Flink之二 Flink安装及入门案例
Flink 安装(集群模式):
1:下载安装flink的安装包,注意hadoop的版本兼容问题

2:解压安装包,进入conf配置文件目录下,主要配置文件为flink-conf.yaml和slaves,配置flink-conf.yaml解析如下:
2.1 基本配置
jobmanager.rpc.address: localhost1 --jobManager 的IP地址
jobmanager.rpc.port: 6123 --jobManager 的端口,默认为6123
jobmanager.heap.mb --jobManager 的JVM heap大小
taskmanager.heap.mb --taskManager的jvm heap大小设置
taskmanager.numberOfTaskSlots --taskManager中taskSlots个数,最好设置成work节点的CPU个数相等
parallelism.default --并行计算数
fs.default-scheme --文件系统来源
fs.hdfs.hadoopconf: --hdfs置文件路径
jobmanager.web.port -- jobmanager的页面监控端口
2.2 内存管理配置
Flink默认上分配taskmanager.heap.mb配置值得70%留它管理,内存的管理让flinK批量处理效果很高;并且flink不会出现OutMemoryException的问题,因为flink知道预留多少内存来执行程序;如果flink运行的程序所需要的内存超过了它所管理的内存,Flink就可以利用磁盘;总而言之,flink的内存管理提高了鲁棒性和系统的速度;下面就介绍管理内存的配置文件:
taskmanager.memory.fraction --管理内存的百分比,默认0.7
taskmanager.memory.size --taskManager 具体管理内存的大小;此配置重写taskmanager.memory.fraction的配置
taskmanager.memory.segment-size --内存管理器所使用的内存缓冲区的大小和网络堆栈字节
taskmanager.memory.preallocate --taskmanager是否启动时管理所有的内存
2.3 slaves 中配置节点机器的ip或主机名
3:启动flink

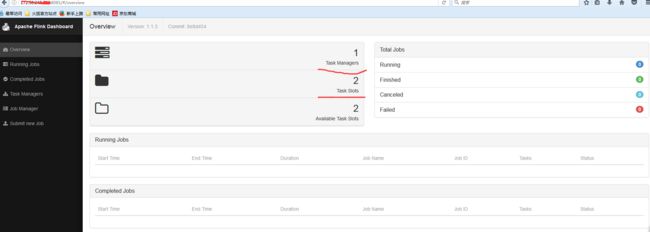
4:进入web监控页面
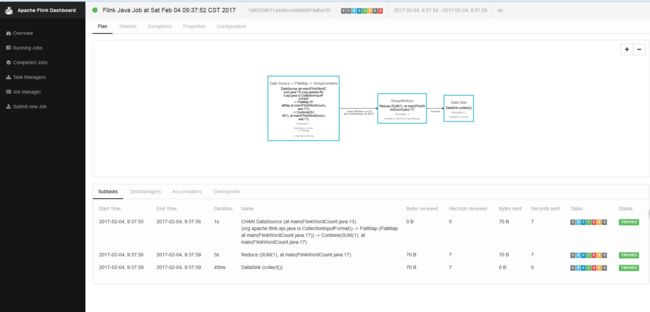
若见到上图页面,就说明flink配置成功了,下面就以wordcount为案例运行,案例代码如下:
public class FlinkWordCount {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet
"hadoop hive?",
"think hadoop hive sqoop hbase spark flink?");
DataSet
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
wordCounts.print();
}
public static class LineSplitter implements FlatMapFunction
@Override
public void flatMap(String line, Collector
for (String word : line.split("\\W+")) {
out.collect(new Tuple2
}
}
}
}
以上代码进行打包上传;上传后执行提交命令:

打印结果如下:
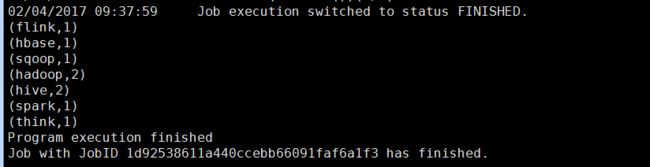
web页面监控