数据分析与挖掘1
流程:
数据获取-》探索分析与可视化-》预处理理论-》分析建模-》模型评估
数据获取手段-
1.数据仓库
数据库面向业务存储,仓库面向主题存储
数据库针对应用(OLTP),仓库针对分析(OLAP)
数据库组织规范,仓库冗余大
2.监测与抓取
Python常用工具
urllib,urllib2,requests,scrapy
3.填写,埋点,日志
用户填写信息
APP或网页埋点(特定流程的信息记录点)
操作日志
4.竞赛网站
kaggle
阿里云 天池
探索分析与可视化
理论铺垫
集中趋势:均值,中位数与分位数,众数
.mean() #均值
.median() #中位数
.quantile(q=0.25) #分位数
.mode() #众数 可能会有多个
离中趋势:标准差,方差 √
.std() #标准差
.var() #方差
.sum() #求和
数据分布:偏态与峰态,正态分布与三大分布

.skew() #偏态系数
.kurt() #峰态系数
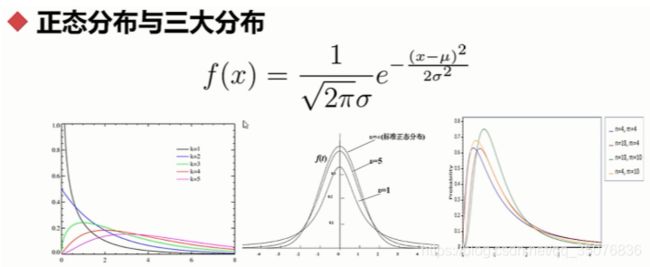
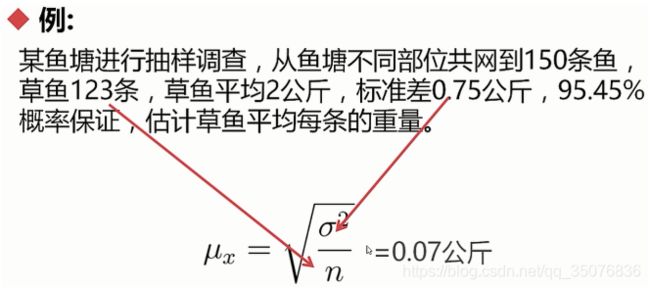
抽样理论:抽样误差,抽样精度
.sample() #抽样


异常值分析:
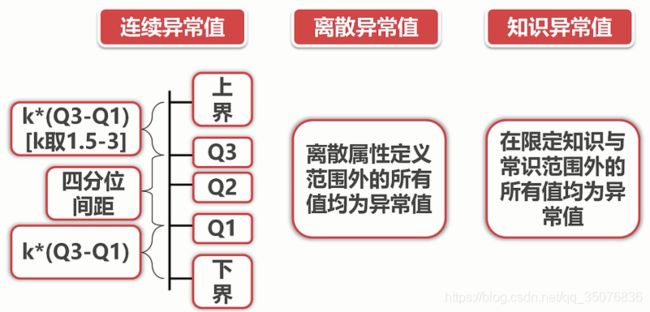
le = le[leqlow-k*q_interval]
判断数据哪些列有异常值:data[ data.isnull() ]
判断某列有多少异常值: sl = data["col"] sl[ sl.isnull() ]
有异常值数据的其他信息: data[ data["col"].isnull() ]
统计某特征各个值数量的多少并排序
col.value_counts(normalize=True).sort_index()
data.loc[ :,["col1","col2"] ].groupby("col3")
df=df[df["col1"]<=1][df["salary"]!="name"][df["department"]]
对比分析
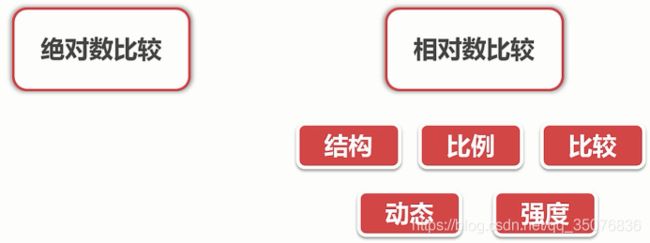
结构分析:
静态分析:看各部分所占比例
动态分析:时间轴,看变化趋势
np.histogram(data.values, bins=np.arange(0.0, 1.1, 0.1)) #value值 从0到1.1,每隔0.1有多少个
数据预处理
特征工程
数据和特征决定了机器学习的上限

异常值处理
①fillna()
②删除某一列的空值 data.dropna(subset=[“B”])
③.interpolate() 插值函数
#保留以f开头的选项
df[ [True if item.startwith(“f”)else False for item in list(df["F"].values) ]]
标注:标签,label
特征选择:
from sklearn.svm import SVR
from sklearn.tree import DecisionTreeRegressor
X=df.loc[:,["A","B","C"]]
Y=df.loc[:,"D"]
from sklearn.feature_selection import SelectKBest,RFE,SelectFormModel
skb=SelectBest(k=2)
skb.fit(X,Y)
skb.transform(X)
rfe=RFE(estimator=SVR(kernal="linear"),n_features_to_select=2,step=1)
rfe.fit_transform(X,Y)
sfm=SelectFormModel(estimator=DecisionTreeRegressor(),threshold=0.1)
sfm.fit_transform(X,Y)
机器学习与建模
机器学习:计算机以数据为基础,进行归纳与总结
监督学习(分类/回归)
非监督学习(聚类/关联)
半监督学习
训练集:用来训练和拟合模型
验证集:纠偏或改正预测
测试集:模型泛化能力的考量(泛化:对未知数据的预测能力)
KNN 朴素贝叶斯 决策树 支持向量机 集成方法
欧式距离 :(直线距离)
曼哈顿距离:(各个维度距离累加)
明可夫斯基距离
K-nearest neighbors
from sklearn.neighbors import Nearest Neighbors ,KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=5)
knn_clf.fit(X_train,Y_train)
Y_pred = knn_clf.predict(X_validation)
from sklearn.metrics import accuracy_score,recall_score,f1_score
print("ACC:", accuracy_score(Y_validation,Y_pred))
print("REC:", recall_score(Y_validation,Y_pred))
print("F-Score:", f1_score(Y_validation,Y_pred))
朴素贝叶斯
概率:p(a)
条件概率p(a|b) 联合概率p(a,b)