
概述
我们知道分布式事务需要通过两阶段提交来实现,两阶段提交顾名思义,一次事务需要两次交互,也就意味着至少需要两次IO才能完成,考虑到事务的参与者和协调者都要保证高可用,不可避免的需要多个副本,因此还需要引入数据同步,数据冗余存储,由此可见要完成一次分布式事务代价是昂贵的。
CRDB对分布式事务做了大量持续的优化,极大的提升了集群的性能,那么它是如何优化的呢?下面我们通过一个示例来演示这个优化的过程。
我们假定有一个table T,它有两个列分别是A,B,其中A是主键,为了便于演示,我们同时假定这个table有三个分片range1,range2,range3。我们执行一条insert语句:
INSERT INTO t VALUES (1, 'x'), (2,'y'), (3, 'z’);
这三条记录分片存储于table的三个分片上.即主键1的行在range1上,主键2的行在range2上,主键3的行在range3上。
两阶段提交事务
两阶段提交协议很简单,它总共有两个阶段:prepare阶段和commit/abort阶段, 以及两个角色:事务协调者和事务参与者。
Prepare阶段:事务协调者向所有的事务参与者发送prepare请求,确认事务参与者是否可以参与本次事务,等待事务参与者回复响应.如果所有的事务参与者都回复确认,那么进入commit阶段,否则进入abort阶段。
Commit/abort阶段:这个阶段事务协调者向所有的事务参与者发送commit请求,完成事务提交,如果需要abort事务,那么向所有的事务参与者发送abort消息,取消事务。
从上述描述中,我们不难有以下疑问:
如果事务过程中事务协调者异常了怎么办?
如果事务的参与者在prepare阶段不能回复确认怎么办?
在事务提交阶段,如何保证一定提交成功.
在CockroachDB中解决第一个问题的方法就是增加一个事务记录表,事务开始的时候,在事务记录表新增一条记录,记录事务的元信息,如果事务协调者在事务过程中异常,其他的节点可以通过事务记录恢复事务。这里我们还要解决另外一个问题,那就是需要保证事务记录表中记录的不丢失,高可用。
对于第二个问题,CockroachDB是给每一个prepare请求增加一个超时时间,如果超时没有收到确认,那么就认定事务失败,需要终止事务。
对于第三个问题,CockroachDB是在事务记录中保存了一个事务状态,只要prepare阶段所有的事务参与者都回复了确认,那么就修改事务记录中的事务状态为commit,这个操作只针对一条记录的修改,因此可以保证原子性,只要事务的状态是commit,就可以认定事务已经完成提交。这一点很重要,CockroachDB事务优化恪守的底线和基础就是这个原则。
有了上述的铺垫,我们在回到我们的分布式事务示例中,在上述描述的框架下,一个事务的执行过程如下:
BeginTransaction(TXN)
CPut(1)
CPut(2)
CPut(3)
EndTransaction(TXN)
这个过程从上到下是串行的,我们可以看出这个执行过程可以完成分布式事务的过程,但是性能太差,事务的延时太长.我们假定每一个步骤耗费的时间是一样的都是t,那么这个事务的延迟就是5t。并且我们可以合理的推测,随着事务规模的变大,事务执行时间就会越长。
并行提交
从上面的执行过程我们可以分析发现,其实参与事务的三条记录在本次事务中没有相关性,因此我们可以并行发送prepare请求来降低事务的延迟。优化后的事务执行过程如下:
BeginTransaction(TXN)
CPut(1) CPut(2) CPut(3)
EndTransaction(TXN)
优化后的事务的总延迟就是3t,延迟降低了40%,并且值得欣慰的是,随着事务规模的扩大,事务的延迟保持不变,也就意味着在理想的情况下(集群的各个组件都没有达到性能瓶颈),无论大事务还是小事务集群都可以保证稳定的吞吐。
一阶段提交
