flink常用的部署模式可能有如下几种
- standalone cluster模式
- flink on yarn模式
- flink on kubernetes模式
- flink on Mesos
本章主要介绍前两种模式,以Centos6.8为例,选择三台机器(linux01、linux02、linux03)来搭建flink集群
1.standalone cluster模式
1.1安装环境
- Java 1.8.x或更高版本
- ssh(集群节点之间配置互信,可以免密登录)
集群之间每台节点的安装结构保持一致
1.2下载安装
1.1.1版本选择
可以根据对flink功能的选择、hadoop的版本、scala的版本选择合适的flink,这里我们选择Apache Flink 1.7.2 with Hadoop® 2.7 for Scala 2.11版本的flink
如果机器不可访问外网则直接进入flink下载页下载合适版本
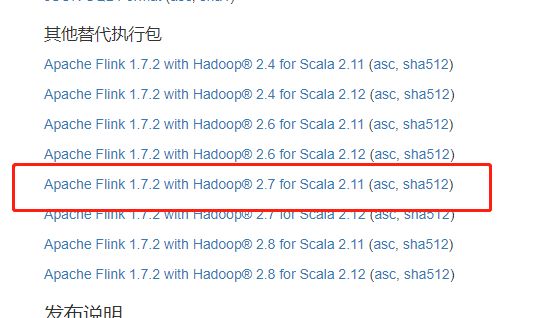
如果可以访问外网则直接wget
cd /opt/soft
wget http://mirror.bit.edu.cn/apache/flink/flink-1.7.2/flink-1.7.2-bin-hadoop27-scala_2.11.tgz
1.1.2安装规划
| linux01 | linux02 | linux03 |
|---|---|---|
| slave | slave | master |
1.1.3安装
在/opt/soft目录下解压文件
#解压
tar -zxvf flink-1.7.2-bin-hadoop27-scala_2.11.tgz
#进入目录
cd flink-1.7.2
1.3集群配置
#进入conf目录
cd conf
#配置flink-conf.yaml
vim flink-conf.yaml
#修改如下属性
jobmanager.rpc.address: linux03
env.java.home=/opt/soft/jdk1.8.0_144
#修改masters文件
vim masters
#添加主节点
linux03
#修改slaves文件
vim slaves
#添加从节点
linux01
linux02
常用配置参数列表如下
| 属性 | 说明 | 默认值 |
|---|---|---|
| jobmanager.rpc.address | jobmanager地址 | localhost |
| jobmanager.rpc.port | jobmanager端口 | 6123 |
| jobmanager.heap.size | jobmanagerJVM堆内存大小 | 1024m |
| taskmanager.heap.size | taskmanagerJVM堆内存大小 | 1024m |
| taskmanager.numberOfTaskSlots | 每个taskmanager的slot数量,根据taskmanager所在节点的cpu数量决定 | 1 |
| parallelism.default | flink任务默认的并行度 | 1 |
| rest.port | flink webui端口 | 8081 |
| io.tmp.dirs | flink中间计算结果的临时存储路径 | /tmp |
官方配置参数
1.4同步flink
将linux01上配置好的flink推到linux02和linux03上
scp -r /opt/soft/flink-1.7.2 work@linux02:/opt/soft
scp -r /opt/soft/flink-1.7.2 work@linux03:/opt/soft
1.5启动集群
linux03节点启动集群
#在master节点启动集群
bin/start-cluster.sh
出现如下提示则说明启动成功
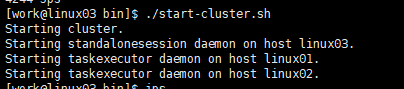
查看三台节点linux01、linux02、linux03的java进程
linux01

