本文通过CockroachDB的事务优化演进,一帮助我们理解CockroachDB的事务实现机制,另一方面给我们一些启发和借鉴。
CockroachDB的经验,同时很多系统的经验都表明不要一开始就着手优化代码,先保证功能和正确性。
到目前为止,CockroachDB已经迭代到V19.2.0(还未正式发布该版本)。我们尝试梳理期间事务优化过程。它大致分为如下几个阶段。
1. 传统事务
2. 并行传输
3. 事务协调者优化
4. 本地读写
5. 事务流水线
6. 事务并行提交
接下来我们通过一个示例来解释这些过程,我们有一个table t,它有三个分片,我们即将insert一组values,它们的主键分片落在这三个分片上。
INSERT INTO t VALUES (1, 'x'), (2, 'y'), (3,'z’);
传统事务
在分布式事务中,我们采用2PC模型。因此事务的执行流程如下:
BeginTransaction(TXN)
CPut(1)
CPut(2)
CPut(3)
EndTransaction(TXN)
以上过程是一个串行执行的过程,假设每一次操作耗时T,那么事务总延时是5T。如果参与事务的记录越多,事务的耗时越长,呈现线性增长。
并行传输
其实事务记录之间并没有相关性,因此我们可以并行prepare。
BeginTransaction(TXN)
CPut(1) CPut(2) CPut(3)
EndTransaction(TXN)
这样事务的总延时是3T。并且事务的总延时不会因为事务的记录多而相应的增加。
事务协调者优化
在分布式事务中我们除了要考虑事务记录存储节点的高可用,还需要考虑事务协调者的高可用,事务记录就是其中的一种方式,一般我们存在一个事务记录表,记录了事务的必要信息,一旦发生协调者故障,可以从事务表中恢复事务。
事务记录也需要存储,在这个阶段,CockroachDB将事务记录与事务的第一条写记录绑定,存储在同一个分片上,这样事务记录的存储就不需要额外的网络开销(存储开销还是需要的),经过优化之后,事务的执行流程如下:
BeginTransaction(1) CPut(1) CPut(2) CPut(3)
EndTransaction(1)
是否还存在优化空间呢?我看到很多的系统的事务优化到这里也就觉得差不多了,不过CockroachDB还是继续深入优化,给了我很多启发。
本地读写
大部分raft的实现,或者没有经过太多改造的raft(很多都是参考ETCD的raft实现)一般都是先复制日志后应用日志,但是这样对写的性能影响很大,因为raft是串行复制,串行应用(一般也是异步应用,但是仍然是串行的)。对于读也类似,严格的一致性读仍然需要一个raft心跳开销。
CockroachDB 使用Latch和Lease组合的方式实现了事务读写的本地化,即对于读直接本地读即可(读lease holder),写先本地应用,然后提交raft 复制给其他成员,具体的实现逻辑这里不展开讲了,可以参考我之前发布的系列文章。
如下图,我们可以直观的感受到这种优化的好处
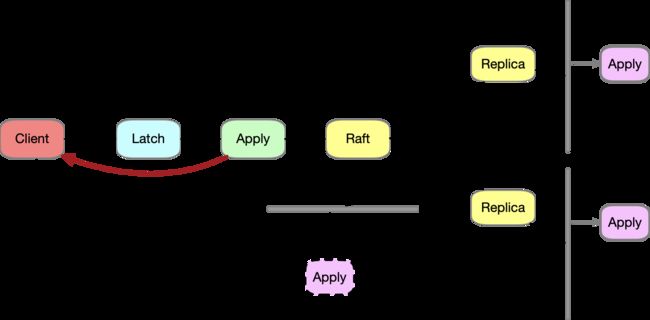
本地读写好处是进一步降低了事务的延迟,读的延迟降低比较好理解,这里解释一下写操作的延迟的降低,因为raft log的复制和应用都是串行的,那么一次写操作包括两个耗时:复制耗时Tc和应用耗时Ta,如果我们在raft log提交之前就应用了(由Latch保证不想关的记录的写操作可以并行),那么考虑同一个分片上存在多个写事务的场景,因为在应用的时候不需要排队,这样可以降低写操作的延时。(如果只存在一个写事务那么没有多少改善),另外提前应用还有一个好处,那就是对于那些会失败的写操作,可以不需要等待复制后应用的时候才发现,造成多个副本执行冗余的逻辑,如果写操作失败,直接返回即可,免去一次raft复制。
举个例子,假设有两个并发的事务TXN1,TXN2,分别修改记录K1,K2,我们总是假设TXN2进入raft 日志队列在TXN1之后,复制一条日志和应用一条日志的耗时分别是T,1.5T,见下图,我们在传统的raft复制应用模式下看TXN 2的修改K2的总耗时