我们暂时修改一下我们之前的假设,假如参与事务的三条记录都集中在一个分片上,这种情况下,我们其实没必要使用笨重的两阶段提交了,因为所有要修改的数据都在一个分片上,那么我们就可以一次性把所有的写操作都发送给目标分片,依靠raft log原子的复制给分片的每一个副本,然后利用底层的存储引擎提供的batch接口(rocksDB的batch接口可以保证一批数据要么全部写入成功,要么全部失败),原子的把数据写入磁盘完成事务执行。这个过程就不再需要事务记录了,也不需要单独的commit阶段了。如下图所示:

这种场景下,事务的延迟只有t.这个优化对于那些单条记录的插入非常友好。如果我们的业务存在大量这样的写入操作,那么我们可以明显的感受到集群吞吐的提升。
事务记录表优化
前面的章节我们提到分布式事务,我们需要维护一个事务记录表来记录所有的分布式事务,在此之前的事务记录都是单独存放的,这样参与事务的实际分片就会增加,也就意味着增加了新的IO,CockroachDB在这里处理的非常巧妙,它把事务记录存储到事务的第一个记录所在分片上,事务记录和业务数据通过不同的前缀区分开来,这样事务记录的IO和事务的第一个记录的IO可以合并成一个IO.优化后的事务执行流程如下:
BeginTransaction(1) CPut(1) CPut(2) CPut(3)
EndTransaction(1)
优化后的事务延迟只有2t,延迟降低了60%。如下图所示:

这个优化的意义在于一方面减少了IO,另一方面免于单独维护事务记录表,因为任何数据分片都是有多个副本保证高可用的,同时因为使用raft共识算法同步副本之间的数据,因此事务记录也是高可用的也是强一致的,没有数据丢失的风险。
事务参与者优化
前面章节我们也提到任何数据分片都是有多个副本,它们分别分散到不同的节点上,这些副本之间通过raft共识算法实现数据强一致。我们之前假定任何一次请求的延迟都是t,其中包含了网络延迟,raft复制延迟,以及磁盘io延迟。如果我们可以优化单次请求的延迟就可以整体降低事务的延迟。
对于网络延迟,我们可以采用更快的网络,比如RDMA。这是硬件层面的优化,不在我们的讨论范围之内。对于raft复制延迟,我们可以采用批量的方式减少网络中小包的传输,降低延迟,因为这里涉及到普遍意义上的优化,于本文讨论的单次事务的优化不再一个层面上,因此也不会被讨论。
在关系型数据库中,一个insert操作通常需要进行主键冲突检查,这样就会涉及到至少一次读操作,从raft复制的日志中之间应用的话,可以想见,每个副本都需要进行这样的读操作,关于这一点就是本次优化的重点。
CockroachDB引入了latch机制,它在raft复制之前,提前锁定资源,然后进行业务层面的逻辑检查,确定数据可以安全写入后,生成一个只包含写的raft log复制给其他副本,副本在应用log的时候无需额外的操作,直接将数据写入磁盘即可。我们知道raft共识算法是单线程模型,这样就可以极大的提升raft的复制吞吐。如下图所示:
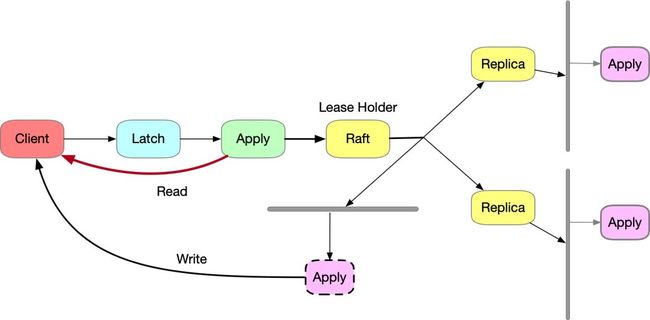
Raft共识算法虽然可以保证强一致,但是它不能保证同一时刻副本上的状态一致,因此数据读取的时候仍然需要主副本来完成。但是对于谁是主副本的确定仍然非常复杂,单独依靠raft来实现一执行读,严格的讲必须仍然需要一次额外的raft log才能确定,这里我们不展开讲述其中的逻辑,我们只需要获得一个结论:一致性读仍然依赖raft日志复制。因此读性能就比较差,事实上一般情况下我们的系统总是读多写少,因此提升读的性能对于我们非常重要。
