = {
//创建一个批处理的执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//让例子更清晰,默认的processTime不够清晰
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//默认200ms
env.getConfig.setAutoWatermarkInterval(100L)
//从文件中读取数据
//val txtPath = "D:\\dev\\java\\ide\\scala\\ws\\flink\\src\\main\\res\\sensor.txt"
//val s = env.readTextFile(txtPath)
val s = env.socketTextStream("localhost", 7777)
val ds = s.map(data => {
val array = data.split(",")
SensorReading(array(0).trim, array(1).trim.toLong, array(2).trim.toDouble)
})
//有序的数据,不延迟,到时就发车,不等人
//.assignAscendingTimestamps(_.timestamp * 1000)
//乱序场景
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.seconds(1)) {
override def extractTimestamp(e: SensorReading): Long = e.timestamp * 1000
})
//输出10秒之内最小的温度值
val minTemperatureWindowStream = ds.map(data => (data.id, data.temperature))
//必须要keyby得到keystream才能开窗口,否则只能windowall
.keyBy(_._1)
//开时间窗口,默认是processTime时间语义,处理时间不可能10S,一下子就过去了,所以没有得到聚合结果
.timeWindow(Time.seconds(10))
//增量聚合 data1前面聚合的结果,data2是新来的数据
.reduce((data1, data2) => (data1._1, data1._2.min(data2._2)))
minTemperatureWindowStream.print("min temp")
ds.print("input data")
env.execute("window test")
}
}
//周期性的wm
//class MyAssigner() extends AssignerWithPeriodicWatermarks[SensorReading] {
// val bound = 60000
// var maxTs = Long.MinValue
//
// def extractTimestamp(e: SensorReading, t: Long): Long = {
// maxTs = maxTs.max(e.timestamp * 1000)
// e.timestamp * 1000
// }
//
// def getCurrentWatermark(): Watermark = new Watermark(1)
//}
//没有周期的wm
class MyAssigner() extends AssignerWithPunctuatedWatermarks[SensorReading] {
def checkAndGetNextWatermark(lastE: SensorReading, t: Long): Watermark = new Watermark(t)
def extractTimestamp(e: SensorReading, t: Long): Long = e.timestamp * 1000
}
input data> SensorReading(sensor_1,1547718199,35.34)
input data> SensorReading(sensor_1,1547718203,4.66)
//这里为什么输出呢还没到10s呢
//1547718199来了之后水位是1547718198的窗口的,所以没有输出
//1547718203来了之后,水位涨到1547718202,1547718199数据收进新的窗口,并打印出来了
//但是疑问:为什么不等到10S触发呢???后面源码介绍了原理计算一下就得到
//窗口区间为1547718199-(1547718199+10000)%10000=1547718190 --> 1547718200,所以触发了
min temp> (sensor_1,35.34)
input data> SensorReading(sensor_1,1547718204,5.0)
input data> SensorReading(sensor_1,1547718199,35.34)
input data> SensorReading(sensor_2,1547718200,15.86)
input data> SensorReading(sensor_3,1547718201,6.79)
input data> SensorReading(sensor_3,1547718206,7.0)
input data> SensorReading(sensor_3,1547718207,8.0)
input data> SensorReading(sensor_3,1547718208,9.0)
input data> SensorReading(sensor_3,1547718209,10.0)
input data> SensorReading(sensor_3,1547718210,11.0)
input data> SensorReading(sensor_3,1547718211,12.0)
