论文阅读 《Densely Connected Convolutional Networks》
论文阅读 《Densely Connected Convolutional Networks》
标签(空格分隔): ReadingNote ActionRecognition
2017CVPR BestPaper
[gayhub]
Abstract
如果卷积网络在接近输入的网络层和接近输出的网络层之间包含短连接(short connections)的话,这些网络会更加deeper、精确,训练起来更加有效。
DenseNet中,每一层都以一种前馈方式和其他的所有层相连。对于每一层,前面所有曾的feature maps都作为这一层的输入,这一层的feature map作为后面所有层的一个输入。DenseNet的几个优点如下:
- 减轻梯度消失问题(strong gradient flow。)
- 加强特征传播
- 鼓励特征重用
- 大幅度减少参数数量
4dataset:
- CIFAR-10
- CIFAR-100
- SVHN
- ImageNet
更少的计算量,更好的表现。
Intro
CNN的问题:梯度消失。
ResNet、HightWay Networks、FractalNet
这些方法都有不同的网络拓扑结构和训练步骤,但是他们都有一个共同的思想:在前后的网络层之间构建短路径(short paths)。【they create short paths from early layers to later layers.】
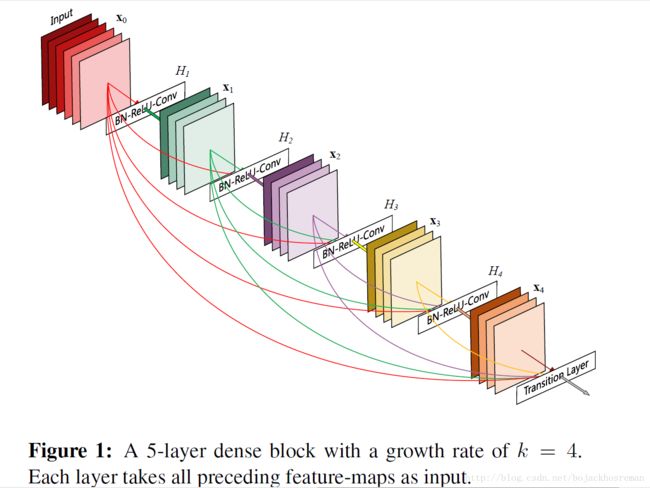
densenet中feature map size一致的所有的层,都直接和彼此相连。为了保留前馈特性,每一层从前面所有的层中获取额外的输入,这一层的feature map作为后面所有层的一个输入。和ResNet不同的是,在特征传入一个网络层的时候,我们不会把特征通过和的形式结合起来,而是采用串联的形式。由于稠密性,所以叫做DenseNet。
比传统的CNN需要的参数更少,因为不用重复学习冗余的feature map。ResNet通过加法恒等变换显式的保存了信息。近期ResNet的变体结构表明了许多层的贡献都非常小,可以在训练的时候随机drop掉。这让ResNet变得像没有展开的RNN了,但是参数数量还是非常大的,因为每一层都有自己的权值。DenseNet对于加到网络中的信息和被保存的信息有明显的区分。
另一个优点就是提升了信息流和贯穿网络的梯度,这样更容易训练。每一层都可以直接访问损失函数的梯度和原始输入信息,导致隐式的深监督(deep supervision)【对于传统cnn,每一层的监督信息只来自上一层。网络深了之后监督就变弱了。Densenet从最后的误差得到更直接的监督,让浅层也学到比较有分辨率的特征】。这能够帮助训练更深的网络结构。并且,我们观察到dense connections有正则的功能,减少了小数据上的过拟合风险。
Related work
DenseNet
ResNets. 传统卷积前馈网络将前一层的输出作为后一层的输入: xl=Hl(xl−1) 。 ResNets加了一个跳跃连接(skip-connection)通过一个恒等函数从旁路传递非线性变化:
如此,梯度可以从较早的网络层直接传递到后面的层,但是恒等函数和 Hl 的输出是通过总和(summation)的形式结合的,有可能覆盖了网络中的信息流。
Dense connectivity. 为了进一步提升网络层之间的信息流,我们提出了一个不同的连接模式。引入任一层与后续所有层的连接。如图1所示。因此,第 l 层会接收到前面所有层的feature maps x0,...,xl−1 , as input:
其中 [x0,...,xl−1] 代表从0到l-1层的features map 的串联。
