用科学的方法做不科学的事情---用大数据选彩票(一)
作为一名悠久但是不资深的彩民,这些年被机选坑掉了不少钱,以至于我怀疑这些机选的号码是否在一个名为“选不中”的集合中,每次机选的时候被“随机选出”。所以我决定将大数据学以致用,用“科学”的方法买彩票。
第一章 数据清洗
第一步,下载“大乐透”历史所有号码(从2003年2月23日到2019年7月4日),存在电脑D盘中,命名为111。用pandas库读取数据,以数据框dataframe形式引用。
import pandas as pd
df=pd.read_excel('d:\\111.xls')
df结果:
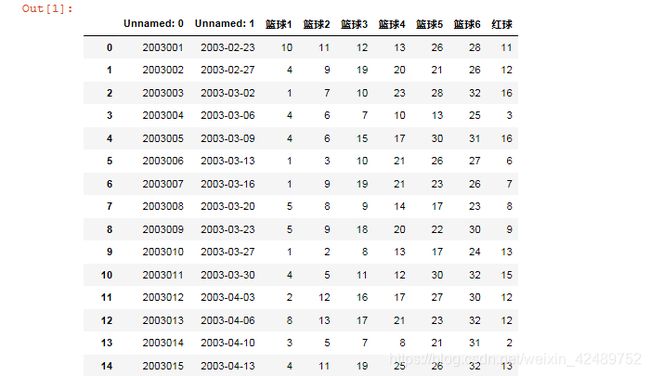
*后面还有数据,但是截图无法全部显示,下面同理
第二步,切片:把数据分成篮球组和红球组,统计出篮球红球中各位数出现次数。
import pandas as pd
df=pd.read_excel('d:\\111.xls')
df_all=df[['篮球1','篮球2','篮球3','篮球4','篮球5','篮球6','红球']] #数据帧(dataframe)格式
df_blue=df[['篮球1','篮球2','篮球3','篮球4','篮球5','篮球6']]
df_red=df[['红球']]
df_all_array=df_all.values #数据帧转化为二维数组格式
df_blue_array=df_blue.values
df_red_array=df_red.values
all_blue=[] #定义空一维数组
all_red=[]
dic_blue={} #定义空字典 用来存放蓝红球各个数出现频率
dic_red={}
for each in df_blue_array: #将二维数组转化为一维数组
for each in each:
all_blue.append(each)
for i in range(1,34): #统计数组中 1-33 出现的次数
dic_blue[i]=all_blue.count(i) #把结果写入字典中
for each in df_red_array:
for each in each:
all_red.append(each)
for i in range(1,17):
dic_red[i]=all_red.count(i)
dic_blue_sort=sorted(dic_blue.items(),key=lambda item:item[1], reverse=True) #按照value值正序排序
dic_red_sort=sorted(dic_red.items(),key=lambda item:item[1], reverse=True)红球正序结果如下:

篮球正序结果:

通过历史数据我们可以得出两组数字:
出现次数最多的数字MAX:1,14,18,20,22,26+12(强者恒强)
出现次数最少的数字MIN:15,24,28,29,31,33+8(当数据越多的时候,数据越应趋向于一致,所以少的数字应该在接下来的时间里比其他数字出现几率高)
第三步:
查看历史数组是否有重复项
查看历史数组是否有设定最大值
查看历史数组是否有设定最小值
查看篮球历史数组是否有重复值
查看篮球历史数组是否有设定篮球最大值
查看篮球历史数组是否有设定篮球最小值
max_all=[1,14,18,20,22,26,12]
min_all=[15,24,28,29,31,33,8]
max_blue=[1,14,18,20,22,26]
min_blue=[15,24,28,29,31,33]
def repeat_all(arr): #数组内是否有重复值
result = 1
for i in range(0,2435):
for j in range(i+1,2435):
if ((arr[i]==arr[j]).all()):
print(i,j,arr[i])
result = -1
if result==1:
print("没有重复项")
def repeat_double(arr,arr1): #数组内是否有arr1
result = 1
for i in range(0,2435):
if ((arr[i]==arr1).all()):
print(i,arr[i])
result = -1
if result==1:
print("没有重复项")
print("历史数据:")
repeat_all(df_all_array)
print("篮球历史数据:")
repeat_all(df_blue_array)
print("历史数据与最大值:")
repeat_double(df_all_array,max_all)
print("历史数据与最小值:")
repeat_double(df_all_array,min_all)
print("篮球历史数据与最大值:")
repeat_double(df_blue_array,max_blue)
print("篮球历史数据与最小值:")
repeat_double(df_blue_array,min_blue)结果:

