计算机视觉学习8_BOW模型_Bag of features_图像搜索
文章目录
- BOW模型
- Bag of feature:图像检索流程
- 1. 特征提取、学习 “视觉词典(visual vocabulary)
- 2. 针对输入特征集,根据视觉词典进行量化
- 3. 把输入图像,根据TF-IDF转化成视觉单词( visual words)的频率直方图
- 5. 构造特征到图像的倒排表,通过倒排表快速索引相关图像
- 6. 根据索引结果进行直方图匹配
- 代码实现
- 1、生成代码所需要的模型-视觉词汇
- 2、查询图片
BOW模型
Bag-of-words models
研表究明,汉字序顺并不定一影阅响读。比如当 你看完这句话后,才发这现里的字全是都乱的。

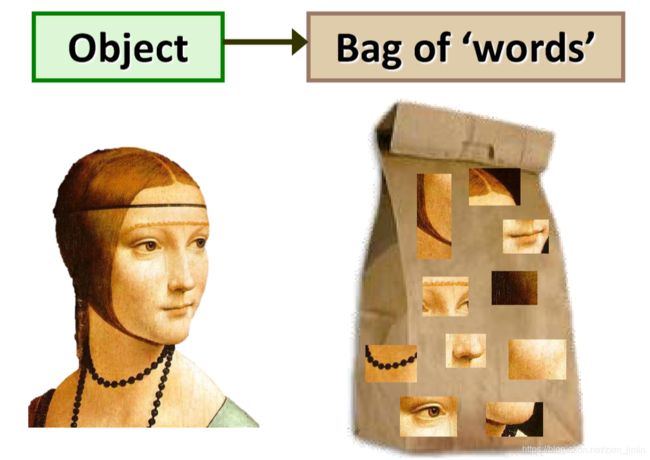
视觉上具相似性的图像。这样返回的图像可以是颜色相似、纹理相似、图像中的物体或场景相似;总之,基本上可以是这些图像自身共有的任何信息。
因此,有了Bag of features模型
Bag of feature:图像检索流程
1. 特征提取、学习 “视觉词典(visual vocabulary)
从我们的图片库中。提取每张图片的特征,作为视觉单词。
这通常可以 采用 SIFT 局部描述子做到。
关于SIFT的更多内容可以移步我另一个博客 https://blog.csdn.net/zxm_jimin/article/details/88597258
它的思想是将描述子空间量化成一些典型实例,并将图像中的每个描述子指派到其中的某个实例中。这些典型实例可以通过分析训练图像集确定,并被视为视觉单词。
从一个(很大的训练图像)集提取特征描述子,利用一些聚类算法可以构建出视觉单词。
聚类算法中最常用的是采用 K-means。视觉单词是在给定特征描述子空间中的一组向量集。
基本Kmeans算法介绍及其实现
参考博客:https://blog.csdn.net/qll125596718/article/details/8243404

K-means算法下的聚类中心,即特征点——就是我们所说的视觉词典。
(一旦训练集准备足够充分, 训练出来的码本( codebook)将 具有普适性)
我们用视觉单词直方图来表示图像,则该模型便称为 BOW 模型。
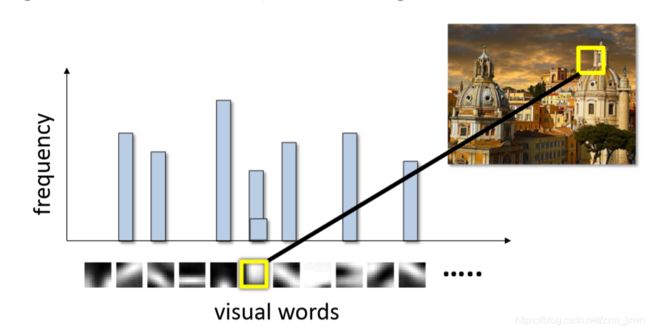
所有视觉单词构成的集合称为视觉词汇,有时也称为视觉词典(visual vocabulary)、视觉码本。对于给定的问题、图像类型,或在通常情况下仅需呈现视觉内容,可以创建特定的词汇。
2. 针对输入特征集,根据视觉词典进行量化
• 对于输入特征,量化的过程是将该特征映射到距离其最接近的 codevector ,并实现计数
• 码本 = 视觉词典
• Codevector = 视觉单词
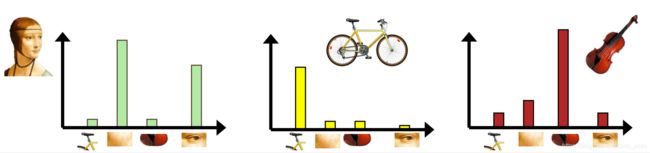
我们的目标是,类内距离小,类间距离大
对于相似的图片,找到相同的特征点(视觉词汇)
怎样找到合适的特征点(视觉词汇),需要根据输入特征集来判断