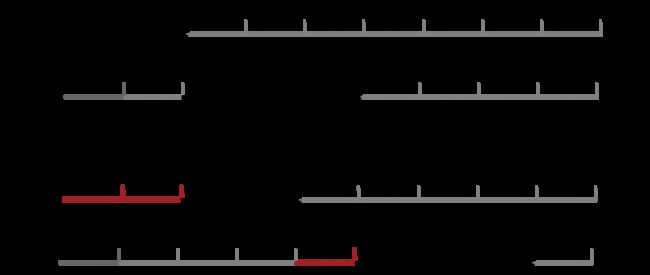
显然,TXN 2修改k2总耗时是4T。如果我们采用先应用后复制的方案后,见下图
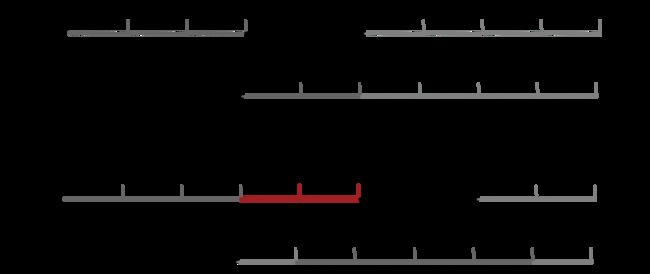
显然,TXN 2修改k2总耗时是3.5T。因此这种模式在并发场景下可以提升写的性能。延展一下,如果写操作aply的耗时也是T,那么这个示例中TXN 2修改K2的总耗时跟前一个方案一样,但是我们不能假设应用一条日志的耗时小于复制一条日志,很多时候应用一条日志耗时比复制一条日志要大,至少我的经验是这样。
事务流水线
事务流水线主要是优化那些交互事务,对于自动提交的事务没必要执行事务流水线(CockroachDB会自动识别)。
事务流水线的理论基石是它认定只有事务状态是COMMIT才认为事务提交成功,其他情况均可以判定事务失败。这样我们会看事务本地写操作,原来需要等待raft 应用结束后才能返回给客户端就可以更加激进,raft 提交也可以异步进行,只要最后COMMIT之前检查复制成功即可。按照这个思路,我们需要在事务状态修改成COMMIT之前,主动的check事务的写记录是否复制成功,CockroachDB引入了新的request: IntentsQuery,它在EndTransaction之前,检查所有的写记录是否复制成功,如果成功,那么就可以提交事务,否则事务失败。
参看下图

这里的关键在于Latch,写操作申请一个Latch(轻量级写锁),只有在Apply之后才会释放,因此如果检查的时候,也会申请同样的Latch,如果获得Latch(轻量级读锁),并且写记录也在,事务ID等信息都OK,那么就证明这个写记录复制成功了,这里的道理不言而喻。
从上面的描述我们也可以看出,对于非交互型事务,事务流水线并没有带来什么价值,反而增加了额外的check开销,但是对于交互型事务,事务流水线确实可以降低事务交互的延时。CockroachDB在事务执行的时候会自动根据是否同时携带了EndTransaction来判断是否需要启动事务流水线。
事务并行提交
CockroachDB最近发布了V19.2.0-alpha,一方面是修改了开源协议,转向BSL授权协议,主要是为了应对来自云计算服务商的压力。另一个重大的变化就是引入了事务并行提交。
我们仔细分析事务提交过程,经典的2PC提交,一个事务的总延时是所有的读延时+两次写延时。CockroachDB引入了一个新的事务状态STAGED,这个作为prepare和commit之间的中间状态,事务协调者只需要看到所有的prepare都成功,此时事务的状态是STAGED,就可以直接返回给客户端事务提交成功,而事务真正的提交是异步进行。如果事务协调者crash,那么必须可以从事务记录中恢复整个事务,因此要求事务状态STAGED里需要记录所有事务参与者的信息。
BeginTransaction(1)CPut(1)EndTransaction(1STAGED) CPut(2) CPut(3)
// 如果成功,则可以直接向client返回成功了。
EndTransaction(1 COMMIT) 异步提交
从上面的描述中我们可以看出这样确实可以降低事务的延时,但是因为增加新的写,因此集群的吞吐也许会降低(跟事务的规模有关系)。另外我们也可以看出因为要在事务状态STAGED中记录事务参与者的信息,因此事务的规模存在一定的限制,CockroachDB会自动识别一个事务,是否启动事务并行提交,比如DeleteRange就不会启动。
CockroachDB甚至考虑异步提交的EndTransaction可以利用其他消息捎带,进一步减少系统的网络负担,提升集群性能。
总结
系统的优化是无止尽的,不要让自己思维和认知的局限制约我们的行动,因此解放思想,多交流学习。许多的学科许多的道理的底层是相同的,明白这一点,我们才能快速进步,否则没有办法解释天才的形成了。