linux02

linux03

访问master节点的8081端口http://linux03:8081
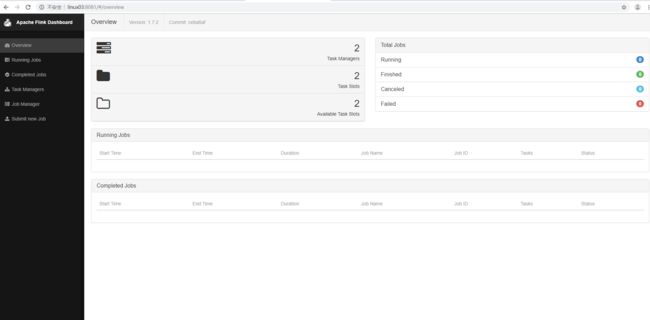
1.6 提交测试
编写测试代码如下,并编译打包 在linux01节点提前执行nc -lk 12345,不然程序报错
object SocketStream {
def main(args: Array[String]): Unit = {
//flink 监控socket 端口 累计输入单词的次数 nc -lk 12345
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.socketTextStream("linux01",12345)
.flatMap(line => line.split(" "))
.map((_,1))
.keyBy(0)
.sum(1)
stream.print()
env.execute("socketWcJob")
}
}
1.6.1 提交方式一:flink-webUI提交
在web界面选择Submit new job,点击Add new+,选择对应的jar

点击Upload

勾选对应的程序,填写对应的参数,点击Submit

这里可以看到对应的job已经启动
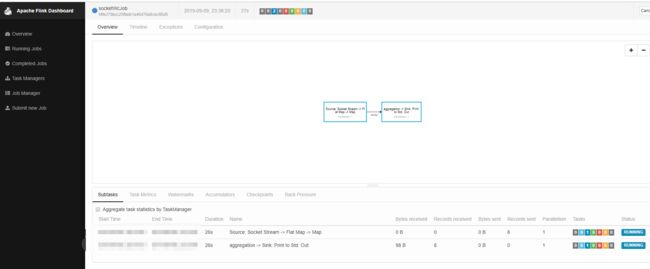
我们在linux01节点事先启动好的socket连接输入字符
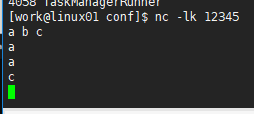
然后在task manager中查看输出
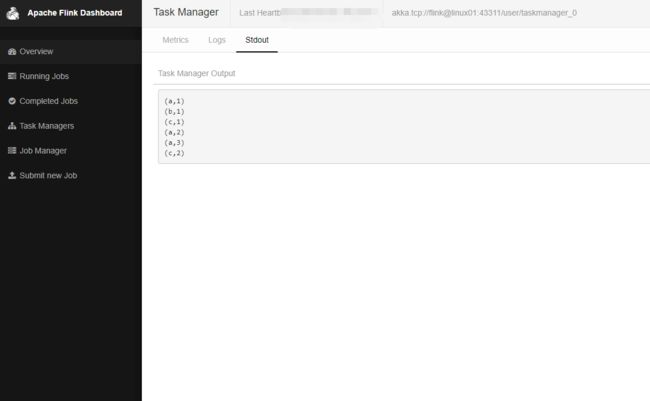
然后点击Running Jobs,选择对应运行job,点击cancel停止任务

1.6.2 提交方式二:命令行提交
将打包好的jar上传至服务器
/opt/soft/flink-1.7.2/bin/flink run -c flinka.dstream.SocketStream ./flink-1.0-SNAPSHOT.jar
成功提交之后可以进入webUI界面查看job运行情况