篮球重复数据:

根据历史数据,我们有理由相信数据是不重复的,把历史数据排除掉,那么可选数组就是:
红球注数=33*32*31*30*29*28/(6*5*4*3*2*1)=1107568注
篮球注数=16
双色球全包的总注数=1107568*16=17721088注
减去历史出现的2435注(截止2019年7月4日)
那么还剩下17718653注 相当于提高了几率0.00013741%
掀桌(╯‵□′)╯︵┻━┻。
第二章 数据分析
用“科学”的思维思考一下,如果把数字当成数字看待的话,那么就强行赋予了一层内在关系,因为阿拉伯数字是有递进排序关系的。假设我们看做每次选择33个毫无关系的物质。也就是把数组1-33 看做 字符1-33,每个字符看做一个独立个体。
我们的老祖宗早就告诉过我们,塔罗牌都是骗人的,五行才是中国传统文化的根基啊!!!因为天干地支是60个循环,而所有篮球之和在21-183之间,加上红球在22-199之间,也许可以通过某种方法找到他们之间的内在关系。
通过读取历史数据,我们可以得知每次开奖的日期。通过与万年历数据比对,我们将得到每次的天干地支日。写到最开始数据帧df后面,命名为df_cycle(因为天干地支的内核是循环)
from borax.calendars.lunardate import LunarDate
import pandas as pd
import copy
df=pd.read_excel('d:\\222.xls')
time=[]
df_clcle=df['日期']
for i in df_clcle:
s=i
s=s.split(",")
yy = int(s[0])
mm = int(s[1])
dd = int(s[2])
ld = LunarDate.from_solar_date(yy,mm,dd)
kk=ld.strftime('%G')
time.append(kk)
cycle_word=[] #设定空数组,放置天干地支的年月日
for i in time:
a=[i[0:2],i[3:5],i[6:8]]
cycle_word.append(a)
cycle_num=copy.deepcopy(cycle_word) #设定一个数组 为前者的复制体
dic_contrast={ #设定一个字典 天干地支对应的数字
"甲子":1,
"乙丑":2,
"丙寅":3,
"丁卯":4,
"戊辰":5,
"己巳":6,
"庚午":7,
"辛未":8,
"壬申":9,
"癸酉":10,
"甲戌":11,
"乙亥":12,
"丙子":13,
"丁丑":14,
"戊寅":15,
"己卯":16,
"庚辰":17,
"辛巳":18,
"壬午":19,
"癸未":20,
"甲申":21,
"乙酉":22,
"丙戌":23,
"丁亥":24,
"戊子":25,
"己丑":26,
"庚寅":27,
"辛卯":28,
"壬辰":29,
"癸巳":30,
"甲午":31,
"乙未":32,
"丙申":33,
"丁酉":34,
"戊戌":35,
"己亥":36,
"庚子":37,
"辛丑":38,
"壬寅":39,
"癸卯":40,
"甲辰":41,
"乙巳":42,
"丙午":43,
"丁未":44,
"戊申":45,
"己酉":46,
"庚戌":47,
"辛亥":48,
"壬子":49,
"癸丑":50,
"甲寅":51,
"乙卯":52,
"丙辰":53,
"丁巳":54,
"戊午":55,
"己未":56,
"庚申":57,
"辛酉":58,
"壬戌":59,
"癸亥":60,
}
for i in range(0,2435): #将天干地支更改为对应的数字
for j in range(0,3):
cycle_num[i][j]=dic_contrast[cycle_num[i][j]]
cycle_word_dataframe=pd.DataFrame(cycle_word) #将数组转化为数据帧,以便下一步数据帧合并
cycle_num_dataframe=pd.DataFrame(cycle_num)
res=pd.concat([df,cycle_word_dataframe,cycle_num_dataframe],axis=1,ignore_index=False)结果:

我们假设一个数 X ,我们希望这个X会是开奖数字和天干地支数字之间的一个纽带,通过某种公式或者先知的启示能够让两者取得的X的重复率达到80%以上。这个80%的阈值是我假设的,因为1%不露脸。