CockroachDB采用latch+raft lease的方式解决一致性读的问题。latch是一个轻量级的读写锁,它的生命周期是消息级别的,也就是说一个请求的响应返回的时候,这把锁就释放了。另外latch的key级别的锁(可以理解为行锁),也支持范围锁。任何读写请求在执行之前都要申请latch,对于写锁,只有相同的key下面没有时间戳比当前申请者的时间戳小的写锁持有者以及时间戳比当前申请者的时间戳大的读锁持有者即可获得写锁.对于读锁,只要没有写锁,就可以申请到读锁.另外写锁是在raft apply日志结束之后才释放,这一点非常重要。我们简单的推演一下一致性读。当一个写操作执行的时候它首先申请到了写锁,任何其他的写操作将会被阻塞在申请锁的地方,任何时间戳更大的读请求也会被阻塞,然后节点去完成写操作,直到写操作复制给raft group内的多数副本,并且在主副本应用完成后才释放,着意味着写操作已经被持久化到磁盘,然后时间戳更大的读操作才能申请到读锁,这个时候就可以读取到刚刚完成的写记录。这个过程并不需要额外的raft 日志来保证。
因为网络中存在脑裂的问题,因此CockroachDB引入了range lease机制,range lease和raft leader是两个不同维度的角色,所有的读写操作均由lease持有者lease holder负责,但是实际上所有的写必须由raft leader负责提交,因此客观上存在lease holder和raft leader并不是同一个副本的情况,不过为了减少不必要的网络开销,CB-SQL在底层会强制约束lease holder和raft leader在同一个副本上,即如果发现不一致,由lease holder发起rafttransfer leader来切换leader到lease所在的副本。有了lease,再加上latch就可以实现一致性读写了.一致性读绕开了“不必要的”raft log开销,对于事务中的读操作可以极大降低延迟,同时也减少了系统的负担。
事务流水线
CockroachDB针对交互式事务也做了重要的优化,这里需要强调的是任何优化的底层逻辑就是只有事务的状态是commit才认为事务成功。事务流水线的核心是写操作不必等待落盘即可返回响应,数据节点异步的复制和持久化写记录。在事务提交的时候,再去确认之前所有的prepare操作是否完成,如果都已经完成即可更新事务状态为commit,完成事务提交,否则事务回滚。如下图所示:

因为并不需要等待raft复制和应用日志,因此对于交互式事务,延迟很低,可以获得很好的用户体验,但是在事务提交之前需要额外的确认,因此增加了系统的负担,所以事务流水线仅仅是针对交互式事务,自动提交的事务并不会走事务流水线。
事务流水线在事务提交之前额外需要确认之前所有的写操作是否完成,这里的核心仍然是latch,如果写操作还没有完成,也就不会释放写锁,那么后续的确认就会阻塞,因此可以保证查询的结果准确,不会出现不确定性。
事务并行提交
CockroachDB的事务并行提交是对自动提交事务深度优化,设计十分大胆,从客户端的角度看,它甚至是一阶段提交就完成了事务。具体的设计是这样的,CockroachDB新增了一个事务状态STAGED,因为在事务开始的时候,所有的写记录都是确定的,因此并行的发送prepare消息,其中事务记录中增加了所有事务参与者的元信息,同时事务的状态是STAGED,如果所有的prepare消息都OK,那么就可以直接返回给客户端事务提交成功,然后异步的去修改事务状态为commit。
并行提交的正确性证明是这样的,如果没有发生任何异常,那么事务状态顺利变更为commit,事务提交成功,如果事务协调者异常,事务状态变更失败,那么当其他事务检测到冲突的时候,找到这个事务记录,可以看到所有的事务参与者信息,那么就可以主动确认这些参与者的prepare消息是否成功,如果都成功的话,就可以变更事务状态为commit,否则事务就会回滚。
事务并行提交可以极大的减少事务延迟,但是因为增加了额外的写,因此吞吐方面提升不会特别明显,另外因为事务记录里面要记录事务参与者信息,因此事务规模受到一定限制。
OLTP事务的规模一般都不大,因此事务并行提交可以极大降低延迟,改善用户体验.并且这种大胆的优化给了我们很多的启发,突破了我们对两阶段事务的认识。
优化永无止境
从CockroachDB的事务优化演进我们可以看到优化并不是一次性的,而是一个持续的过程,一个不断打磨的过程,一个永无止尽的事情。
也希望上述优化实践可以给大家一些启发和帮助。