在Task Managers 查看运行结果

停止程序 可以用命令行也可以在ui界面
执行bin/flink list 查看job列表
执行bin/flink cancel id 停止任务

1.7增删 / 启停节点(JobManager、TaskManager)
可以使用bin/jobmanager.sh和bin/taskmanager.sh脚本为运行中的集群添加JobManager和TaskManager实例
添加jobmanager:
bin/jobmanager.sh ((start|start-foreground) cluster) | stop | stop-all
添加taskmanager:
bin/taskmanager.sh start | start-foreground | stop | stop-all
在新增节点时需要更新配置文件
例如新增linux04 TaskManager,需要在集群的slaves文件中新增linux04
然后在linux04节点运行
bin/taskmanager.sh start
到此standalone cluster模式配置成功
2.flink on yarn模式
2.1 yarn模式介绍
flink on yarn目前有两种模式可供选择
- Yarn Session Model
- Single Job Model
两者区别如下
Yarn Session:会在yarn上长时间启动一个flink session集群,用户可以由命令行、api、web页面将flink任务提交到flink集群,多个flink程序公用一个JobManager和TaskManager
Single Job:与mapreduce任务类似,每一个flink程序作为一个application提交到yarn集群,且每个任务都有自己的JobManager和TaskManager,程序执行完毕则释放资源
 区别
区别
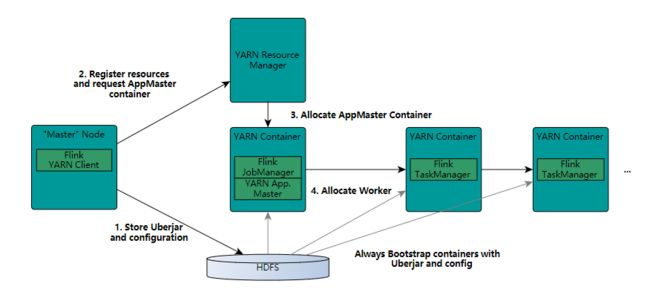
1.上传依赖jar和配置文件
2.向yarn申请资源
3.启动applicationMaster
4.启动worker节点
2.2安装环境
- Hadoop 2.2及以上
- HDFS(或其他分布式文件系统)
- flink所在节点配置了YARN_CONF_DIR或者HADOOP_CONF_DIR环境变量,flink会通过这些变量读取Hadoop的配置
(如果没有这些环境变量也可以在flink-conf.yaml文件中通过fs.hdfs.hadoopconf属性指定,或者在启动时临时对环境变量进行赋值,不过官方推荐用配置环境变量的方式)
//三台节点都之配置上HADOOP_CONF_DIR
HADOOP_CONF_DIR=/opt/soft/hadoop-2.7.7/etc/hadoop
2.3 Yarn Session模式
2.3.1 节点配置
| 节点 | linux01 | linux02 | linux03 |
|---|---|---|---|
| hdfs | NameNode、DataNode | DataNode | DataNode |
| yarn | NodeManager | ResourceManager、NodeManager | NodeManager |
| flink | slave | slave | master |
2.3.2 启动yarn session
在linux01启动HDFS
/opt/soft/hadoop-2.7.7/sbin/start-dfs.sh
在linux02启动yarn
/opt/soft/hadoop-2.7.7/sbin/start-yarn.sh
linux03启动flink和yarn-session
//启动yarn-session
bin/yarn-session.sh
参数
| parameter | parameter | Dynamic properties | Dynamic properties |
|---|---|---|---|
| -n | --container |
Number of YARN container to allocate (=Number of Task Managers) Optional | taskManager个数 |
| -D | use value for given property | 参数 | |
| -d | --detached | If present runs the job in detached mode | 以分离模式运行 |
| -h | --help | Help for the Yarn session CLI. | 帮助 |
| -id | --applicationId |
Attach to running YARN session | 绑定yarn applicationid |
| -j | --jar |
Path to Flink jar file | flink jar路径 |
| -jm | --jobManagerMemory |
Memory for JobManager Container with optional unit (default: MB) | jobManager分配的内存(默认:1MB) |
| -nl | --nodeLabel |
Specify YARN node label for the YARN application | 指定yarn application的标签 |
| -nm | --name |
Set a custom name for the application on YARN | 指定yarn application的名称 |
| -q | --query | Display available YARN resources (memory| cores) | 显示可用的资源(内存、cpu) |
| -qu | --queue |
Specify YARN queue. | 指定yarn队列 |
| -s | --slots |
Number of slots per TaskManager | 指定taskManager中slot的数量 |