这里,我们通常要注意的是,视觉词典的长度,即特征点的个数
常用参数设置:
视觉单词数量(K-means算法获取的聚类中心)一般为 K=3000~10000. 即图像整体描述的直方图维度为 3000~10000.
(本文中代码中为 k ≈ 1000 )
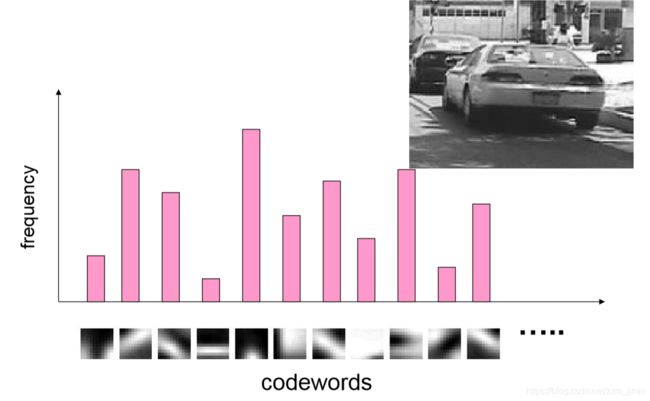
如何选择视觉词典/码本的规模?
•太少:视觉单词无法覆盖所有可能出现的情况
•太多: 计算量大,容易过拟合
需要根据实际情况具体分析
3. 把输入图像,根据TF-IDF转化成视觉单词( visual words)的频率直方图
如一开始提到的单词权重,视觉单词也具有相同特征。

5. 构造特征到图像的倒排表,通过倒排表快速索引相关图像
既然我们需要检索相似图像,这就说明相似图像与输入图像具有相同的特征

也可参考博客:https://blog.csdn.net/javaer_lee/article/details/88055755
6. 根据索引结果进行直方图匹配
代码实现
1、生成代码所需要的模型-视觉词汇


addImage.py
# -*- coding: utf-8 -*-
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
from sqlite3 import dbapi2 as sqlite
from PCV.tools.imtools import get_imlist
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
# load vocabulary
#载入词汇
with open('first1000/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
#创建索引
indx = imagesearch.Indexer('testImaAdd.db',voc)
#indx.create_tables()
# go through all images, project features on vocabulary and insert
#遍历所有的图像,并将它们的特征投影到词汇上
for i in range(nbr_images)[:1000]:
locs,descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i],descr)
# commit to database
#提交到数据库
indx.db_commit()
con = sqlite.connect('testImaAdd.db')
print (con.execute('select count (filename) from imlist').fetchone())
print (con.execute('select * from imlist').fetchone())
cocabulary.py
# -*- coding: utf-8 -*-
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlist
from PCV.localdescriptors import sift
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#提取文件夹下图像的sift特征
for i in range(nbr_images):
sift.process_image(imlist[i], featlist[i])
#生成词汇
voc = vocabulary.Vocabulary('ukbenchtest')
voc.train(featlist, 1000, 10)
#保存词汇
# saving vocabulary
with open('first1000/vocabulary.pkl', 'wb') as f:
pickle.dump(voc, f)
print ('vocabulary is:', voc.name, voc.nbr_words)
2、查询图片
reranking.py
# -*- coding: utf-8 -*-
import pickle
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
# load image list and vocabulary
#载入图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#载入特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#载入词汇
with open('first1000/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
src = imagesearch.Searcher('testImaAdd.db',voc)
# index of query image and number of results to return
#查询图像索引和查询返回的图像数
q_ind = 0
nbr_results = 20
# regular query
# 常规查询(按欧式距离对结果排序)
res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]
print ('top matches (regular):', res_reg)
# load image features for query image
#载入查询图像特征
q_locs,q_descr = sift.read_features_from_file(featlist[q_ind])
fp = homography.make_homog(q_locs[:,:2].T)
# RANSAC model for homography fitting
#用单应性进行拟合建立RANSAC模型
model = homography.RansacModel()
rank = {}
# load image features for result
#载入候选图像的特征
for ndx in res_reg[1:]:
locs,descr = sift.read_features_from_file(featlist[ndx]) # because 'ndx' is a rowid of the DB that starts at 1
# get matches
matches = sift.match(q_descr,descr)
ind = matches.nonzero()[0]
ind2 = matches[ind]
tp = homography.make_homog(locs[:,:2].T)
# compute homography, count inliers. if not enough matches return empty list
try:
H,inliers = homography.H_from_ransac(fp[:,ind],tp[:,ind2],model,match_theshold=4)
except:
inliers = []
# store inlier count
rank[ndx] = len(inliers)
# sort dictionary to get the most inliers first
sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]]+[s[0] for s in sorted_rank]
print ('top matches (homography):', res_geom)
# 显示查询结果
imagesearch.plot_results(src,res_reg[:8]) #常规查询
imagesearch.plot_results(src,res_geom[:8]) #重排后的结果
运行结果:
![]()
常规查询结果:

RANSAC模型查询结果:

test_candidates.py
# -*- coding: utf-8 -*-
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
from sqlite3 import dbapi2 as sqlite
from PCV.tools.imtools import get_imlist
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#载入词汇
f = open('first1000/vocabulary.pkl', 'rb')
voc = pickle.load(f)
f.close()
src = imagesearch.Searcher('testImaAdd.db',voc)
locs,descr = sift.read_features_from_file(featlist[0])
iw = voc.project(descr)
print ('ask using a histogram...')
print (src.candidates_from_histogram(iw)[:10])
src = imagesearch.Searcher('testImaAdd.db',voc)
print ('try a query...')
nbr_results = 12
res = [w[1] for w in src.query(imlist[0])[:nbr_results]]
imagesearch.plot_results(src,res)
运行结果:
输入图片:

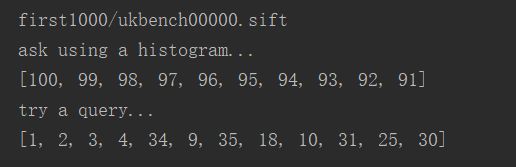
检索到的结果:

随机选取三张图片:


分析:
我们可以看到,与输入图片的拍摄位置(都在地毯上),纹理相近,形状相似(都是书,不同角度),颜色相近。
证明视觉词汇可能主要是从这三个方面进行匹配。