Composite function 受12启发,我们定义 Hl(⋅) 为一个有三个连续操作组成的复合函数:BN,ReLU,3x3卷积。
Pooling layers 对网络层下采样可以改变featuremap的size。为了我们网络结构中的下采样便利性,我们将网络分为了多个稠密连接的稠密blocks。图二所示。我们将块之间的层称为过渡图层,进行卷积和池化。实验中过渡层由bn层和1x1的卷积层以及2x2的平均池化层组成。【在每个block之间做featrue拼接,在block之间卷积和池化。为什么要加卷积,直接池化不行吗?:加入卷积之后网络设计更自由,可以对channel进行压缩。网络很深的时候,用一个卷积层进行压缩,过滤冗余信息】

Growth rate.增长率。如果每个 Hl(⋅) 函数产生k个feature map,第l层就有 k0+k×(l−1) 个featuremap要输入,其中 k0 是输入层的通道数。densenet和现有网络结构的一个重要区别就是densent非常可以有非常窄的网络层。比如k=12。我们把超参数k叫做网络的增长率。相对较小的增长率已经足够达到现有方法的结果。这是因为每一层在自己的block当中都可以直接访问前面所有层的featuremap,可以看作是网络的“collective knowledge”。可以把featuresmap看作是网络的全局状态。增长率规定了每一层到底给全局状态贡献多少新的信息。全局状态一旦生成,在网络中的任何位置都可以获取,不同于传统的结构,没有必要把它从一层复制到另一层。
Bottleneck layers.[降维,减少channel数。4k。提升参数使用效率+网络计算效率。] 虽然每层都只产生k个featuremaps,但是一般来说有很多的输入。在【36,11】中可以看到,1x1的卷积可以用在3x3卷积层之前,作为瓶颈层,来减少输入featuremap的个数,提升计算效率。实验中发现,这个设计对于densenet来说非常有效,采用瓶颈层()的densenet我们称作densenet-B。在实验中,我们让每一个1x1卷积产生4k个featuremap。(计算量小)
Compression. 压缩。为了进一步紧致模型,我们可以在过渡层较少featuremap的数量。如果一个denseblock包含m个featuremap,那么之后的过渡层就输出 θm 个featuremap,其中 0<θ<=1 ,叫做压缩因子。当 θ=1 ,表示没有压缩,直接穿到下一个denseblock。带有压缩结构的densenet叫做densenet-C。实验中 θ=0.5
又有瓶颈层又有压缩层,叫做densenet-BC。
Implementation Details. 除了imagenet数据集,densenet都采用三个denseblock,每个block层数都相等。在进入第一个denseblock之前,图片先通过一个16通道(or增长率两倍大)的卷积层。对于3x3卷积核的卷积层,每输入的每一个边都0-pad以保证featuremap的大小固定。两个block之间,1x1卷积接上2x2平均池化作为过渡层。在最后一个block,采用了一个全局平均池化,接上一个softmax分类器。三个block的featuremap大小为32x32,16x16,8x8。实验的结构:
- BasicDenseNet:(L=40,k=12)(L=100,k=12)(L=100,k=24)
- DenseNet-BC: (L=100,k=12)(L=250,k=24)(L=190,k=40)
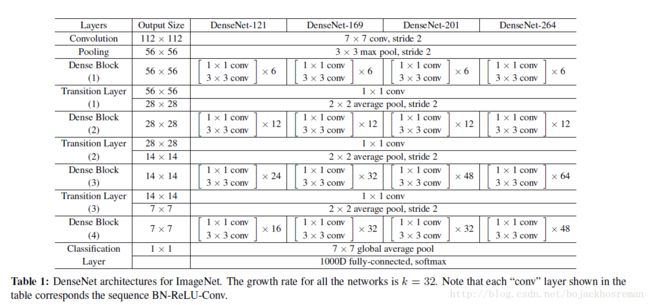
在imagenet上:4block,224x224 input.初始化卷积层包含2k个7x7with stride2的卷积,featuremap数量由k决定。详细设定见下表。
Experiments
DataSets:
CIFAR. 32x32pixels.