| -sae | --shutdownOnAttachedExit | If the job is submitted in attached mode| perform a best-effort cluster shutdown when the CLI is terminated abruptly| e.g.| in response to a user interrupt| such as typing Ctrl + C | 本地cli进程终止关闭集群 |
| -st | --streaming | Start Flink in streaming mode | 以流模式启动flink |
| -tm | --taskManagerMemory |
Memory per TaskManager Container with optional unit (default: MB) | taskManager的内存(默认:1MB) |
| -z | --zookeeperNamespace |
Namespace to create the Zookeeper sub-paths for high availability mode | HA模式下zookeeper的保存路径 |
启动成功
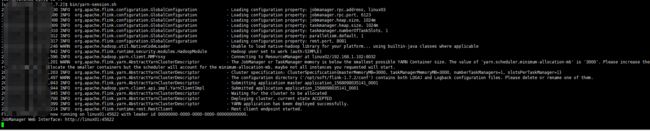
启动失败可能原因
- HDFS和Yarn没启动
- HADOOP_CONF_DIR 配置有误
- Yarn 分配内存不够
在上图中可以看到master节点变成了linux01 http://linux01:45622,这说明了在flink on yarn模式下flink中的master不是固定的,yarn flink 会覆盖掉flink-conf.yaml配置文件中的jobmanager.rpc.address
分离模式启动
看过官网和其他资料说的都比较模糊,这里详细说下
当我们执行bin/yarn-session.sh,会在本地启动FlinkYarnSessionCli进程,然后在由此进程启动yarn session集群,此时FlinkYarnSessionCli相当于前台启动,与yarn交互的信息会一直显示在控制台
此时Ctrl+C和输入stop都会终止FlinkYarnSessionCli进程,区别如下
- Ctrl+C 终止FlinkYarnSessionCli进程而不会终止yarn session 集群
- 输入stop 即会终止FlinkYarnSessionCli进程也会终止yarn session 集群
那么分离模式的作用是什么呢?首先看一下分离模式启动的命令 bin/yarn-session.sh -d
-d代表detached,意思就是把FlinkYarnSessionCli和yarn session分离,对FlinkYarnSessionCli的操作不会影响到yarn session,且在执行bin/yarn-session.sh -d时,当yarn session创建完毕,FlinkYarnSessionCli会自动停止
此时不可通过flink也就是FlinkYarnSessionCli去控制yarn session集群
需要以yarn停止application的方式终止yarn session
yarn application -kill
附加到现有yarn session
与detached的作用刚好相反,如果我们想通过FlinkYarnSessionCli来控制yarn session的话,我们可以启动一个FlinkYarnSessionCli来附加到对应的yarn session上去
例如 已经启动的yarn session的appid是application_1568879202413_0003
我们执行 yarn-session.sh -id application_1568879202413_0003,就会在当前节点启动一个FlinkYarnSessionCli进程并附加到application_1568879202413_0003这个应用上
此时我们在命令行输入stop可以直接停止yarn session
注意直接Ctrl + C只能停止FlinkYarnSessionCli进程,不能停止yarn session,想通过FlinkYarnSessionCli停止yarn session只能通过输入stop
2.3.3 任务提交
这里提交方式同standalone 模式类似,也分为通过web页面提交和命令行提交,需要注意的是如果通过web页面提交可以由三种方式访问到web页面
-
方式一:直接在启动yarn-session时可以看见jobManager地址
 方式一
方式一 -
方式二:通过yarn web
首先我们访问yarn,可以看见yarn session已经启动
 方式二
方式二
随后点击ApplicationMaster,跳转到web页面,再点击submit new job,再点击here就可以访问jobmanager
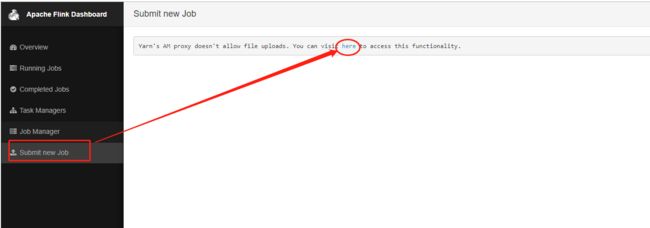 方式二
方式二 -
方式三:通过yarn 命令yarn application -list
 方式三
方式三
2.3.4 停止yarn session
由于我们是本地启动一个进程来维护yarn session,所以这里我们可以通过kill掉进程或者通过yarn来停止
yarn session
#停止本地进程
kill -9 pid
#停止yarn application
yarn application -kill application_xxx_xxx
2.4 Single Job模式
前面已经介绍过Single Job模式每提交一个flink程序都会在yarn生成一个application,运行完毕就释放资源
那么怎么提交独立的flink程序呢? 只需要加上-m yarn-cluster即可
/opt/soft/flink-1.7.2/bin/flink run -m yarn-cluster -c flinka.dstream.SocketStream ./flink-1.0-SNAPSHOT.jar
-m 运行模式,这里使用yarn-cluster,即yarn集群模式。
-ys slot个数。
-ynm Yarn application的名字。
-yn task manager 数量。
-yjm job manager 的堆内存大小。
-ytm task manager 的堆内存大小。
-d detach模式。可以运行任务后无需再控制台保持连接。
-c 指定jar包中class全名