python张正友相机标定法的实现
背景
我们拍摄的物体都处于三维世界坐标系中,而相机拍摄时镜头看到的是三维相机坐标系,成像时三维相机坐标系向二维图像坐标系转换。不同的镜头成像时的转换矩阵不同,同时可能引入失真,标定的作用是近似地估算出转换矩阵和失真系数。为了估算,需要知道若干点的三维世界坐标系中的坐标和二维图像坐标系中的坐标,也就是拍摄棋盘的意义。对于张正友棋盘标定法的详解可以参考:python-OpenCV Tutorial。
相机内参数
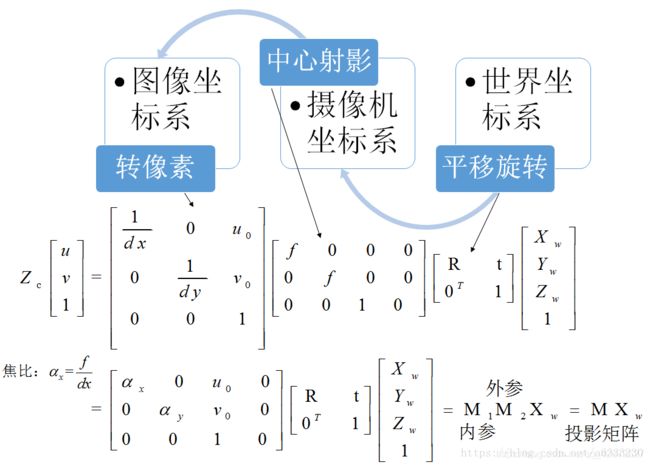
设P=(X,Y,Z)为场景中的一点,在针孔相机模型中,其要经过以下几个变换,最终变为二维图像上的像点p=(μ,ν):
(1)将P从世界坐标系通过刚体变换(旋转和平移)变换到相机坐标系,这个变换过程使用的是相机间的相对位姿,也就是相机的外参数。
(2)从相机坐标系,通过透视投影变换到相机的成像平面上的像点p=(x,y)。
(3)将像点p从成像坐标系,通过缩放和平移变换到像素坐标系上点p=(μ,ν)。
相机将场景中的三维点变换为图像中的二维点,也就是各个坐标系变换的组合,可将上面的变换过程整理为矩阵相乘的形式,将矩阵K称为相机的内参数,

张氏标定原理
1.计算外参
2.计算内参
3.最大似然估计
4.径向畸变估计
代码
标定demo
import cv2
import glob
import numpy as np
'''
cbraw和cbcol是我自己加的。tutorial用的棋盘足够大包含了7×6以上
个角点,我自己用的只有6×4。这里如果角点维数超出的话,标定的时候会报错。
'''
cbraw = 6
cbcol = 4
# prepare object points, like (0,0,0), (1,0,0), (2,0,0) ....,(6,5,0)
objp = np.zeros((cbraw*cbcol,3), np.float32)
'''
设定世界坐标下点的坐标值,因为用的是棋盘可以直接按网格取;
假定棋盘正好在x-y平面上,这样z值直接取0,简化初始化步骤。
mgrid把列向量[0:cbraw]复制了cbcol列,把行向量[0:cbcol]复制了cbraw行。
转置reshape后,每行都是4×6网格中的某个点的坐标。
'''
objp[:,:2] = np.mgrid[0:cbraw,0:cbcol].T.reshape(-1,2)
objpoints = [] # 3d point in real world space
imgpoints = [] # 2d points in image plane.
#glob是个文件名管理工具
images = glob.glob("*.JPG")
for fname in images:
#对每张图片,识别出角点,记录世界物体坐标和图像坐标
img = cv2.imread(fname) #source image
#我用的图片太大,缩小了一半
img = cv2.resize(img,None,fx=0.5, fy=0.5, interpolation = cv2.INTER_CUBIC)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #转灰度
#cv2.imshow('img',gray)
#cv2.waitKey(1000)
#寻找角点,存入corners,ret是找到角点的flag
ret, corners = cv2.findChessboardCorners(gray,(6,4),None)
#criteria:角点精准化迭代过程的终止条件
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
#执行亚像素级角点检测
corners2 = cv2.cornerSubPix(gray,corners,(11,11),(-1,-1),criteria)
objpoints.append(objp)
imgpoints.append(corners2)
#在棋盘上绘制角点,只是可视化工具
img = cv2.drawChessboardCorners(gray,(6,4),corners2,ret)
cv2.imshow('img',img)
#cv2.waitKey(1000)
'''
传入所有图片各自角点的三维、二维坐标,相机标定。
每张图片都有自己的旋转和平移矩阵,但是相机内参和畸变系数只有一组。
mtx,相机内参;dist,畸变系数;revcs,旋转矩阵;tvecs,平移矩阵。
'''
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, gray.shape[::-1],None,None)
img = cv2.imread('1.JPG')
#注意这里跟循环开头读取图片一样,如果图片太大要同比例缩放,不然后面优化相机内参肯定是错的。
img = cv2.resize(img,None,fx=0.5, fy=0.5, interpolation = cv2.INTER_CUBIC)
h,w = img.shape[:2]
'''
优化相机内参(camera matrix),这一步可选。
参数1表示保留所有像素点,同时可能引入黑色像素,
设为0表示尽可能裁剪不想要的像素,这是个scale,0-1都可以取。
'''
newcameramtx, roi=cv2.getOptimalNewCameraMatrix(mtx,dist,(w,h),1,(w,h))
#纠正畸变
dst = cv2.undistort(img, mtx, dist, None, newcameramtx)
#这步只是输出纠正畸变以后的图片
x,y,w,h = roi
dst = dst[y:y+h, x:x+w]
cv2.imwrite('calibresult.png',dst)
#打印我们要求的两个矩阵参数
print("newcameramtx:\n",newcameramtx)
print("dist:\n",dist)
#计算误差
tot_error = 0
for i in range(len(objpoints)):
imgpoints2, _ = cv2.projectPoints(objpoints[i], rvecs[i], tvecs[i], mtx, dist)
error = cv2.norm(imgpoints[i],imgpoints2, cv2.NORM_L2)/len(imgpoints2)
tot_error += error
print("total error: ", tot_error/len(objpoints))
运行结果
用iphone7相机标定出来的结果,总体的错误率0.68还算可以。