- CIFAR10:10000 images.
- CIFAR100:50000 images.
- 5000 for validation.
- 标准增广:(mirroring/shifting)
- normalize: channel means and standard deviations
- 50000 training.
SVHN. The Street View House Numbers 32x32pixels,73257 images for train,26032 images for test,531131 images for additinal trianing.
- 增广:none
- validation : 6000 from training imgs.
- select the model with the lowest validation error during training
- divide the pixel values by 255 so they are in the [0, 1] range.
ImageNet. 1000 classes
- train:1.2 million images
- validation: 50000
- 增广:same as 8 11 12 , single-crop/10-crop with size 224x224 at test time。
Training
All the networks are trained using stochastic gradient descent(SGD).
CIFAR and SVHN
- we train using batch size 64 for 300 and 40 epochs, respectively.
- The initial l**earning rate is set to 0.1**, and is divided by 10 at 50% and 75% of the total number of training epochs
ImageNet
- train models for 90 epochs with a batch size of 256
- learning rate is set to 0.1 initially, and is lowered by 10 times at epoch 30 and 60.
- our largest model (DenseNet-161) is trained with a mini-batch size 128.(due to GPU memory constraints)
- To compensate for the smaller batch size, we train this model for 100 epochs, and divide the learning rate by 10 at epoch 90.
we use a weight decay of 10−4 and a Nesterov momentum [34] of 0.9 without dampening.
没有增广的C10 C1000 SVHN,在每个卷积层(除了第一个)添加dropout层(dropout rate 0.2)。
CIFAR SVHN 结果
不同深度L、增长率的网络结构结果如下。 粗体是state-of-the-art方法,最佳为蓝色

ImageNet Results

【single-crop & 10-crop】:
既然知道single crop evaluation这个名词,那就从它开始吧。
训练的时候,当然随机裁剪,但测试的时候就需要有点技巧了。
Evaluation呢,就是指模型训练好了,测试评估它的性能。
Singl Crop Evaluation通常是指在测试过程中,将图像Resize到某个尺度(比如256xN),选择其中的Center Crop(即图像正中间区域,比如224x224),作为CNN的输入,去评估该模型。
Crops Evaluated不是个专业名词,仅仅表示用多少个Crops作为输入,去评估(Evaluate)模型。
10个Crops呢,一般是取(左上,左下,右上,右下,正中)各5个Crop,以及它们的水平镜像,共10个Crops,输入到CNN模型中,得到10个概率输出,然后平均一下,作为最后的结果。
144个Crops,略复杂点,以ImageNet为例,它首先将图像Resize到了4个尺度(比如256xN,320xN,384xN,480xN),每个尺度上去取(最左,正中,最右)3个位置的正方形区域,然后对这些正方形区域取上述的10个224x224的Crops,然后加上将这正方形区域直接Resize到224x224以及这Resize后的镜像,也就是每个正方形区域得到12个Crops,最后得到4x3x12=144个Crops,输入CNN,得到输出取平均,即为最终模型输出。结论就是densenet和resnet效果不相上下但参数更少计算更快。
Discussion
表面上看densenet和resnet差不多,两个网络输入的式子只有细微的差别。但是这点微笑的差别却导致了两个不同的网络结构。
模型紧凑性 作为输入的直接结果拼接,由任何一个的特征映射可以通过所有后续层访问DenseNet层,这鼓励了整个网络的特性重用,并且导致更紧凑的模型。
Implicit Deep Supervision.【对于传统cnn,每一层的监督信息只来自上一层。网络深了之后监督就变弱了。Densenet从最后的误差得到更直接的监督,让浅层也学到比较有分辨率的特征】
Stochastic vs. deterministic connection
Feature Reuse