//为什么这里触发呢 当前水位线为1547718211-1=1547718210
//水位线范围为:上一次(1547718203-1)-->1547718211(此时为1547718210)
min temp> (sensor_1,4.66)
min temp> (sensor_2,15.86)
min temp> (sensor_3,6.79)
input data> SensorReading(sensor_1,1547718212,1.0)
input data> SensorReading(sensor_1,1547718213,2.0)
input data> SensorReading(sensor_3,1547718214,3.0)
input data> SensorReading(sensor_3,1547718215,5.0)
input data> SensorReading(sensor_3,1547718216,6.0)
input data> SensorReading(sensor_6,1547718217,7.0)
input data> SensorReading(sensor_6,1547718218,8.0)
input data> SensorReading(sensor_6,1547718219,9.0)
input data> SensorReading(sensor_7,1547718220,10.0)
input data> SensorReading(sensor_7,1547718221,11.0)
//水位线范围为:上一次(1547718210)-->1547718220(不包含此值)
//而且区间还不包含1547718220的值,看下面没有输出sensor_7为10的值
min temp> (sensor_3,3.0)
min temp> (sensor_1,1.0)
min temp> (sensor_6,7.0)
input data> SensorReading(sensor_1,1547718222,2.0)
input data> SensorReading(sensor_1,1547718223,3.0)
input data> SensorReading(sensor_1,1547718224,3.0)
input data> SensorReading(sensor_1,1547718225,5.0)
input data> SensorReading(sensor_1,1547718226,6.0)
input data> SensorReading(sensor_1,1547718227,7.0)
input data> SensorReading(sensor_1,1547718228,8.0)
input data> SensorReading(sensor_1,1547718229,9.0)
input data> SensorReading(sensor_1,1547718230,10.0)
input data> SensorReading(sensor_1,1547718231,11.0)
min temp> (sensor_7,10.0)
min temp> (sensor_1,2.0)
//水位线范围为:上一次>=(1547718220) 并且 <1547718230(不包含此值)
//区间为10s刚好
//输出sensor_7为10的值,说明1547718220 1547718221在这个窗口生效了
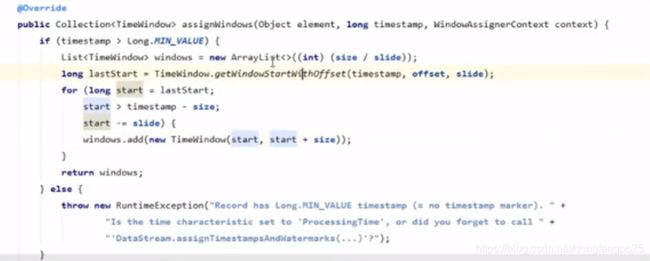
滑动窗口测试:
把开窗时间代码修改一下
//输出10秒之内最小的温度值(滚动窗口)
.timeWindow(Time.seconds(10))
改为:
//输出15秒之内最小的温度值,隔5s输出一次(滑动窗口)
.timeWindow(Time.seconds(15), Time.seconds(5))
接下来看效果:
input data> SensorReading(sensor_1,1547718199,35.0)
input data> SensorReading(sensor_1,1547718200,34.0)
input data> SensorReading(sensor_1,1547718201,33.0)
min temp> (sensor_1,35.0)
//这里输出了,说明水位线在1547718200,但不包含1547718200的数据
//那么此时的窗口关闭应该是1547718185-->1547718200 (15S)
//同时因为滑动窗口是5s,所以下一个滑动窗口是1547718190-->1547718205
//所以推算应该是1547718206触发
input data> SensorReading(sensor_1,1547718202,32.0)
input data> SensorReading(sensor_1,1547718203,31.0)
input data> SensorReading(sensor_1,1547718204,30.0)
input data> SensorReading(sensor_1,1547718205,29.0)
input data> SensorReading(sensor_1,1547718206,28.0)
min temp> (sensor_1,30.0)
//1547718206果然触发了,水位在1547718205,而且不包括1547718205的值
//下一个水位滑动窗口在1547718195-1547718210,在1547718211触发
input data> SensorReading(sensor_1,1547718210,27.0)
input data> SensorReading(sensor_1,1547718211,26.0)
min temp> (sensor_1,28.0)
//1547718205<=触发水位<1547718210,就29和28两个值,所以输出28
上面为什么第一次是水位1547718200触发,看源码